数据类型:String hash list 无序set 有序set
常用命令:
String
set a b
get a
getset 先获取旧值再设置新值
del a
一个键最多能存512MB
Hash
hset hash1 username ym
hget hash1 username
hmset hash2 username ym password ym age 18
hgetall hash2
hincrby hash1 age 20 某一字段增加某数值 仅对正确数据类型有效
hexists hash1 username
hlen hash1
hkeys hash1 展示该hash所有的key
hvals hash1 展示该hash左右的value
List
lpush lpush list1 1 2 3 4 结果 list1 [4,3,2,1]
rpush rpush list2 1 2 3 4 结果 list2 [1,2,3,4]
lrange list2 0 -1 0代表list的第一个元素 -1 代表最后一个元素 -2 代表倒数第二个元素
linsert list2 before|after b bbb 向b的前面或后面添加bbb
rpoplpush list1 list2 将list1的最右侧元素挪到list2作为最左侧元素 适用于多个执行队列
rpoplpush list1 list1 将list1的最右侧元素挪到list1的最左侧 适用于单个循环队列
无序Set 无序、不重复。 涉及两个大数据的交集,并集,差集的计算
sadd set1 a b c d
srem set1 b c
smembers set1 取出set1中所有元素
sismember set1 b 判断b在set1中是否存在 存在返回1 不存在返回0
set1 [a c d]
set2 [1 2 3 a b c e]
差集:查看哪些元素属于set1不属于set2
sdiff set1 set2 结果 d set1与set2 顺序有限制
交集:查看哪些元素既属于set1也属于set2
sinter set1 set2 结果 a c set1与set2顺序无限制
并集:set1与set2的并集
sunion set1 set2 结果 1 2 3 a b c d e set1与set2顺序无限制 去除了重复部分
将求出的交集、并集、差集存储到另外一个set集合中
sdiffstore set3 set1 set2 顺序有限制 sdiffstore紧跟的为存储结果集合
scard set1 结果3 返回set中结果个数
srandmember set1 随机返回一个set1中 元素 抽奖!!
有序Set 有序、不重复。 排行榜!
zadd zet 100 xiaoming 200 xiaohong 300 xiaozhang 插入 默认升序排列
zscore zet xiaohong 获取某元素的值 结果200
zcard zet
zrem zet xiaohong xiaoming
范围查询
zrange zet 0 -1
zrange zet 0 -1 withscores 带分数 升序
zrevrange zet 0 -1 withscores 带分数 降序 排行榜
zremrangebyrank zet 0 1 按照排名删除前两名 按照索引删除
zremrangebyscore zet 199 299 按照分数删除分数在199到299之间的元素 前后都是闭区间
zrangebyscore zet 100 350 withscore limit 0 2 按照分数排序 展示100到250区间内从第1条开始展示2条
zrevrangebyscore zet 650 100 withscores limit 0 1 降序的时候分数区间顺序也要倒着写
zincrby zet 400 xiaohong 增加某元素值
zcount zet 100 300 计算100到300元素个数
zrank zet xiaohong 查询元素下标 结果 2
zrevrank zet xiaohong 倒序查询
通用命令
通配符 *表示任意一个或多个字符 ?表示任意一个字符
匹配任意长度为4位的key
keys ????
匹配key中包含set的key
keys *set*
keys * 展示redis中所有的key
del 删除
exists 是否存在
rename为key进行重命名
rename 旧名字 新名字
type key 获取key的值类型 有序set返回zset
设置key的生存时间 单位秒
若某个key过期了 那么redis就会将其删除
默认为永久存在
expire key 30 设置key生存时间30s
ttl key 查询key的剩余生存时间 若返回-2 则为过期 若返回-1 则为永久存在
消息订阅与发布
发布消息
publish ym1 aaa
订阅单个频道
subscribe 如subscribe ym1
批量订阅多个频道
psubscribe 如psubscribe ym*
Redis多数据库
Redis默认有16个数据库 分别为0 1 2 3......15
在redis上所做的所有数据操作,默认都是在0号数据库上面操作
数据库之间不能共享键值对
切换数据库 select 数据库名 如select 1
把某个键值对进行数据库移植 move 移植的键 新数据库名 如move password 1
清空当前数据库数据:flushdb
清空服务器数据:flushall
Redis事务-批量操作
目的:进行redis语句批量化执行
Redis执行事务的时候,不对外服务。
multi 标记事务的开始 其后执行的命令都会被存入任务队列在执行exec时按顺序执行
exec 执行批量化 执行后就立即退出multi
diacard 不执行批量化 执行后就立即退出multi
Redis持久化
默认情况下:Redis所有的增删改 数据都是在内存中进行操作 断电后 内存中的数据会丢失
持久化策略:
RDB:默认持久化策略
RDB相当于照快照,保存的是一种状态
优点:
- 快照保存数据速度极快,还原数据速度极快
- 适用于灾难备份
缺点:
- 小内存机器不适合使用,RDB机制符合要求就会照快照(随时随地启动,会占用一部分系统资源,突然占用,很可能内存不足直接宕机,宕机后服务器关闭---非正常关闭,内存中数据丢失) 服务器关闭---照快照 key满足一定要求---照快照
RDB何时进行快照
- 服务器正常关闭
- key满足一定条件
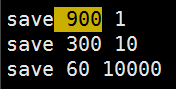
save 900 1 每900秒(15分钟)至少有一个key发生变化 则照快照
save 300 10 每300秒(5分钟)至少有10个key发生变化 则照快照
save 60 10000 每60秒(1分钟)至少有10000个key发生变化 则照快照
例如1:12:00-12:15 一个key发生变化,在12:15照快照
12:00-12:15 任何key没有发生变化,在12:15不照快照
例如2:12:00-12:05 11个key发生变化 在12:05照快照 在12:15照快照
12:00-12:05 9个key发生变化 在12:05不照快照 在12:15照快照
例如2:12:00-12:01 11000个key发生变化 在12:01照快照 在12:05照快照 在12:15照快照
12:00-12:01 9000个key发生变化 在12:01不照快照 在12:05照快照 在12:15照快照
AOF:使用日志功能保存数据操作 默认AOF关闭
适用于内存比较小的计算机
三种策略:
每秒同步:每秒进行一次AOF保存数据 安全性低,节省系统资源
每修改同步:只要有key变化,就进行AOF保存数据 比较安全,但是浪费效率
不同步(默认) 不安全
AOF操作:只会保存导致key变化的语句(增删改)
AOF配置:
everysec(默认):每秒同步
always:每修改同步
no:不同步
编辑redis.conf


优点:
- 持续性占用极少量的内存资源
缺点:
- 日志文件会特别大,不适用于灾难恢复
- 恢复效率远远低于RDB