一.具体介绍
Hadoop是Apache基金会发布的一款分布式开源软件框架。Hadoop通过三个方面高效地解决大数据存储与管理问题:
- 它使用分布式文件系统HDFS(Hadoop Distributed File System)来提高读写速度和扩大存储容量。
- 它采用MapReduce计算框架,将数据分发到分布式文件系统中进行处理,然后再进行数据整合,显著增强了数据处理能力。
- 它将数据冗余存储,保证了数据的可靠性。
总结来讲,使用Hadoop框架存储和管理数据具有四个优点:高可靠性、高扩展性、高效性和高容错性。
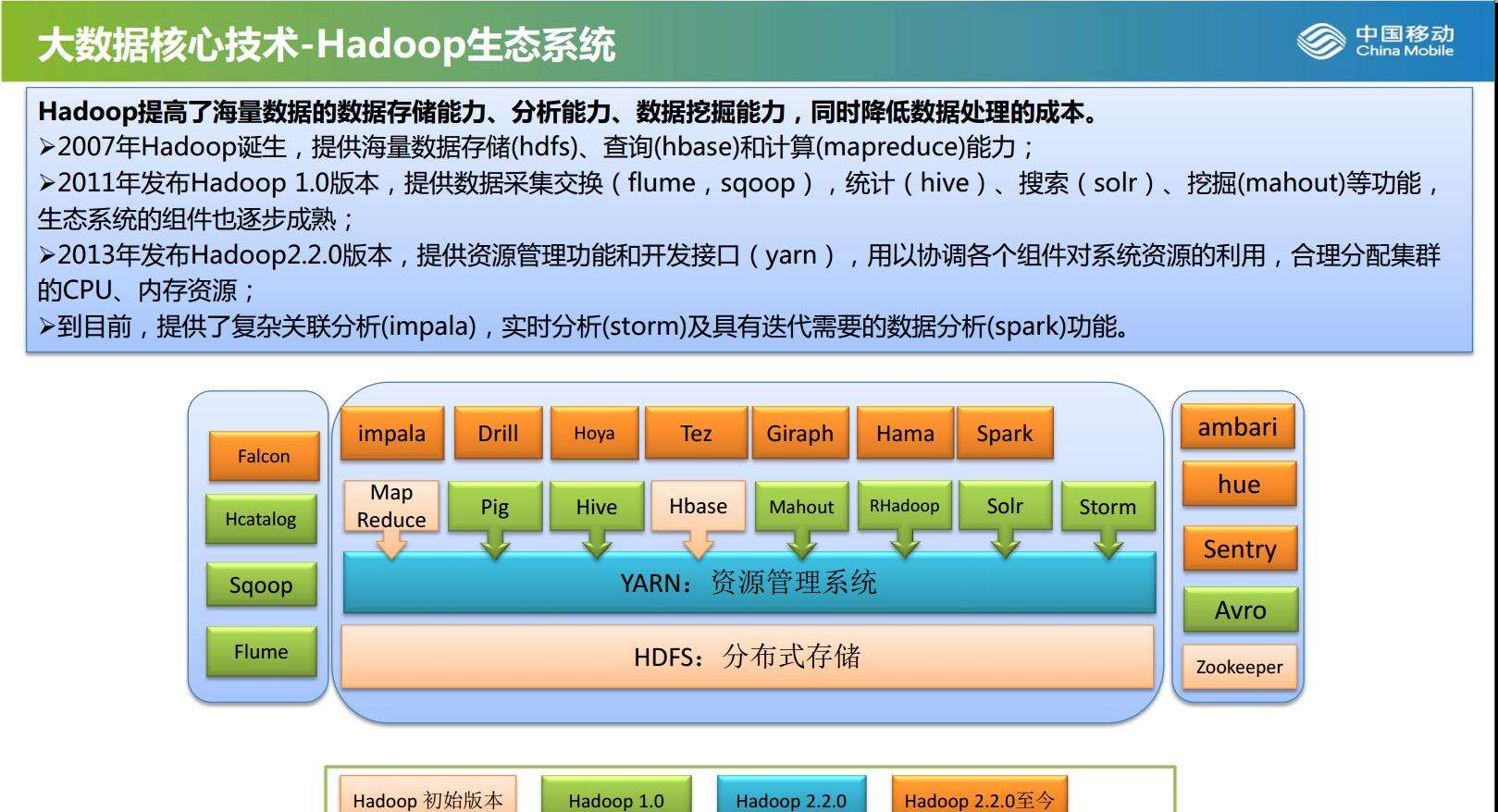
经过多年的发展,Hadoop框架在Mapreduce和HDFS为核心的基础上,又集成了很多子项目,包含:Hive、Avro、Hbase、Zookeeper等。这些子项目为Hadoop提供了互补性服务,同时也推动了Hadoop的产业化进程。
二.Hadoop各组件的简单介绍
- Hive
是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 - HBase
是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。 - Pig
是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。 - Zookeeper
是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。 - Sqoop
是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 - Mahout
是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。 - Avro
是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。 - Ambari
是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。 - Flume
是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输。 - Chukwa
是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。 - Hama
是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。 - Giraph
是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。 - Oozie
是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。 - Crunch
是基于Google的FlumeJava库编写的Java库,用于创建MapReduce程序。与Hive,Pig类似,Crunch提供了用于实现如连接数据、执行聚合和排序记录等常见任务的模式库。 - Whirr
是一套运行于云服务的类库(包括Hadoop),可提供高度的互补性。Whirr学支持Amazon EC2和Rackspace的服务。 - Bigtop
是一个对Hadoop及其周边生态进行打包,分发和测试的工具。 - HCatalog
是基于Hadoop的数据表和存储管理,实现中央的元数据和模式管理,跨越Hadoop和RDBMS,利用Pig和Hive提供关系视图。 - Hue
是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。 - Cassandra
是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身。 - YARN
新一代的Hadoop数据处理框架 - impala
Impala是Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。