目录
介绍
- 什么是分布式系统
- 为什么需要分布式系统
- 数据库伸缩(scaling)例子
分布式系统的类别
- 分布式数据存储
- 分布式计算
- 分布式文件系统
- 分布式消息
- 分布式应用程序
- 分布式分类账
总结
介绍
随着技术在各行业的日益扩张,分布式系统变的越来越普遍,这在计算机科学中是一个广阔而复杂的学习领域。
这篇文章旨在给你介绍一下分布式系统的基础,让你看一下分布式系统的不同的类别。本文不会深入细节。
1. 什么是分布式系统
用最简单的方式定义,分布式系统就是让终端用户把一组工作在一起的计算机当做一个单独的机器来使用。
这些机器共享状态,并发操作,并且单个机器出现问题不会影响到整个系统的正常工作。
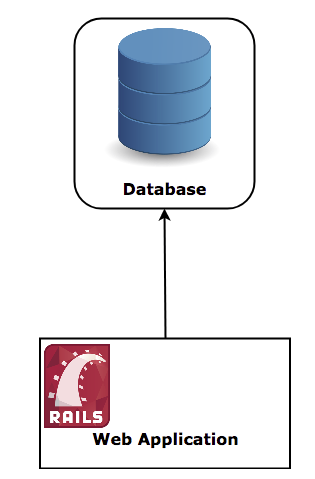
我打算用一个渐进式的例子来介绍分布式,这样你会有更直观的感受:让我们以数据库为例。传统的数据库存储在单一机器的文件系统中,无论你什么时候获取或插入数据,你都需要直接访问这个机器。传统数据库如图:
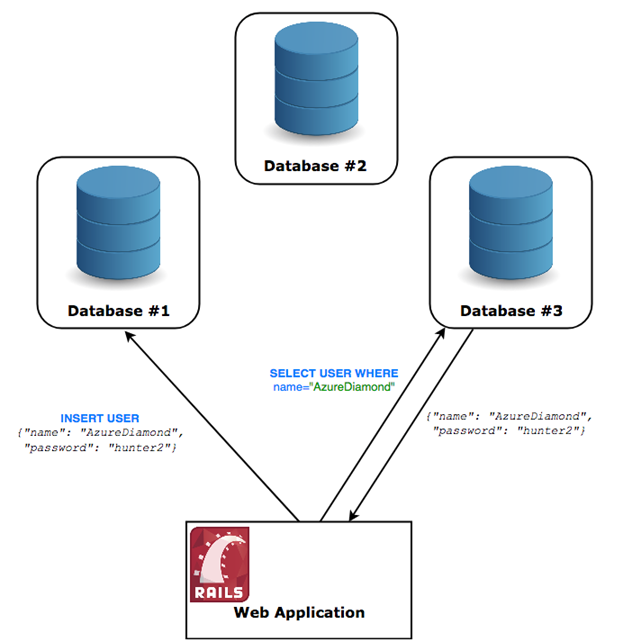
如果我们要把这个数据库变为分布式的,我们需要让这个数据库同时运行在不同的机器上。用户必须能够和他选取的任何一个机器进行会话,并且用户不应该知道他其实并不是在和一个单独的机器进行会话—如果用户插入一条记录到节点1,那么节点3也必须能返回此记录。分布式数据库:
2. 为什么需要分布式系统
使用分布式系统往往是不可避免的。现实的情况的是—分布式系统的管理是非常复杂,其中布满了各种坑和雷。部署,维护和调试分布式系统非常让人头疼,那为什么还要用它呢?
分布式系统让你获得的是水平伸缩性(扩展性)。回到前面单个数据库服务器的例子,提升数据访问能力的唯一方法就是提升数据库服务器硬件的性能。这被称为垂直伸缩(扩展)。
如果可以的话,垂直伸缩挺好的。但是从某个点开始你将会发现,即时是用最好的硬件,也满足不了访问的需要,且不说让主机使用最好的硬件是不是切合实际。
简单的说,水平伸缩的意思是增加更多的计算机而不是升级单个计算机的硬件。
当达到某个临界点以后,这要比垂直伸缩便宜的多。然而这并不是分布式的主要应用场合。
垂直伸缩可以使性能一下子猛增到最新的硬件能达到的水平。已经被证明,硬件的能力满足不了技术公司对于中到大规模的负载的需要。
水平伸缩最好的一点是没有伸缩的上限—无论什么时候性能下降了,你都可以通过简单的添加机器(可以添加无数台)来解决。
容易获得的伸缩性并不是分布式系统唯一的好处。容错和低延时也同等的重要。
容错—一个横跨两个数据中心由十台机器组成的集群自然比单一机器的容错性更强。即使一个数据中心着火了,你的程序还能工作。
低延时—一个网络数据包在世界范围内的传输速度是有光速限制的。比如,一个请求从纽约到悉尼,在光纤中可能的最短的往返时间(从发出请求到请求返回)是160毫秒。分布式系统允许在两个城市各有一个节点,请求者可以访问最近的节点。
然而,为了使分布式系统能正常的工作,你需要专门设计运行在那些机器上的软件,以使得它们
可以同时运行在多台机器上并且可以应对随之而来的各种问题。事实证明,这很难。
3. 伸缩我们的数据库
设想一下,我们的网站非常的流行了,我们的数据库开始需要在每秒钟处理两倍于它能力的请求。你的网站性能开始变差了,用户也感受到了。
让我们一块儿来使我们的数据库满足更高的要求。
在一个典型的Web应用中,一般来说,读取数据比插入和修改数据要频繁的多。
有一种方式可以提高读的性能,那就是所谓的“主从式复制”(Master-Slave Replication)策略。这里你创建两个新的数据库服务器,它们从主数据库同步数据。注意:对于这两个新的实例,你只读取数据。
无论你什么时候插入和修改数据,都在主数据库进行。而主数据库将会异步的通知从数据库来保存这些数据的更改。
恭喜!现在对于读取数据,性能已经是原来的三倍了。是不是很爽?
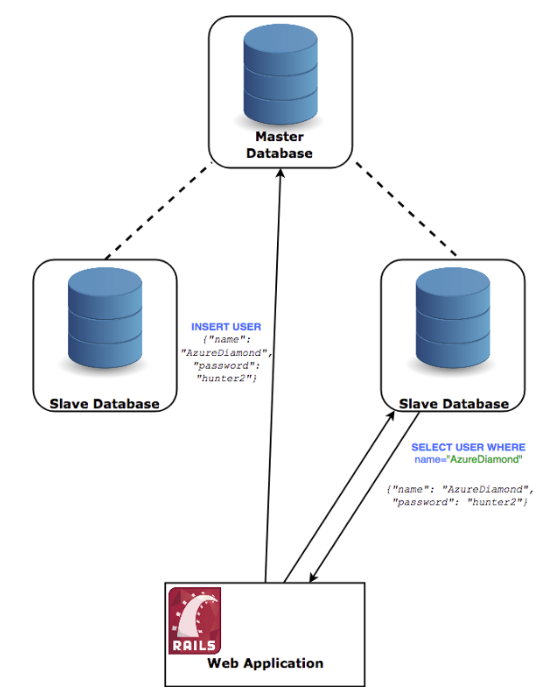
缺陷
Duang!我们立刻失去了关系型数据库中ACID中的C (Consistency),也就是一致性。
你看,现在存在了如下的可能性:我们插入一条记录到数据库,然后立刻发起一个读取此记录的请求,但是没有结果返回,就像这条记录不存在一样。
插入新的数据到主数据库和同步新数据到从数据库并不是同时完成的。这样就会存在有可能读取到旧数据的时间窗口。如果不想这样的话,那么写操作就得等新数据被同步到所有的从数据库以后才算完成,这样写的性能就会很差。
分布式系统中存在很多平衡和取舍。如果你想适当的进行伸缩,上面的问题是你不得不面对的。
继续扩展
通过主-从数据库的方式,我们可以把读的能力扩展到一定的程度。这很好,但是我们还没有解决对于写的问题—写还是通过单一的服务器进行的。
这里我们并没有太多的选择。很简单,由于一个机器不够,我们需要把写的请求分发到多个服务器上。
一种方式是“多主复制”策略。不同于只能读取数据的“从数据库”,你拥有多个“主节点”,主节点既可以读又可以写。很不幸,你很快会发现情况变的非常复杂,因为你会制造出冲突(比如:插入两条具有相同ID的记录)。
让我们尝试一下另一种称作“分片”(Sharding)方式,也称作“分区”(Partition)。
我们把服务器分成多个小的服务器,每个服务器称作一个分片。这些分片分别存储不同的记录—我们通过创建一套规则来决定哪些记录去到哪个服务器。这套规则非常重要,它保证了数据以一致的方式分布在分片上。
一种可行规则是基于数据记录的某种信息来定义区间范围(比如,用户记录以用户名的首字母A-D)。如图:
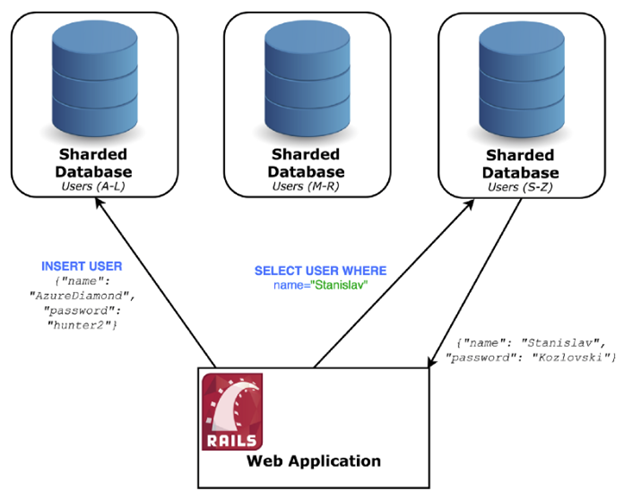
选择用来分片的键(比如上面例字中用户名的首字母)需要非常的慎重,因为键在数据记录中的分布可能非常的不平均(比如,名字首字母为C的用户可能比为Z的要多很多)。某个分片如果收到的请求比其他的分片多很多,那么它被称作“热点”,这是要必须避免的。一旦分片完成,重新分片的代价是非常昂贵的并且可能会造成长时间的宕机。
为了使我们的例子简单,假设我们的用户知道在哪个分片上存储一条记录。注意一下,其实有非常多的分片策略,这个例子只是以一种简单的方式解释分片的概念。
现在我们更进了一步—我们把写的性能提升到了原来的N倍,这里N是分片的个数。性能提升几乎没有上限了—可以想象一下这种分片的方式可以做到多么细的粒度。
缺陷
软件工程中所有方面都或多或少的会涉及到平衡取舍,这里也不例外。分片不是一件容易的事情,除非必要,否则最好不要用。
我们查询数据的时候使用的是记录的键(比如用户表中的用户名)而不是使用用来做分片的键(比如用户名的首字母),查询效率会非常的低,因为查询需要覆盖到所有的分片。SQL的JOIN查询会变的更复杂,效率也更低,变的几乎不能用了。
去中心化和分布式
在深入讨论之前,我想先对这两个词区分一下。
虽然这两个词看起来很相似并且从逻辑的角度讲是一回事儿,但是他们的区别对技术和运营会产生重大的影响。
从技术角度讲去中心化依然是分布式系统,但是整个去中心化的系统并不是被单一的参与者所拥有。没有一个公司可以拥有一个去中心化的系统,否则就不能称作去中心化了。
这意味着我们接下来讨论到的系统可以被认为是“分布式的中心化系统”—它们也正是照此设计的。
如果仔细想一下,你会发现创建一个去中心化的系统要更困难一些,因为你需要应对恶意的参与者。对于普通的分布式系统,你不需要应对这种情况,因为你知道你拥有所有参与的节点。
注意:去中心化和分布式的定义有很多的争议,并且还可能和其他的定义产生混淆(比如P2P)。在早期的论文中,它们的定义也是不同的。不管怎么样,我给出的定义是我认为被最广泛采纳的。当下,区块链和加密货币让这些名词变的非常流行。
下一篇将会讨论分布式系统的类别。
作者公众号(码年)扫码关注:

英文原文:
https://hackernoon.com/a-thorough-introduction-to-distributed-systems-3b91562c9b3c