ScheduledThreadPoolExecutor
提交的任务按照执行的时间排序放入到 DelayQueue 队列中。
- DelayQueue内部封装了一个PriorityQueue,它会根据time的先后时间排序(time小的排在前面),若time相同则根据sequenceNumber排序( sequenceNumber小的排在前面);
- DelayQueue也是一个无界队列;
ScheduledThreadPoolExecutor 定时线程池类的类结构图
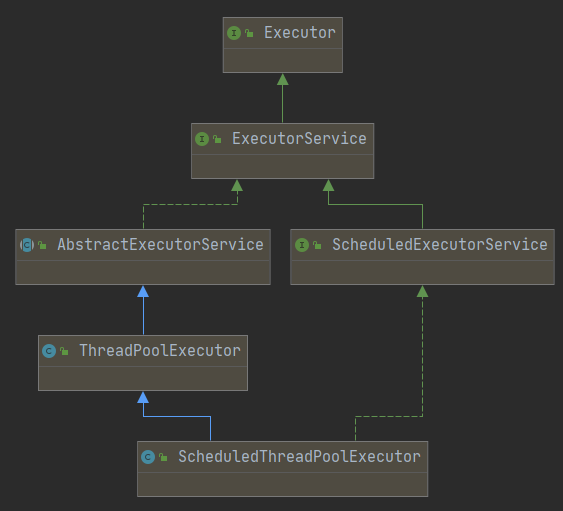
SchedualedThreadPoolExecutor 接收SchduledFutureTask类型的任务,是线程池调度任务的最小单位,有三种提交任务的方式:
- schedule:延迟多长时间之后只执行一次;
- scheduledAtFixedRate:延迟指定时间后执行一次,之后按照固定的时长周期执行;
- scheduledWithFixedDelay:延迟指定时间后执行一次,之后按照:上一次任务执行时长 + 周期的时长 的时间去周期执行;
public static void main(String[] args) {
ScheduledExecutorService pool = Executors.newScheduledThreadPool(5);
pool.schedule(new Runnable() {
@Override
public void run() {
System.out.println("延迟执行");
}
},1, TimeUnit.SECONDS);
/**
* 这个执行周期是固定,不管任务执行多长时间,还是每过3秒中就会产生一个新的任务
*/
pool.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
//这个业务逻辑需要很长的时间,定时任务去统计一张数据上亿的表,财务财务信息,需要30min
System.out.println("重复执行1");
}
},1,3,TimeUnit.SECONDS);
/**
* 假设12点整执行第一次任务12:00,执行一次任务需要30min,下一次任务 12:30 + 3s 开始执行
*/
pool.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
//30min
try {
Thread.sleep(60000 * 30);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("" + new Date() +"重复执行2");
}
},1, 3, TimeUnit.SECONDS);
}
任务提交到线程池中,任务排序的 siftUp 方法
private void siftUp(int k, RunnableScheduledFuture<?> key) {
// 找到父节点的索引
while (k > 0) {
// 获取父节点
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
// 如果key节点的执行时间大于父节点的执行时间,不需要再排序了
if (key.compareTo(e) >= 0)
break;
// 如果key.compareTo(e) < 0,说明key节点的执行时间小于父节点的执行时间,需要把父节点移到后面
queue[k] = e;
setIndex(e, k);
// 设置索引为k
k = parent;
}
// key设置为排序后的位置中
queue[k] = key;
setIndex(key, k);
}
循环的根据key节点与它的父节点来判断,如果key节点的执行时间小于父节点,则将两个节点交换,使执行时间靠前的节点排列在队列的前面。
可以理解为一个树形的结构,最小点堆的结构;父节点一定小于子节点;
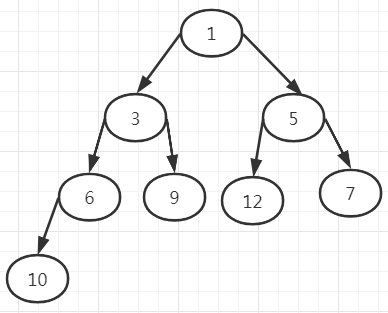
实际上所谓的排序并不是绝对的按照顺序大小去排的,只保证了队列最前端的最小。为什么要这样设计呢?
因为当队列中的数据过大的时候,要保证绝对的排序消耗是比较大的,而且我们没有必要去保证绝对排序,因为只需要保证队列头的数是最小的就可以了。
30min