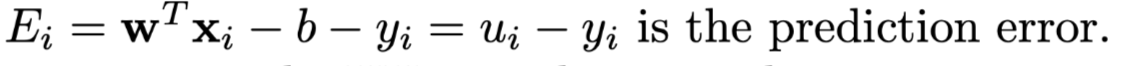refs:
Sequential Minimal Optimization for SVM - MITftp.ai.mit.edu › tlp › svm › svm-smo › smo
SVM by Sequential Minimal Optimization (SMO)pages.cs.wisc.edu › ~dpage › SMOlecture
This article is a friendly guide to SMO Squential Minima Optimization.
As we all know, SVM Support Vector Machine is about to get a hyperplane to divide the data into two sides. In order to get good performance, we want the max margin of the hyperplane with subject to correct classification.
The linear separating hyperplane classifier: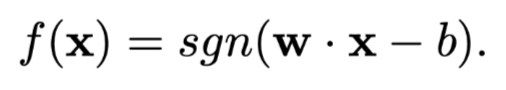
The hyperplane can be wirtten as H: y = w·x - b = 0 , and two hyperplanes parallel to it and with equal distances to it, H1 = w·x - b = +1, H2 = w·x - b = -1
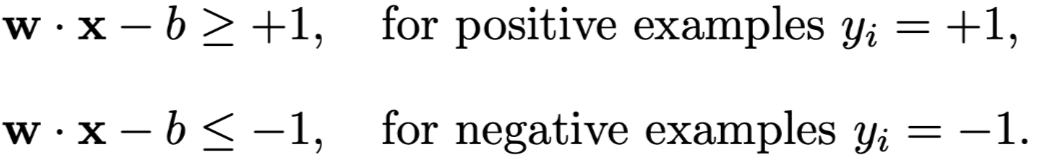

the first item is to maximize the margin distance, the second constraint is to insure the right classification.
So, we can use Lagrangian to slove it:

alpha is Lagrangian multiplier, alpha >= 0
So, next step is to calculate the partial derivatives of L(w, b, alpha), and let them equal to zero. cuz it's a quratic problem.

alpha>=0

Imperfect separation
Introduce non-negative slack variables ξ >= 0

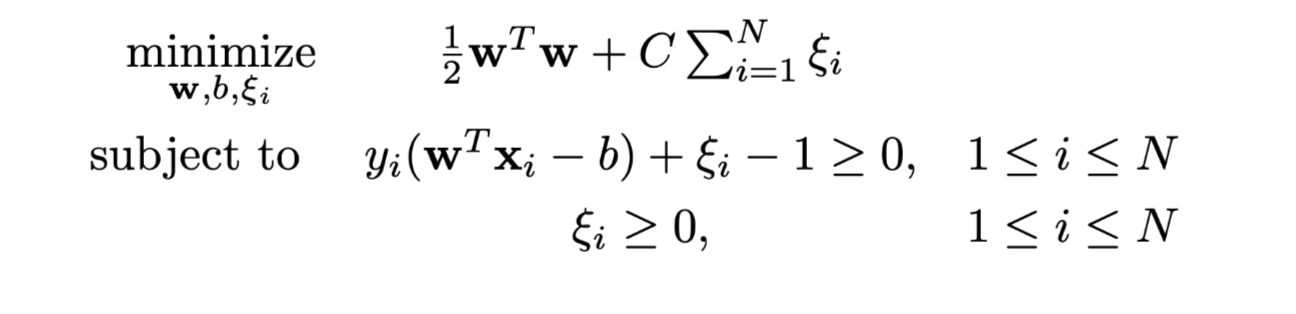

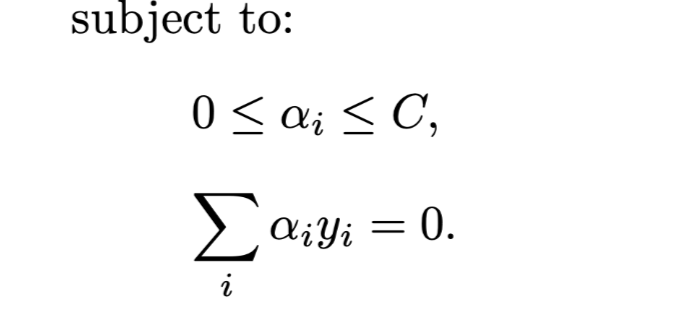
The only difference is the alpha is bounded above by C instand of infinite.
KKT conditions
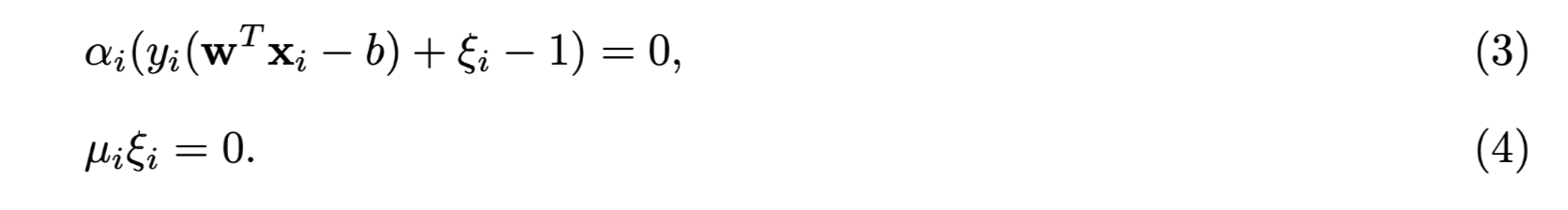
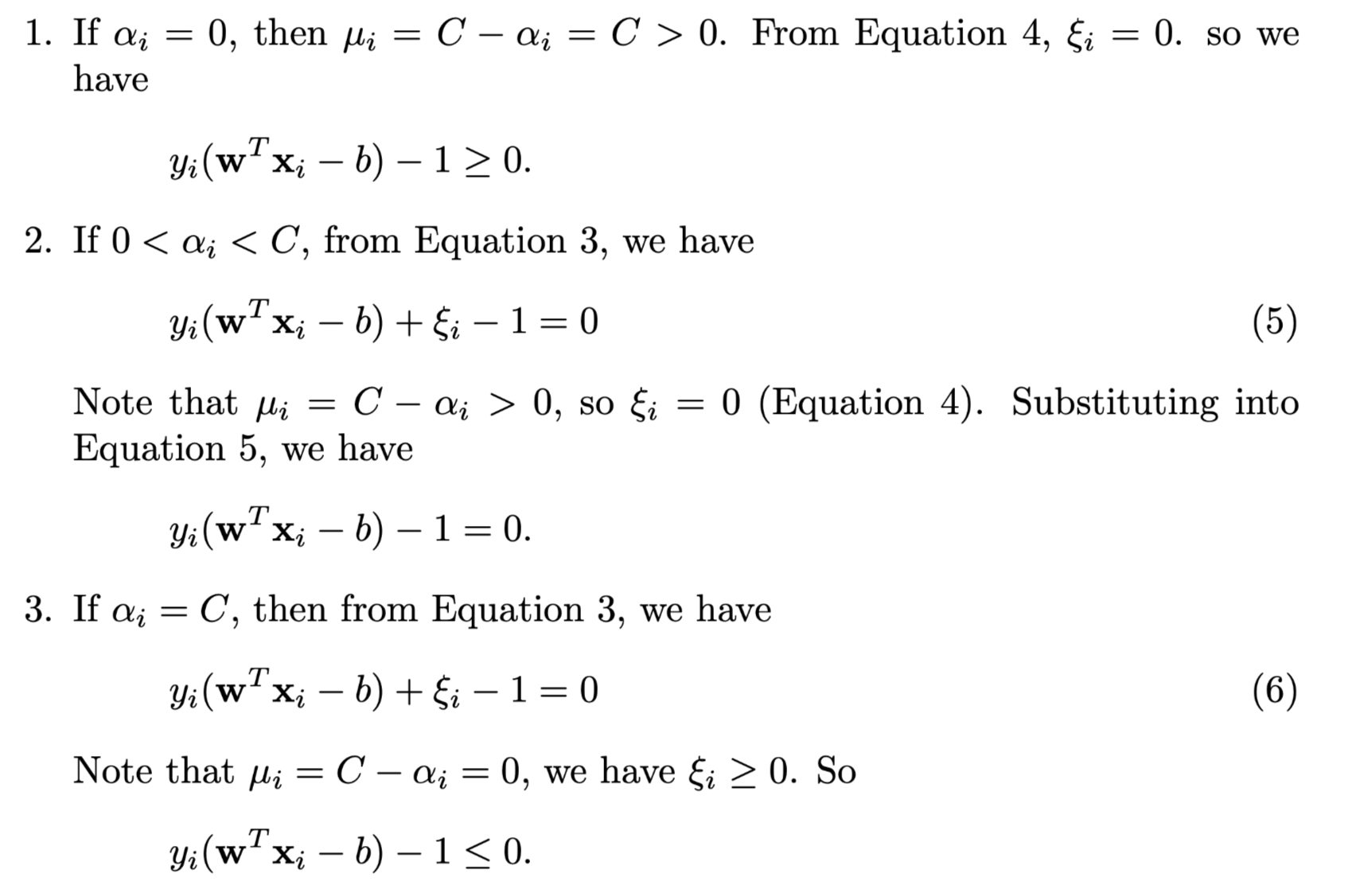

SMO Algorithm
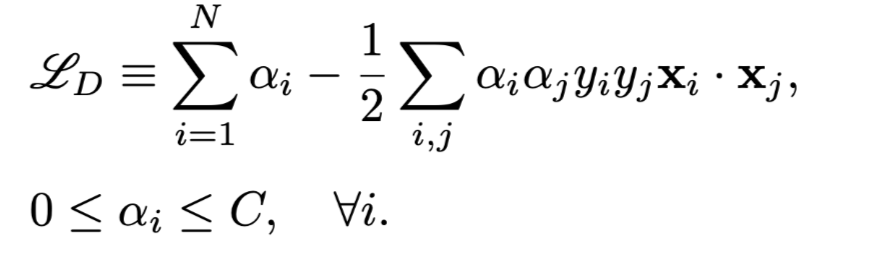
Optimize two alphas at a time, use heuristics to choose the two alphas for optimization.

where k(x1,x2) = x1T·x2, E is error item