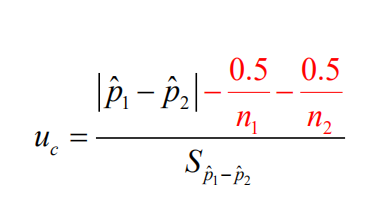第三章 假设检验
区间估计与假设检验的基本区别?
上一章中讨论了置信区间的估计方法。它是利用样本数据,以抽样总体的分布为理论基础,用一定的概率保证来计算出原总体中未知参数的区间范围。特别值得注意的是:在作区间估计之前,我们对所要估计的参数是一无所知的。
§ 而在这一章中,我们所要做的工作是,先对要研究的参数作一个假设,然后去检验这个假设是否正确。因此假设检验对于所研究的参数总是先有一个假设的值。
§ 这也是这两种方法最基本的区别。
显著水平(significance level)或概率水平(probability level)是什么?
置信度
如何解释“显著性”?
具有显著性:假设值与真实值之间有随机误差,也有真实误差。
不具有显著性:假设值与真实值之间只有随机误差,没有真实误差。
第一类错误是何含义?
理解一:真实情况是表面误差是随机误差的概率至少是(1-α)。真实情况是表面误差是真实误差和随机误差的概率不会超过α。真实情况是表面误差是真实误差和随机误差,而估计情况是表面误差是随机误差,所以估计错误,所以事件“真实情况是表面误差是真实误差和随机误差,而估计情况是表面误差是随机误差,所以估计错误”的概率不会超过α。即第一类错误。
理解二:假设检验已结束,其结果(显著或者不显著)可能出错的概率不会超过是α,不会出错的概率至少是(1-α)。
理解三:假阴性,原来是真的,却被判定是假的。
Ⅱ类错误、β错误是何含义?
理解一:以为估计出来的分布与原分布是一个分布,实际上是另一个分布的概率。
理解二:假阳性,原来是假的,却被认为是真的。
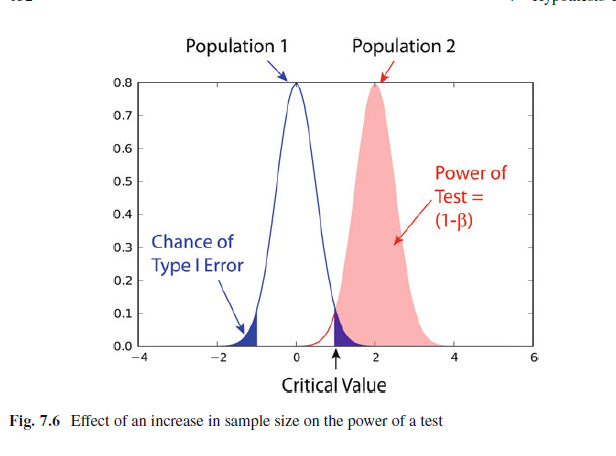
即如上图,你以为应该支持H1,即原分布是population1,但是其实真实情况是population2。因为population1中的点造成了这个错误,所以概率是population1中有population2的点。
单边假设检验的假设有何特点?
H0:相等
H1:小于|大于,不是小于或大于,是只有小于,或者只有大于

在样本平均数与总体平均数差异显著性检验中,实际过程中如何获知总体平均数?
已知的总体平均数μ一般为一些公认的理论数值、经验数值或期望数值。
什么是t检验法?
t 检验法,就是在显著性检验时利用 t分布进行概率计算的检验方法。
百分率数服从二项分布,在单值与总体检验的过程中需要注意有,在大样本上有连续性矫正的情况
当满足n足够大,p不过小,np>5或者nq<30的条件时,可近似地采用u检验法,就是有连续性矫正,即正态近似法来进行显著性检验;
若np和nq均大于30,不必对u进行连续性矫正。
这里的p、q是H0假设中的值
二项分布的假设检验的特殊之处在哪里?
二项分布是单因素p,所以只用假设p相同。
什么时候进行连续性矫正?
当满足n足够大,p不过小,np>5或者nq<30的条件时,可近似地采用u检验法,就是有连续性矫正,即正态近似法来进行显著性检验;
样本百分率与总体百分率差异显著性检验的连续性矫正是什么?

样本百分率与总体百分率差异显著性检验的连续性矫正是什么?