BeautifulSoup官方介绍文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
四大对象种类:
BeautifulSoup 将复杂的html文件转换成一个复杂的树形结松,每个节点都是python对象。
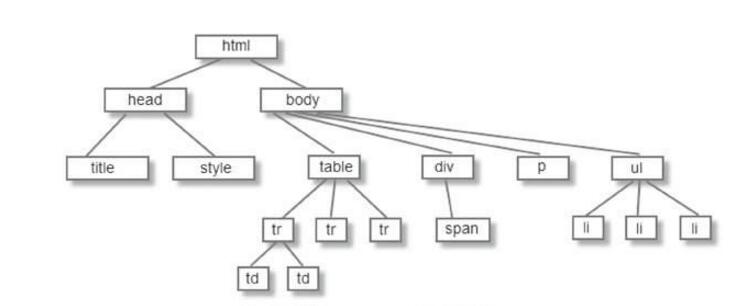
所有对象可以分下以下四类:
Tag
NavigableString
BeautifulSoup
Comment
下面进行一一介绍:
1、Tag
通俗点讲就是html中的一个个标签,例如:
<title>Hello world </title>
<a class ="test",href="http://www.baidu.com" id="link1"> Elsie </a>
上面的 title a 等等 HTML 标签加上里面包括的内容就是 Tag,下面我们来感受一下怎样用 Beautiful Soup 来方便地获取 Tags
下面每一段代码中注释部分为运行结果:
print soup.title
#<title>Hello world </title>
print soup.head
#<head><title>The Dormouse's story</title></head>
print soup.a
#<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print soup.p
#<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
我们可以利用 soup加标签名轻松地获取这些标签的内容,是不是感觉比正则表达式方便多了?
我们可以验证一下这些对象的类型:
print type(soup.a)
#<class 'bs4.element.Tag'>
对于tag,它有两个重要的属性,是name和attrs
name:
print soup.name
print soup.head.name
#[document]
2、NaviableString
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可
print soup.p.string
#The Dormouse's story
检查一下它的类型
print type(soup.p.string)
#<class 'bs4.element.NavigableString'>
3、BeautifulSoup
对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性来感受一下
print type(soup.name)
#<type 'unicode'>
print soup.name
#[document]
print soup.attrs
#{} 空字典
4、Comment
对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
我们找一个带注释的标签
print soup.a
print soup.a.string
print type(soup.a.string)
结果如下:
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
Elsie
<class 'bs4.element.Comment'>
a 标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释符号去掉了,所以这可能会给我们带来不必要的麻烦。
另外我们打印输出下它的类型,发现它是一个 Comment 类型,所以,我们在使用前最好做一下判断,判断代码如下:
if type(soup.a.string)=="bs4.element.Comment":
print soup.a.string
上面的代码中,我们首先判断了它的类型,是否为 Comment 类型,然后再进行其他操作,如打印输出。
实例应用:
import requests
from bs4 import BeautifulSoup
url = "http://www.baidu.com"
html_doc = requests.get(url).content
soup = BeautifulSoup(html_doc,'lxml')
for link in soup.find_all('a'):
print (link.get_text()) #获取tag中的文本内容
print (link.get('href')) #获取tag的属性,用get("attr")