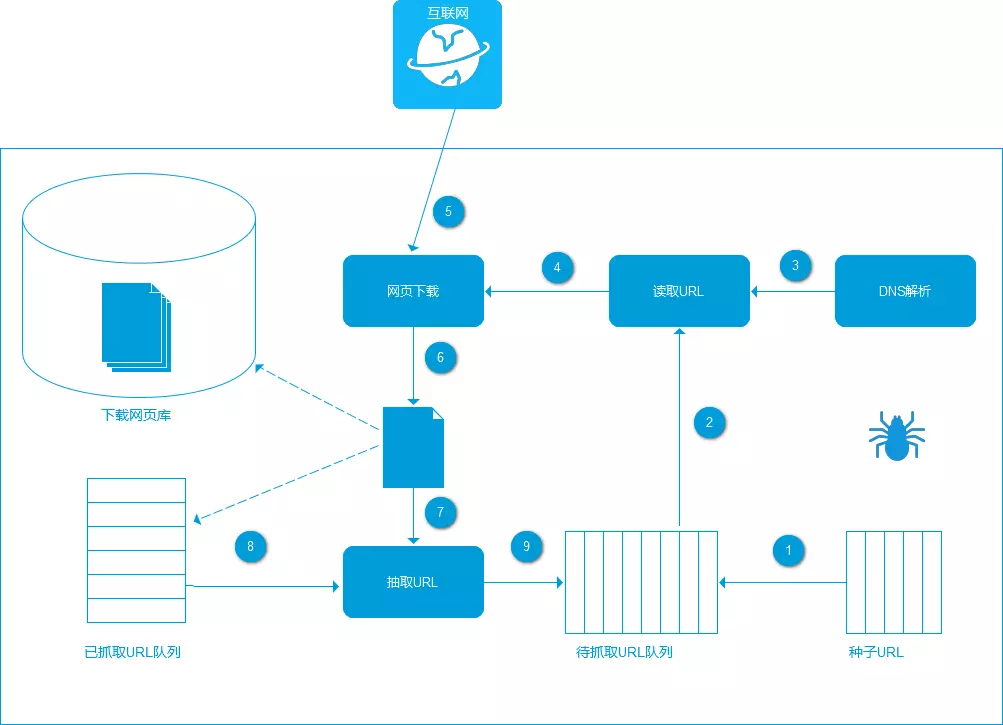
一、爬虫原理
1、模拟计算机对服务器发起Request请求
2、接收服务器端的Response内容并解析、提取所需的信息
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,
沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
https://www.cnblogs.com/sss4/p/7809821.html
二、爬虫架构