【INTERSPEECH 2019接收】
链接:https://arxiv.org/pdf/1904.03479.pdf
这篇文章在会议的speaker session中。本文主要讨论了说话人验证中的损失函数large margin softmax loss(结合了softmax和margins的losses)。
本文从x-vector中提取speaker embedding。
这篇文章在一个公式中统一了多种margin项:

其中N表示训练样本数目,C表示训练集中的说话人数目,s是尺度因子。m1, m2, m3是可以分开使用的margins,则角函数定义为:
![]()
并引入两种辅助损失:Ring Loss[1]来约束embedding模值;MHE[2]使weight尽可能在超球面中均匀分布,从而提升类间可分性。
在VoCeleb数据集上运行实验。训练集包括VoxCeleb1 dev part and VoxCeleb2,验证集为VoxCeleb1 test part。训练过程中,特征采用30维的MFCCs(经过谱均值归一化)。采用基于能量的VAD方法。
三种margins单独使用,分别得到losses为:angular softmax (ASoftmax), additive angular margin softmax (ArcSoftmax) and additive margin softmax loss (AMSoftmax)。见图1:
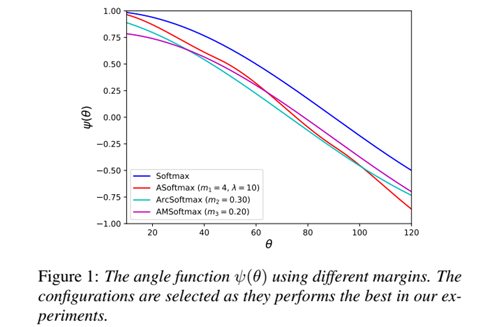
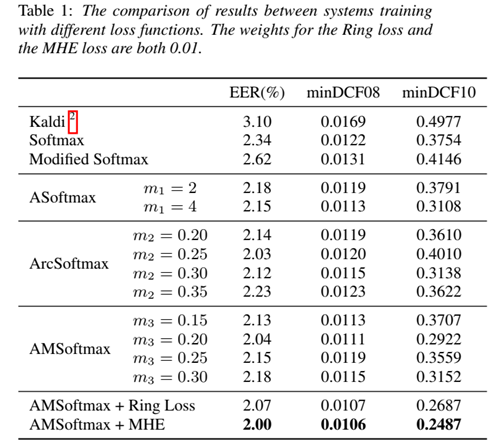
实验表明采用AMSoftmax的性能最佳。见表1,该研究在Kaldi recipe for VoxCeleb的基础上得到了EER 2%的显著性能提升:
深度学习为说话人技术带来了前所未有的机遇,而研究者们在不断拓展新算法的边界的同时,也在回顾传统方法仍然具备的价值。当然说话人技术目前也逐渐暴露出与人脸识别同样的易受攻击的问题。因此,ASVspoof这样的Challenge从2015年起就开始关注声纹反作弊问题。
[1] Ring loss,一种简单的深层网络特征归一化方法,用于增强诸如Softmax之类的标准损失函数。论文(Ring loss: Convex Feature Normalization for Face Recognition)被CVPR 2018接收。
[2] 最小化超球面能量准则(Minimum Hyperspherical Energy criterion),具体见论文Learning towards Minimum Hyperspherical Energy(NIPS 2018接收)。