在redis的安装目录下首先启动一个redis服务,使用默认的配置文件,作为主服务
ubuntu@slave1:~/redis2$ ./redis-server ./redis.conf &
在home目录下创建一个redis2 工作目录,拷贝redis配置文件到该目录下,并修改一下配置项
port 6380 pidfile /var/run/redis_6380 dir ~/redis2 slaveof 127.0.0.1 6379
使用以上的配置文件再启动一个redis服务,就是master的从服务了
ubuntu@slave1:~/redis2$ ~/redis-server/redis-4.0.1/redis-soft/bin/redis-server ./redis.conf &
再打开两个窗口分别连接这两个实例:
master:


127.0.0.1:6379> INFO replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=1737,lag=1 master_replid:92daad4418492783bb39ab32f5fee57d06eba455 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1737 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1737
ubuntu@slave1:~/redis-server/redis-4.0.1/redis-soft/bin$ ./redis-cli -p 6379 127.0.0.1:6379> set "test" "a value" OK
slave:
127.0.0.1:6380> INFO replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:9 master_sync_in_progress:0 slave_repl_offset:1709 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:92daad4418492783bb39ab32f5fee57d06eba455 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1709 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1709
ubuntu@slave1:~/redis-server/redis-4.0.1/redis-soft/bin$ ./redis-cli -p 6380 127.0.0.1:6380> get "test" "a value"
此时关闭slave,在操作master:
127.0.0.1:6379> set "test2" "another value" OK 127.0.0.1:6379> set "test" "new value" OK
再次连接slave,并读取数据
ubuntu@slave1:~/redis-server/redis-4.0.1/redis-soft/bin$ ./redis-cli -p 6380 127.0.0.1:6380> get "test" "new value" 127.0.0.1:6380> get "test2" "another value"
至此,主从复制配置并测试完毕。
相关原理:
我们在从节点的配置文件设置了从服务的监听端口是6380,并设置了 slave of 127.0.0.1 6379 。表示这个服务实例是master的一个从节点。当主从实例之间网络连接通畅并建立了主从复制关系之后,主实例会将其接受的写入命令转发给从实例,以实现主从实例之间的数据同步。
当从实例第一次与主实例连接时会发生什么?从实例在网络连接中断后会重新连接到主实例吗?
在redis的复制机制中,共有两种重新同步机制:部分重新同步和完全重新同步。当一个redis从实例启动后并连接到主实例时,从实例总是会尝试 通过发送(master_replid;master_repl_offest)请求主实例进行部分重新同步。其中master_replid;master_repl_offest 表示与主实例同步的最后一个快照。此时如果主实例接收部分同步的请求,那么它会从从实例停止时的最后一个偏移量开始增量的进行数据同步,否则的话,就要进行完全同步复制。当从实例第一次了解主实例时,总是完全同步复制的,在进行完全同步复制时,为了将所有的数据复制到从实例中,主实例需要将数据转存到一个RDB文件中,然后将这个RDB文件发送给从实例。从实例接收到RDB文件后,会将内存中的所有数据清除,再将RDB文件中的数据导入,主实例的复制过程是完全异步的,因此不会阻塞主实例处理客户端的请求。
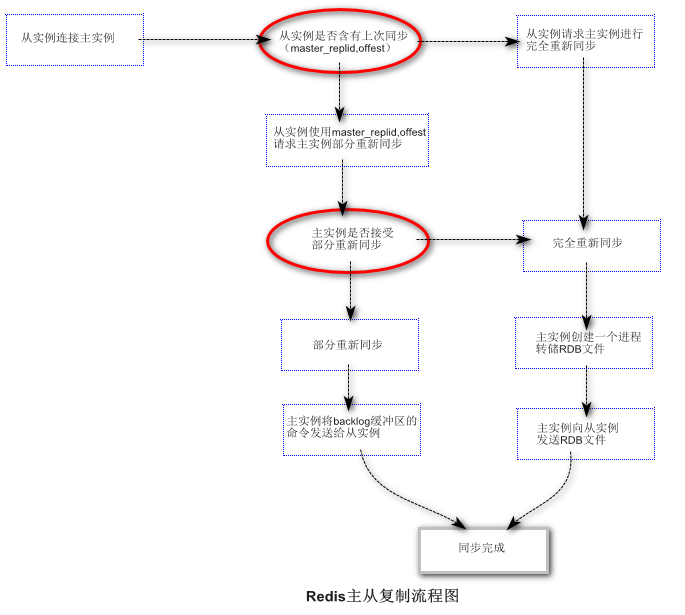
更多细节:当一个从实例被提升为主实例时,其他的从实例必须与新主实例重新同步。在Redis4之前,这个过程是完全重新同步的,在4.0 之后,新的主实例会记录旧主实例的master_replid,offest.因此可以接受来自其他从实例的部分重新同步请求。
复制机制调优(参数配置:)
repl_backlog_size (主从网络断开时,主实例缓冲区中缓存命令的大小,默认是1MB;当主从网络恢复时,如果异步数据超出这个范围,那么会触发完全同步,否则就是部分同步。)。关于这个值的配置,原则是该值小于RDB快照大小。参考的计算公式:
T * (mster_repl_offest2 - master_repl_offest1) / (T2 - T1)
-T 网络断开可能持续的时间
repl_backlog_ttl :如果所有的从实例与主实例的连接全部断开,主实例需要等待多久才释放缓存中的命令。
repl_disable_tcp_nodelay:设置为yes可以减少网络带宽。(将小包合并为一个包再发送)
repl_diskless_sync:主从复制不提供磁盘RDB文件直接发送。(实验阶段特性,不安全)
复制机制失效故障排查:
repl_ping_slave_period:从主实例的角度看,检查从实例是否存活的方式是在该参数的时间间隔内向从实例发送ping命令,默认是10秒。而从实例的角度,是每秒向主实例发送replconf ack{offest}来报告自己的复制偏移量。无论ping还是replconf ack,都是通过repl-timeout指定超时时间,默认是60秒,如果两次ping命令或者replconf ack之间的间隔时间超时了,或者repl-timeout期间主从实例没有数据流量,那么主从实例的复制连接就会断开,导致复制失效。
client-output-buffer-limit: slave 256MB 64MB 60 :当我们配置主从复制时,从实例第一次连接主实例,主实例会将命令转储到RDB文件中在发动给从实例,那么在从实例执行RDB文件中的命令同步数据时,主实例的实时写入命令是放在客户端缓冲区的,在从实例加载完RDB文件后,再将这些明命令发送给客户端。这个缓冲区的大小是有限制的,如果超出了这个限制,就会导致重新复制。256MB是硬性要求,一旦超出,立即关闭从实例的连接,64MB 60 是个整体的软性要求,意思是 缓冲区的大小超出64MB 持续60秒,主实例将关闭连接。
更多细节:repl_ping_slave_period的值必须小于repl_timeout的值,否则每次主实例之间没有流量就会造成复制超时。同时我们应该避免使用长时间阻塞的操作。
复制超时的触发条件:执行重新同步时主从实例之间没有数据传输,或者超时时间内主从实例无法接受ping/replconf ack .比如从实例加载RDB文件过长,导致实例写入命令在主实例缓冲区 超过64MB并持续60秒。在生产环境中我们可以使用命令: conf set 设置合适的值或者修改配置文件并重启redis:(一下设置意为:512MB硬性要求,128MB 持续120秒)
127.0.0.1:6379> CONFIG SET client-output-buffer-limit 'slave 536870912 134217728 120' OK
多说一句:主从配置中,最好将从实例设置为 read only;主实例删除键时会同步删除从实例;如果我们在从实例中设置了键的过期时间,那么这个键将永远不过期。但是redis4.0解决了这个问题。