随便找个快手主页练习一下:查看元素
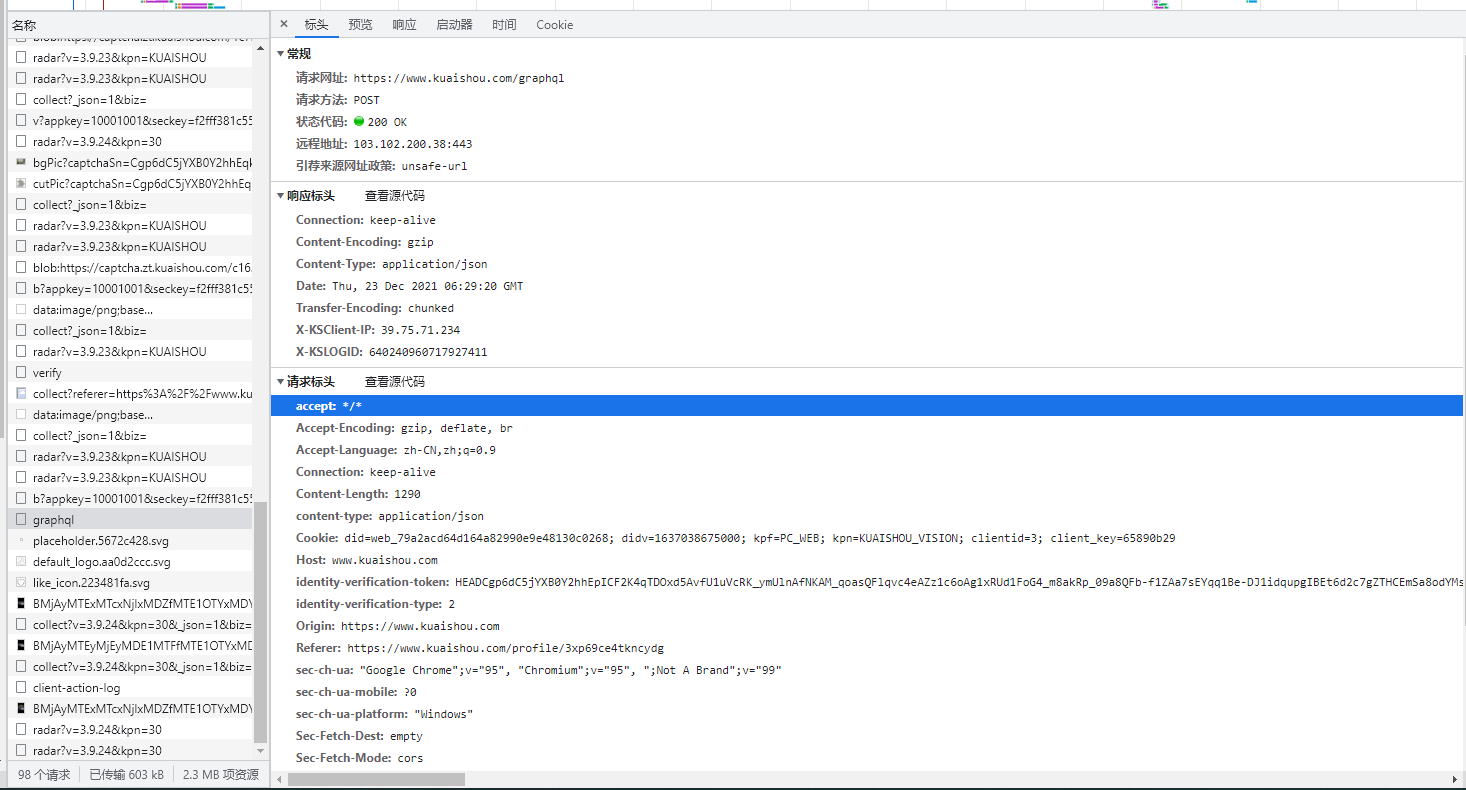
先用apipost 通过post方式测试一下接口是否能够跑通,然后点击右侧生成代码:
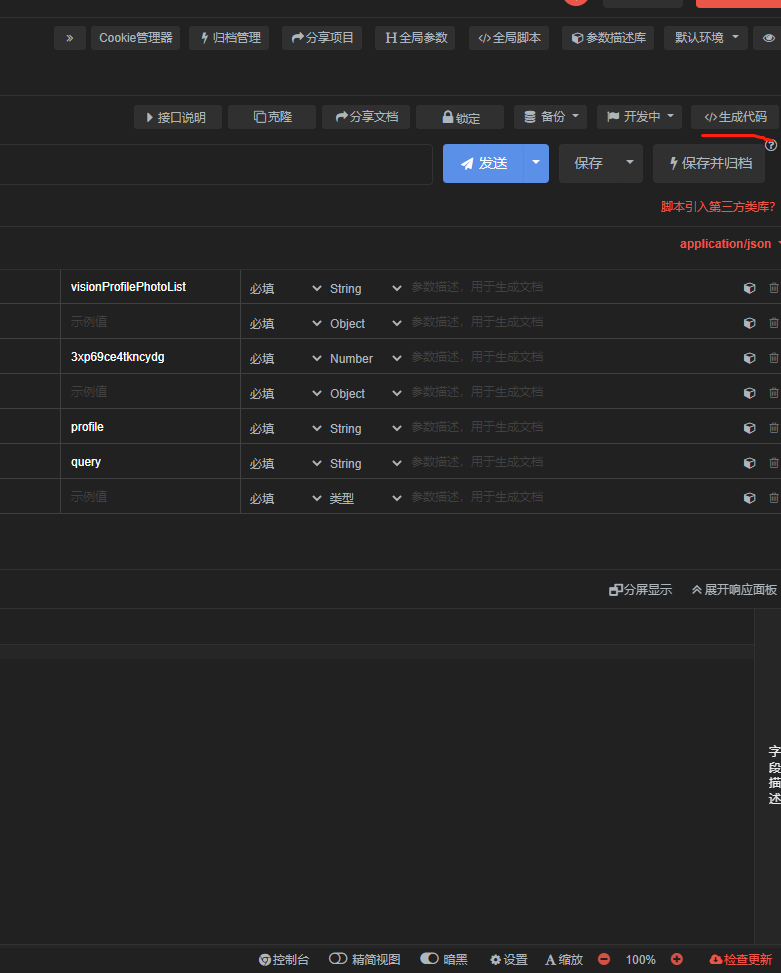
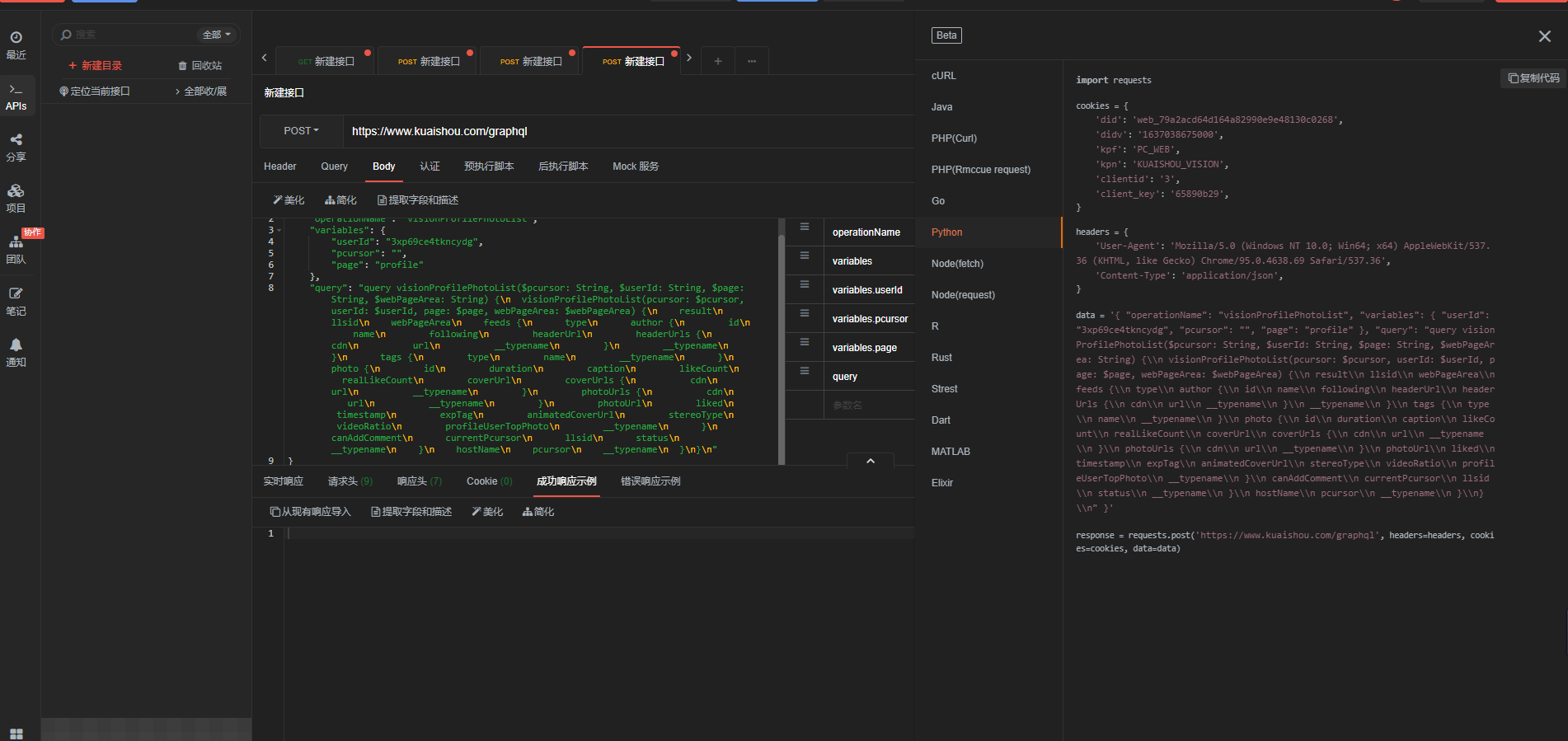
可以生成python curl请求接口的代码格式:
复制粘贴金编辑器里面:
from bs4 import BeautifulSoup #引用BeautifulSoup库 import requests #引用requests import os #os import pandas as pd import csv import codecs import re import xlwt #excel操作 import time import json from urllib import parse from selenium import webdriver # 视频的URL : Request URL: cookies = { 'did': 'web_79a2acd64d164a82990e9e48130c0268', 'didv': '1637038675000', 'kpf': 'PC_WEB', 'kpn': 'KUAISHOU_VISION', 'clientid': '3', 'client_key': '65890b29', } headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36', 'Content-Type': 'application/json', } data = '{ "operationName": "visionProfilePhotoList", "variables": { "userId": "3xp69ce4tkncydg", "pcursor": "", "page": "profile" }, "query": "query visionProfilePhotoList($pcursor: String, $userId: String, $page: String, $webPageArea: String) {\\n visionProfilePhotoList(pcursor: $pcursor, userId: $userId, page: $page, webPageArea: $webPageArea) {\\n result\\n llsid\\n webPageArea\\n feeds {\\n type\\n author {\\n id\\n name\\n following\\n headerUrl\\n headerUrls {\\n cdn\\n url\\n __typename\\n }\\n __typename\\n }\\n tags {\\n type\\n name\\n __typename\\n }\\n photo {\\n id\\n duration\\n caption\\n likeCount\\n realLikeCount\\n coverUrl\\n coverUrls {\\n cdn\\n url\\n __typename\\n }\\n photoUrls {\\n cdn\\n url\\n __typename\\n }\\n photoUrl\\n liked\\n timestamp\\n expTag\\n animatedCoverUrl\\n stereoType\\n videoRatio\\n profileUserTopPhoto\\n __typename\\n }\\n canAddComment\\n currentPcursor\\n llsid\\n status\\n __typename\\n }\\n hostName\\n pcursor\\n __typename\\n }\\n}\\n" }' response = requests.post('https://www.kuaishou.com/graphql', headers=headers, cookies=cookies, data=data) data_json = response.json()#解析json字符串格式 data_list = data_json['data']['visionProfilePhotoList']['feeds']#根据解析的数组找到列表 for data in data_list: title = data['photo']['caption']#视频名称 new_title = re.sub(r'[\/\\\:;\*#¥%$!@^……&()\?\"\<\>\|]', '_', title)#正则替换掉特殊符号生的报错 photoUrl = data['photo']['photoUrl'] # print(title, url_1) #https://v2.kwaicdn.com/upic/2021/12/21/20/BMjAyMTEyMjEyMDE1MTFfMTE1OTYxMDYyM182MzI0NjQzODAwMV8xXzM=_b_Bab5f65132c16fc17452d4acb7d135c71.mp4 #?pkey=AAUgxwI4RONXKIiP_Py40aJlX4ruOXWkEvshsbJzwBadL1D6DtsD0EPYTsH5VqSr9pRHiuPxnY5OPq98rRXLOHnB_MsNuT7TeSfn7WkAf6U8lqUgIdr_YxSJoCyhRxPK0og #&tag=1-1640240960-xpcwebprofile-0-u9e6n664af-c9b8d472abebf4e4&clientCacheKey=3xsbrqcnr28ucda_b.mp4&tt=b&di=274b47ea&bp=14734 content = requests.get(photoUrl).content#获取视频二进制内容后通过下面方法下载 with open('./liutao/video/' + new_title + '.mp4', mode='wb') as f: f.write(content) print(new_title, '爬取成功!!!') print("wancheng")
案例实现步骤:
- 找到目标网址 https://www.kuaishou.com/graphql
- 发送请求 get post
- 解析数据 (视频地址 视频标题)
- 发送请求 请求每一个视频的地址
- 保存视频
开始实现代码
1. 导入模块
import requests
import pprint
import json
import re
2. 请求数据
headers = { # data内容类型 # application/json: 传入json类型数据 json 浏览器跟 快手服务器 交流(数据传输格式)的方式 # 默认格式: application/x-www-form-urlencoded 'content-type': 'application/json', # cookie: 用户身份标识 有没有登录 'Cookie': 'did=web_53827e0b098c608bc6f42524b1f3211a; didv=1617281516668; kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3', # User-Agent: 浏览器信息(用来伪装成浏览器) 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36', } data = { 'operationName': "visionSearchPhoto", 'query': "query visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n type\n author {\n id\n name\n following\n headerUrl\n headerUrls {\n cdn\n url\n __typename\n }\n __typename\n }\n tags {\n type\n name\n __typename\n }\n photo {\n id\n duration\n caption\n likeCount\n realLikeCount\n coverUrl\n photoUrl\n liked\n timestamp\n expTag\n coverUrls {\n cdn\n url\n __typename\n }\n photoUrls {\n cdn\n url\n __typename\n }\n animatedCoverUrl\n stereoType\n videoRatio\n __typename\n }\n canAddComment\n currentPcursor\n llsid\n status\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n", 'variables': { 'keyword': keyword, 'pcursor': str(page), 'page': "search" # 发送请求 response = requests.post('https://www.kuaishou.com/graphql', headers=headers, data=data)
解析数据
for page in range(0, 11):
print(f'-----------------------正在爬取{page+1}页----------------------')
json_data = response.json()
data_list = json_data['data']['visionSearchPhoto']['feeds']
for data in data_list:
title = data['photo']['caption']
url_1 = data['photo']['photoUrl']
new_title = re.sub(r'[/\:*?"<>|\n]', '_', title)
# print(title, url_1)
# content: 获取到的二进制数据
# 文字 text
# 图片 视频 音频 二进制数据
content = requests.get(url_1).content
保存数据
with open('./video/' + new_title + '.mp4', mode='wb') as f:
f.write(content)
print(new_title, '爬取成功!!!')
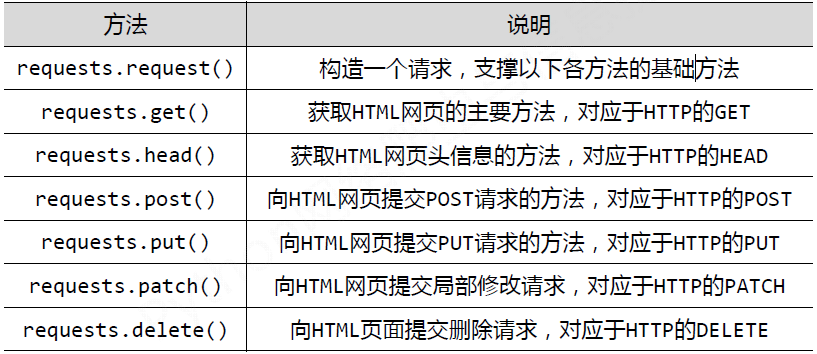
Response对象的属性


4、理解Requests库的异常
