根据网上文章自己修改:
例子:茶海棠个人主页:https://www.iesdouyin.com/share/user/3562042897739582?did=53298022046&iid=1566126643353143&sec_uid=MS4wLjABAAAA0NL6UPqIabTDseE8xmFLBQPQBfdIYAF2qyWT9M2N-SHwOr5Jo9D_0BJsYfSQnAVH&u_code=17jd75kj9×tamp=1615034003&utm_source=copy&utm_campaign=client_share&utm_medium=android&share_app_name=douyin
在抖音,记录美好生活! https://v.douyin.com/edDS6Sh/ 抖音分享的连接
找到带有uid的这个连接,多找几个会有用户的信息,接下来用的到
heder头部的 Request URL: 跟 user-agent在下面的代码中要用

requesturl : https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAA0NL6UPqIabTDseE8xmFLBQPQBfdIYAF2qyWT9M2N-SHwOr5Jo9D_0BJsYfSQnAVH&count=21&max_cursor=0&aid=1128&_signature=i0i00QAA6xrcf.yK-BO1jItItM&dytk=
仔细观察这个requesturl你会发现,其中有个count字段,这个代表每次请求个数,还有个max_cursor字段代表着,当前第几页
进入这个连接后,如下图,这个,max——cursor这个返回的字段值,就是下次需要请求url中要替换的值
判断下一页是否还有数据,则是根据 判断这个 hasmore 是否为true,如果为真则还有隐藏的内容,如果要继续显示剩下的内容,方法就是替换掉max——cursort字段值
然后继续请求这个url,直到hasmore为false
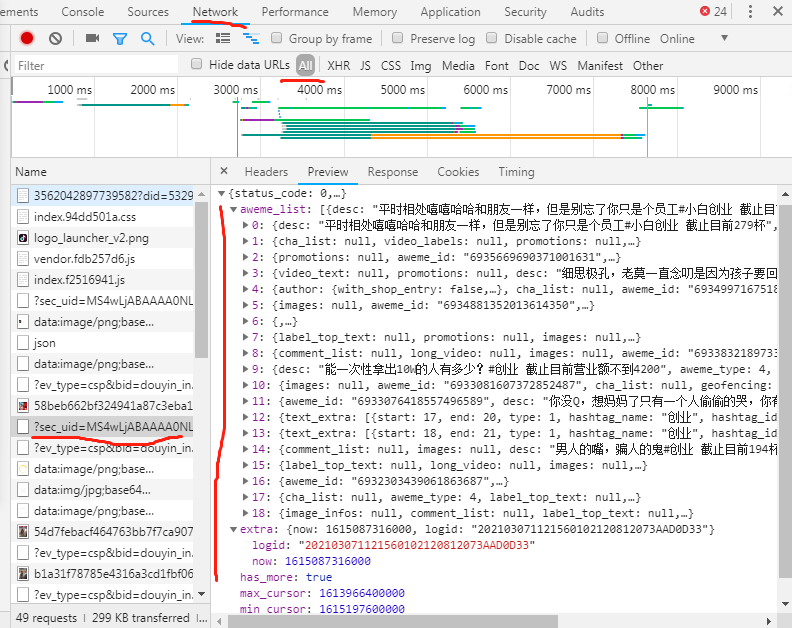
具体的aweme_list 视频连接规则,请看上一篇,这里有18个说明当前电脑访问这个主页,只能看到18个,因为有抖音网页限制
以下代码使用只需要修改requesturl 跟user-agent 即可
import requests import json from urllib import parse import re # 抖音视频的URL : Request URL: url="https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAA0NL6UPqIabTDseE8xmFLBQPQBfdIYAF2qyWT9M2N-SHwOr5Jo9D_0BJsYfSQnAVH&count=21&max_cursor=0&aid=1128&_signature=R6Ub1QAAJ-gQklOOeJfpTEelG8&dytk=" headers = { 'User-Agent':"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" } #调用requests中的get获取抖音作者主页的网页链接 r = requests.get(url=url, headers=headers,stream=True) #输出访问状态,如为<200>即为访问成功 print("初始访问状态:",r) #使用json解析获取的网页内容 data_json = json.loads(r.text) #使用json解析网页后,data_json的内容为dict格式,我们可以通过以下方式查看健名 print(data_json.keys()) has_more = data_json['has_more'] max_cursor = data_json['max_cursor'] #接下来使用循环来解决我们之前所提到的“隐藏内容”问题 #判断hasmore是否为true,如果为真则还有隐藏的内容,如果要继续显示剩下的内容 #name需要根据max_cursor 这个字段来进行分页读取 #url上次返回的结果中的max_cursor 就是下一次url需要替换的分页数 while has_more == True: print('has_more:',has_more) url_parsed = parse.urlparse(url)#打散url连接 bits = list(url_parsed) #将url连接区分开来 # ['https', 'www.iesdouyin.com', '/web/api/v2/aweme/post/', '', 'sec_uid=MS4wLjABA # AAA0NL6UPqIabTDseE8xmFLBQPQBfdIYAF2qyWT9M2N-SHwOr5Jo9D_0BJsYfSQnAVH&count=21&max # _cursor=0&aid=1128&_signature=R6Ub1QAAJ-gQklOOeJfpTEelG8&dytk=', ''] qs = parse.parse_qs(bits[4]) #选择第四个元素 # {'sec_uid': ['MS4wLjABAAAA0NL6UPqIabTDseE8xmFLBQPQBfdIYAF2qyWT9M2N-SHwOr5Jo9D_0B # JsYfSQnAVH'], 'count': ['21'], 'max_cursor': ['0'], 'aid': ['1128'], '_signature # ': ['R6Ub1QAAJ-gQklOOeJfpTEelG8']} qs['max_cursor'] = max_cursor #替换掉这个字段的值 bits[4] = parse.urlencode(qs, True) #将替换的字段拼接起来,并且url拼接时不转义 url_new = parse.urlunparse(bits) #重新拼接整个url #只要hasmore是否为true,则反复访问作者主页链接,直到成功返回这个为false r = requests.get(url=url_new, headers=headers,stream=True) data_json = json.loads(r.text) has_more = data_json['has_more'] #重置hasmore直到返回为false则退出循环 max_cursor = data_json['max_cursor']#每次重置这个页数,继续替换url中下一页页码进行访问 # print('has_more22:',has_more) print('maxcursor22:',max_cursor) #print('url_new:',url_new) #print('has_more22:',len(data_json['aweme_list'])) # for i in range(len(data_json['aweme_list'])): # print(data_json['aweme_list'][i]['video']['play_addr_lowbr']['url_list'][0]) # 我们要保存视频文件的主要路径 # 我们要保存视频文件的主要路径 path = "/" for i in range(len(data_json['aweme_list'])): #url_1为我们获取的视频链接 url_1 = data_json['aweme_list'][i]['video']['play_addr_lowbr']['url_list'][0] #t为我们获取的视频标题 t = data_json['aweme_list'][i]['desc'] # requests发送浏览器发送get请求,得到数据 r = requests.get(url=url_1, headers=headers,stream=True) print(r) #输出r访问状态 # 获取数据的二进制长度 reponse_body_lenth = int(r.headers.get("Content-Length")) # 打印数据的长度 print("视频的数据长度为:", reponse_body_lenth) #path_1为完整文件保存路径 path_1 = path+t+'.mp4' #去除文件名中特殊字符否则报错 rstr = r"[/\:;*#¥%$!@^……&()?"<>|]" # '/ : * ? " < > |' path_1 = re.sub(rstr, "", path_1) # 替换为"" # 保存抖音视频mp4格式,二进制读取 with open(path_1, "wb") as xh: # 先定义初始进度为0 write_all = 0 for chunk in r.iter_content(chunk_size=1000000): write_all += xh.write(chunk) # 打印下载进度 print("下载进度:%02.6f%%" % (100 * write_all / reponse_body_lenth))