一.概述
参考博客:https://www.cnblogs.com/yszd/p/8529704.html
二.代码实现【解析解】
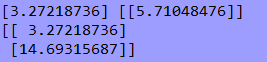
1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 __author__ = 'zhen' 5 6 # 这里相当于是随机X维度X1,rand是随机均匀分布 7 X = 2 * np.random.rand(100, 1) 8 # 人为的设置真实的Y一列,np.random.randn(100, 1)是设置error,randn是标准正太分布 9 y = 3 + 6 * X + np.random.randn(100, 1) 10 # 整合X0和X1 11 X_b = np.c_[np.ones((100, 1)), X] #combine聚合两数据集 12 # print(X_b) 13 14 # 常规等式求解theta 15 # invert 16 theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y) 17 print(theta_best) 18 19 # 创建测试集里面的X1 20 X_new = np.array([[0], [2]]) 21 X_new_b = np.c_[(np.ones((2, 1))), X_new] 22 print(X_new_b) 23 y_predict = X_new_b.dot(theta_best) 24 print(y_predict) 25 26 plt.plot(X_new, y_predict, 'r-') 27 plt.plot(X, y, 'b.') 28 plt.axis([0, 2, 0, 15]) 29 plt.show()
三.结果【解析解】

可视化:

四.代码实现【sklearn机器学习库】
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn.linear_model import LinearRegression 4 5 __author__ = 'zhen' 6 7 X = 2 * np.random.rand(100, 1) 8 y = 3 + 6 * X + np.random.randn(100, 1) 9 10 lin_reg = LinearRegression() 11 lin_reg.fit(X, y) 12 print(lin_reg.intercept_, lin_reg.coef_) 13 14 X_new = np.array([[0], [2]]) 15 y_predict = lin_reg.predict(X_new) 16 print(y_predict) 17 18 # 可视化 19 plt.plot(X_new, y_predict, 'r-') 20 plt.plot(X, y, 'b.') 21 plt.axis([0, 2, 0, 15]) 22 plt.show()
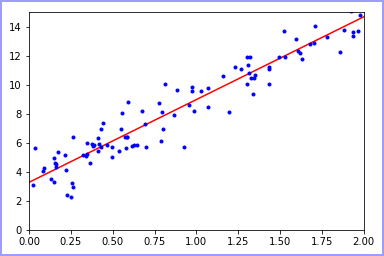
五.结果【sklearn机器学习库】
可视化:
六.总结
根据图示可以得出结论,使用解析解或者是sklearn机器学习库都可以得到大致的结论,所花费时间和达到的效率都比较类似。但这仅限于一元线性回归,当参数类别增加时,使用解析解会大大增加程序复杂程度和计算耗能,因此建议多使用sklearn库,并根据情况进行参数配置和优化。