一.软件要求
Flink在所有类UNIX的环境【例如linux,mac os x和cygwin】上运行,并期望集群由一个 主节点和一个或多个工作节点组成。在开始设置系统之前,确保在每个节点上都安装了一下软件:
1.Java1.8.x或更高版本
2.ssh,必须运行sshd才能使用管理远程组件的Flink脚本
在所有集群节点上都具有免密码的ssh和相同的目录结构,将使你可以使用flink脚本来控制所有内容。
二.Flink Standalone模式设置
1.下载
前往Flink官网下载最新版Flink【我下载的是flink-1.8.2】。若要在Hadoop上使用Flink,则需要下载与Hadoop匹配的版本。下载完成后,上传到几个各个节点并解压
2.配置Flink
通过编辑conf/flink-conf.yaml来为集群配置flink。设置jobmanager.rpc.address以指定flink主节点。还可以通过设置jobmanager.heap.size和taskmanager.heap.size来指定允许JVM在每个节点上分配的最大内存。这些值都是以MB为单位,如果某些工作程序节点有更多的内存分配给Flink集群,则可以通过FLINK_TM_HEAP在那些特定节点上设置环境变量来覆盖默认值。最后,必须提供集群中所有节点的列表,这些列表将用作工作节点。因此,类似于HDFS配置,编辑文件conf/slaves并输入每个子节点的IP/主机名。每个子节点都将运行TaskManager。
以下示例说明了具有三个节点(IP地址从10.0.0.1到10.0.0.3且主机名分别为master,worker1,worker2)的设置,并显示了配置文件的内容:

具体配置如下:
jobmanager.rpc.address:192.168.136.7 # 在每个节点上分别指定各自节点的IP/主机名
taskmanager.tmp.dirs: /usr/local/soft/flink-1.8.2/tmp # 指定每个taskmanager的临时目录 jobmanager.rpc.port: 6123 jobmanager.heap.size: 1024m taskmanager.heap.size: 1024m taskmanager.numberOfTaskSlots: 1 parallelism.default: 1
解释如下:
1.jobmanager.heap.size:每个JobManager的可用内存大小,默认为1024M
2.taskmanager.heap.size:每个TaskManager的可用内存大小,默认为1024M
3.taskmanager.numberOfTaskSlots:每台计算机可用的CPU数,默认为1
4.parallelism.default:集群中的CPU总数之和
5.io.tmp.dirs:临时目录
3.配置slaves

4.配置环境变量

5.启动flink
执行bin/start-cluster.sh启动JobManager,并通过SSH连接到slaves文件中列出的所有工作节点,以在每个节点上启动TaskManager。

6.Web UI
打开浏览器,输入:http://master:8081 
配置成功!
三.本地执行WordCount
1.代码
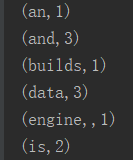
package cn.demo import org.apache.flink.api.common.operators.Order import org.apache.flink.api.java.utils.ParameterTool import org.apache.flink.api.scala._ //必须导入 /** * Created by Administrator on 2020/1/22. */ object WordCount { def main(args: Array[String]) { val params : ParameterTool = ParameterTool.fromArgs(args) // 设置execution执行环境 val execution = ExecutionEnvironment.getExecutionEnvironment // 设置web界面有效参数 execution.getConfig.setGlobalJobParameters(params) val text = execution.fromElements("Apache Flink is an open source platform for distributed stream and batch data processing.", "Flink core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. ", "Flink builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.") val counts = text.flatMap(_.toLowerCase.split(" ").filter(_.nonEmpty)) .map((_, 1)) .groupBy(0)//根据第一个元素分组 .sum(1) .sortPartition(0, Order.ASCENDING) //按照分区进行排序 .first(6) counts.print() } }
2.本地执行结果
四.案例执行
要运行Flink案例,必须有一个正在运行的Flink实例。最简单的方法是运行./bin/start-cluster.sh,默认情况下会启动一个带有JobManager和一个TaskManager的本地集群。每个Flink二进制发行版都包含一个examples目录,其中包含WordCount这个最常用案例。
要运行WordCount案例,执行以下命令:
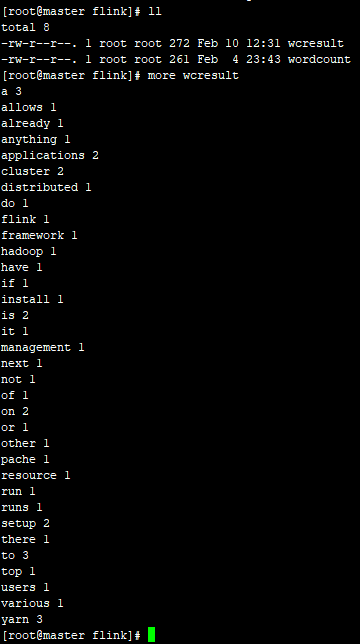
./bin/flink run ./examples/batch/WordCount.jar --input /data/flink/wordcount --output /data/flink/wcresult
备注:input路径要提前创建好,其中保存要计算的数据!

执行结果: