一.简介
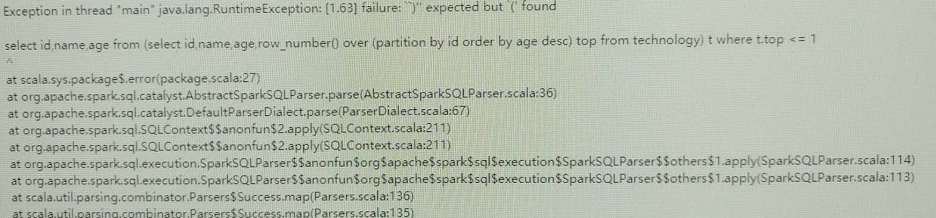
开窗函数row_number()是按照某个字段分组,然后取另外一个字段排序的前几个值的函数,相当于分组topN。如果SQL语句里面使用了开窗函数,那么这个SQL语句必须使用HiveContext执行。
二.代码实践【使用HiveContext】
package big.data.analyse.sparksql import org.apache.log4j.{Level, Logger} import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{Row, SparkSession} /** * Created by zhen on 2019/7/6. */ object RowNumber { /** * 设置日志级别 */ Logger.getLogger("org").setLevel(Level.WARN) def main(args: Array[String]) { /** * 创建spark入口,支持Hive */ val spark = SparkSession.builder().appName("RowNumber") .master("local[2]").enableHiveSupport().getOrCreate() /** * 创建测试数据 */ val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26") val rdd = spark.sparkContext.parallelize(array).map{ row => val Array(id, name, age) = row.split(",") Row(id, name, age.toInt) } val structType = new StructType(Array( StructField("id", StringType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) )) /** * 转化为df */ val df = spark.createDataFrame(rdd, structType) df.show() df.createOrReplaceTempView("technology") /** * 应用开窗函数row_number * 注意:开窗函数只能在hiveContext下使用 */ val result_1 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1") result_1.show() val result_2 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2") result_2.show() val result_3 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3") result_3.show() val result_4 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top > 3") result_4.show() } }
三.结果【使用HiveContext】
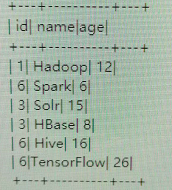
1.初始数据
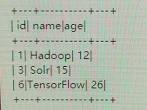
2.top<=1时
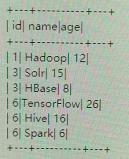
3.top<=2时

4.top<=3时
5.top>3时【分组中最大为3】
四.代码实现【不使用HiveContext】
package big.data.analyse.sparksql import org.apache.log4j.{Level, Logger} import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{Row, SparkSession} /** * Created by zhen on 2019/7/6. */ object RowNumber { /** * 设置日志级别 */ Logger.getLogger("org").setLevel(Level.WARN) def main(args: Array[String]) { /** * 创建spark入口,不支持Hive */ val spark = SparkSession.builder().appName("RowNumber") .master("local[2]").getOrCreate() /** * 创建测试数据 */ val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26") val rdd = spark.sparkContext.parallelize(array).map{ row => val Array(id, name, age) = row.split(",") Row(id, name, age.toInt) } val structType = new StructType(Array( StructField("id", StringType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) )) /** * 转化为df */ val df = spark.createDataFrame(rdd, structType) df.show() df.createOrReplaceTempView("technology") /** * 应用开窗函数row_number * 注意:开窗函数只能在hiveContext下使用 */ val result_1 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1") result_1.show() val result_2 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2") result_2.show() val result_3 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3") result_3.show() val result_4 = spark.sql("select id,name,age from (select id,name,age," + "row_number() over (partition by id order by age desc) top from technology) t where t.top > 3") result_4.show() } }
五.结果【不使用HiveContext】