1.图解
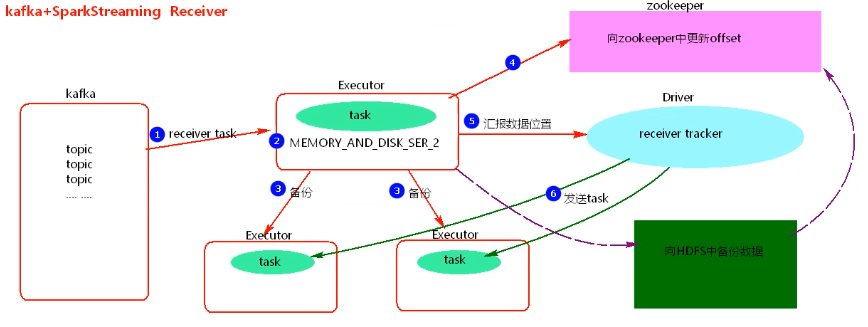
2.过程
1.使用Kafka的High Level Consumer API 实现,消费者不能自己去维护消费者offset,而且kafka也不关心数据是否丢失。
2.当向zookeeper中更新完offset后,Driver如果挂到,Driver下的Executors会被kill掉,会造成数据丢失。
3.开启WAL【Write Ahead Log】预写日志机制,将数据备份到HDFS中一份,再去更新zookeeper中的offset,此时需调整spark存储基本,去掉备份两次【MEMORY_AND_DISK_SER_2中的_2】。开启WAL机制会加大application处理的时间。
3.特点
1.receiver模式依赖zookeeper管理offset。
2.receiver模式的并行度由spark.streaming.blockInterval决定,默认是200ms。
3.receiver模式接收block.batch数据后会封装到RDD中,这里的block对应RDD中的partition。
4.在batchInterval一定的情况下,减少spark.streaming.Interval参数值,会增大DStream中的partition个数,建议spark.streaming.Interval最低不能低于50ms。
4.代码实现
package big.data.analyse.streaming import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkContext, SparkConf} /** * Created by zhen on 2019/5/11. */ object SparkStreamingReceiverKafka { def main(args: Array[String]) { val conf = new SparkConf() conf.setAppName("SparkStreamingReceiverKafka") conf.set("spark.streaming.kafka.maxRatePerPartition", "10") conf.setMaster("local[2]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val ssc = new StreamingContext(sc, Seconds(5)) // 创建streamingcontext入口 val quorum = "master,worker1,worker2" val groupId = "zhenGroup" val map : Map[String, Int] = Map("zhenTopic" -> 1) // topic名称为zhenTopic,每次使用1个线程读取数据 val dframe = KafkaUtils.createStream(ssc, quorum, groupId, map, StorageLevel.MEMORY_AND_DISK_SER_2) dframe.foreachRDD(rdd => { // 操作方式和rdd类似,必须使用action算子才会触发程序执行! rdd.foreachPartition(partition =>{ partition.foreach(println) }) }) } }