一.简介
FPGrowth算法是关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。在算法中使用了一种称为频繁模式树(Frequent Pattern Tree)的数据结构。FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。
相关术语:
1.项与项集
这是一个集合的概念,以购物车为例,一件商品就是一项【item】,若干项的集合为项集,如{特步鞋,安踏运动服}为一个二元项集。
2.关联规则
关联规则用于表示数据内隐含的关联性,例如买了新鞋的客户也往往会买袜子。
3.支持度
支持度是指在所有项集中{x,y}出现的可能性,即项集中同时出现含有x和y的概率。该指标作为建立强关联规则的第一个门槛,衡量了所考察关联规则在“量”上的多少。
4.置信度
表示在先决条件x发生的情况下,关联结果y发生的概率。这是生成强关联规则的第二个门槛,衡量了所考察的关联规则在“质”上的可靠性。
5.提升度
表示在含有x的条件下同时含有y的可能性与没有x的条件下项集含有y的可能性之比。
二.测试数据
r z h k p
z y x w v u t s
s x o n r
x z y m t s q e
z
x z y r q t p
三.代码实现
package big.data.analyse.mllib import org.apache.log4j.{Level, Logger} import org.apache.spark.mllib.fpm.FPGrowth import org.apache.spark.{SparkContext, SparkConf} /** * 关联规则 * Created by zhen on 2019/4/11. */ object FPG { Logger.getLogger("org").setLevel(Level.WARN) def main(args: Array[String]) { val conf = new SparkConf() conf.setAppName("fpg") conf.setMaster("local[2]") val sc = new SparkContext(conf) /** * 加载数据 */ val data = sc.textFile("data/mllib/sample_fpgrowth.txt") val data_spl = data.map(row => row.split(" ")).cache() /** * 创建模型 */ val minSupport = 0.2 val numPartition = 10 val model = new FPGrowth() .setMinSupport(minSupport) .setNumPartitions(numPartition) .run(data_spl) /** * 打印结果 */ println("Number of frequent itemsets : " + model.freqItemsets.count()) model.freqItemsets.collect.foreach{itemset => println(itemset.items.mkString("[", ",", "]") + " ==> " + itemset.freq) } } }
四.结果
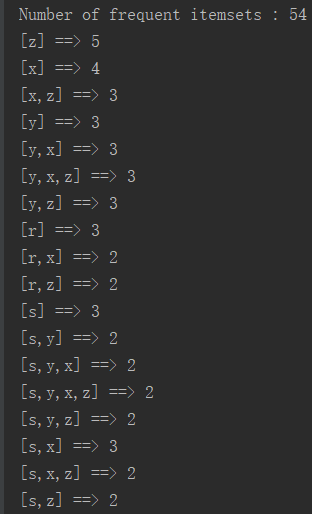 .......
.......
五.精简测试数据
y z
z y x
x
x z y
z
x z
六.二次开发代码实现
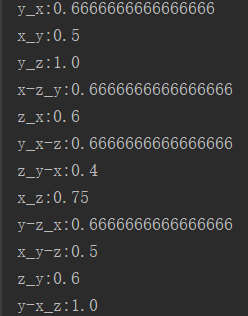
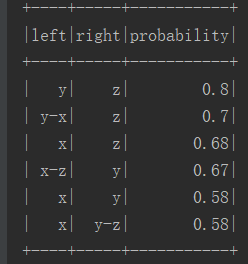
package big.data.analyse.mllib import org.apache.log4j.{Level, Logger} import org.apache.spark.mllib.fpm.FPGrowth import org.apache.spark.sql.types.{DoubleType, StringType, StructField, StructType} import org.apache.spark.sql.{Row, SQLContext} import org.apache.spark.{SparkContext, SparkConf} /** * 关联规则 * Created by zhen on 2019/4/11. */ object FPG { Logger.getLogger("org").setLevel(Level.WARN) def main(args: Array[String]) { val conf = new SparkConf() conf.setAppName("fpg") conf.setMaster("local[2]") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) /** * 加载数据 */ val data = sc.textFile("data/mllib/sample_fpgrowth.txt") val data_spl = data.map(row => row.split(" ")).cache() /** * 创建模型 */ val minSupport = 0.2 val numPartition = 10 val model = new FPGrowth() .setMinSupport(minSupport) .setNumPartitions(numPartition) .run(data_spl) /** * 打印结果 */ //println("Number of frequent itemsets : " + model.freqItemsets.count()) model.freqItemsets.collect.foreach{itemset => println(itemset.items.mkString("[", "-", "]") + " ==> " + itemset.freq) } /** * 把结果数据转换为Map */ val map = model.freqItemsets .map{row => var map : Map[String,Double] = Map() map += (row.items.mkString("-") -> row.freq.toDouble) map }.collect().flatten.toMap val list = map.keysIterator.toList /** * 拆分比较,计算概率 */ var mid_result : Map[String, Double] = Map() for(i <- 0 until list.length){ for(j <- 0 until list.length){ if(i != j){ if(list(i).contains(list(j))){ // xy -> xyz var key = "" if(list(i).indexOf(list(j)) == 0){ // 子串位于母串开头 key = list(j) + "_" + list(i).replace(list(j) + "-", "") }else{// 子串位于母串的中间或者末尾 key = list(j) + "_" + list(i).replace("-" + list(j), "") } val left = map(list(j)) val right = map(list(i)) val value = right / left mid_result += (key -> value) }else{// TODO 分开包含的也要加进行,比较顺序不一定一致,例如:xy -> xzy val left_key = list(i).split("-") val right_key = list(j).split("-") var isno = true for(x <- 0 until right_key.length){ if(!left_key.contains(right_key(x))){ isno = false } } if(isno){ // 包含 var mid_key = "" // 拼接key for(y <- 0 until left_key.length){ if(!right_key.contains(left_key(y))){ mid_key += left_key(y) + "-" } } if(mid_key != ""){ // 清除末尾多余的- mid_key = mid_key.substring(0, mid_key.length-1) } val key = list(j) + "_" + mid_key val left = map(list(j)) val right = map(list(i)) val value = right / left mid_result += (key -> value) } } } } } /** *平衡标签先后顺序对概率的影响 */ var result : List[String] = List() val keys = mid_result.keysIterator.toList for(i <- 0 until keys.length){ println(keys(i) +":"+ mid_result(keys(i))) } for(i <- 0 until keys.length){ for(j <- 0 until keys.length){ if(i != j){ val left = keys(i).split("_") val right = keys(j).split("_") if(left(0) == right(1) && left(1) == right(0)){ val value = ((mid_result(keys(i)) + mid_result(keys(j)))/2).formatted("%.2f") // 保留两位小数 if(left(0) < left(1)){ result = result.:+(left(0) + "_" + left(1) + "_" + value) }else{ result = result.:+(left(1) + "_" + left(0) + "_" + value) } } } } } result = result.distinct // 去重 /*for(i <- 0 until result.length){ println(result(i)) }*/ /** * 转换为rdd */ val result_rdd = sc.parallelize(result).map(row => { val Array(left, right, probability) = row.split("_") Row(left, right, probability.toDouble) }) /** * 定义结构 */ val structType = new StructType(Array( StructField("left", StringType, true), StructField("right", StringType, true), StructField("probability", DoubleType, true) )) val result_df = sqlContext.createDataFrame(result_rdd, structType) import org.apache.spark.sql.functions._ result_df.orderBy(desc("probability")).show() } }
七.结果
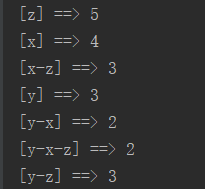
八.备注
集群模式出现以下异常【local模式无异常】;
can not set final scala.collection.mutable.ListBuffer field org.apache.spark.mllib.fpm.FPTree$Summary.nodes to scala.collection.mutable.ArrayBuffer
解决方案:
配置:conf.set("spark.serializer", "org.apache.spark.serializer.JavaSerializer")