面向对象编程第1次总结
需求分析
这3次作业的题目要求是对表达式求导,同时需要判断错误输入。
显而易见,作业可以分成这些模块:输入输出,表达式解析,表达式求导。
所以,笔者的代码结构仿照工厂模式:
表达式解析单独为1个工厂类,根据字符串构造表达式对象。
表达式对象提供求导方法返回求导结果表达式,并重载toString()方法输出标准化的字符串。
主程序读入输入数据,通过表达式解析class构建表达式对象,调用求导方法并输出结果。
表达式的解析
总的来说,这3次作业中,笔者使用的都是递归下降的方法解析表达式,而不是使用正则表达式的group去分离表达式因子。
好处是相对于一长串正则,递归下降可读性好,而且是线性时间复杂度,不会像使用正则表达式一样出现栈溢出等问题。
可以边解析边判断错误输入时,不必先进行判断。
缺点是解析部分几乎无法重用,每次作业都必须重写。
词法解析
参照Scanner的next,笔者写了一个next方法,传入正则表达式的参数,返回匹配到的token。由于这里的正则表达式十分简单,不会出现栈溢出等错误。
其中,整数使用正则表达式 [+-]?d+ 来提取。其他token对应的正则表达式都只有1-2个字符的长度,这里省略。
语法分析
使用BNF文法会可能需要消除左递归,故采用更加灵活的EBNF文法来描述。以第3次作业为例子:
SinFactor := 'sin' '(' Factor ')' ('^' Number)?
CosFactor := 'cos' '(' Factor ')' ('^' Number)?
PowerFactor := 'x' ('^' Number)?
ConstFactor := Number
ExpressionFactor := '(' Expression ')'
Factor := PowerFactor
| SinFactor
| Cos
| ExpressionFactor
| ConstFactor
Term := Factor ('*' Factor)*
| '+' Factor ('*' Factor)*
| '-' Factor ('*' Factor)*
Expression := ('-'|'+')? Term ('-'|'+' Term)*
测试
本地测试
事实上,笔者在完成作业的过程中,将将近一半的时间用来编写测试代码和构造测试数据。使用Junit进行本地测试。大体思路如下:
将测试代码放在单独的文件夹(例如test文件夹)里,将样例和自己构造的测试数据放到一个总的测试样例集合里。之后就可以使用IDEA等IDE进行测试。
提交的时候,将test文件夹添加到 .gitignore 。
互测
笔者采用的方式是以黑盒测试为主的方法,使用Python编写数据生成器进行对比。首先安装对拍用到的工具:sympy。
pip install sympy
数据生成器是根据文法手写的,实际生成的测试点也令人满意;xeger等工具主要用于辅助生成空白字符串等。
不过sympy有个不足之处:不能解析带前导0的数字。对于这种测试数据只能人工进行判断。
多次运行随机测试的方法,最坏情况下可能多个随机样例都测不出bug;但是实际上这种方法非常有效,我使用了这种方法找到了多个非同质的bug。
除了黑盒测试之外,笔者也通过阅读代码,发现可能存在bug的位置,例如正则表达式、循环的边界情况等。实际互测环节中,也构造样例,使长度过长的正则表达式匹配运行超时。
Tips
提取常用方法
在写Parser的时候,要多次用到判断是否有非法字符、判断空格和水平制表符,为了便于重用,笔者将这些method放在单独的class,定义为静态方法。
调试信息
仿照Android系统的Logcat,笔者实现了一个Log类,将调试信息分为verbose, debug, info, warn, error等级别,这样以来,通过调整过滤器(笔者将其实现为一个static变量控制),就能控制输出哪些调试信息,便于调试。在最终提交的版本,只要改动这个变量就可以不输出调试信息。
第1次作业
这次作业需求相对简单,输入为简单多项式。
代码结构
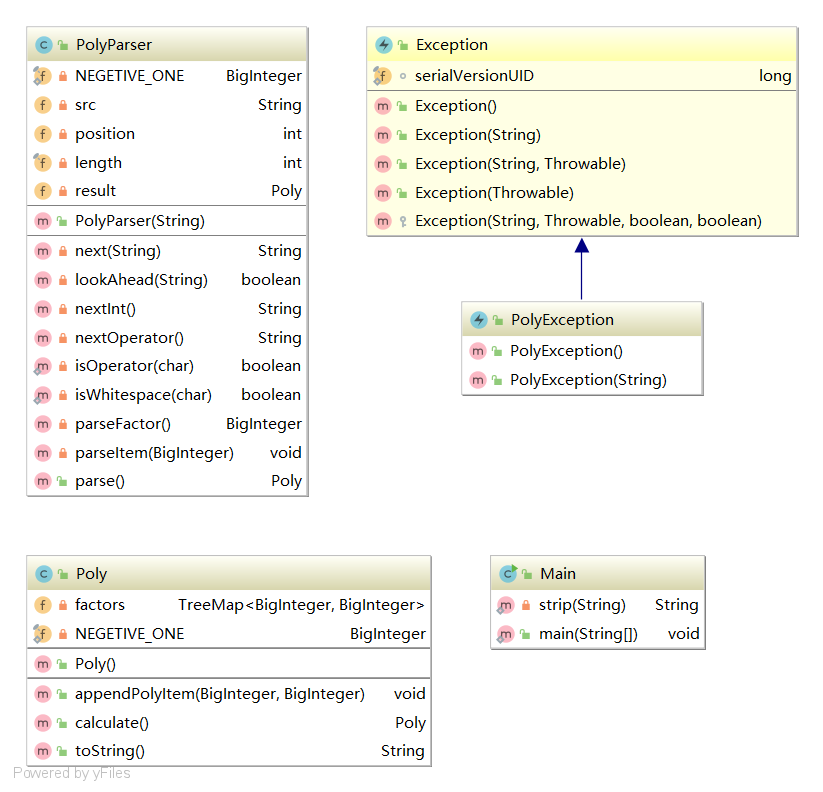
代码复杂度
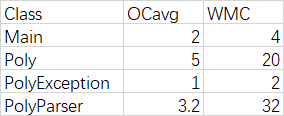
互测环节
这次作业暴露出来的问题很多:异常处理、格式错误的判断、代码风格。
在互测环节,有的同学没有考虑输入空串的情况,抛出越界异常,而且还没有捕获异常,导致运行时错误。
有的同学使用正则表达式 s 判断空格和TAB,但是实际上s包括其他空白字符,例如'v',而这些字符属于错误输入。但是很多同学没有考虑这一点,结果是'v'成为hack别人的通用测试点之一。。
有的同学只写了一个Main类,完全是面向过程编程。
另外,笔者在这次互测也被发现了bug,原因是在结果为0的情况下输出空串。
第2次作业
这次作业加入了三角函数,复杂度增加,同时化简空间更大。例如,利用sin(x)^2+cos(x)^2=1化简。
解析方面,笔者仍然采用递归下降。
关于化简,笔者出于稳妥考虑,只写了同类项合并,导致强测被扣了很多性能分。
关于进一步化简的思路,可以参考这些同学的博客。
https://www.cnblogs.com/MisTariano/p/10535508.html
https://www.cnblogs.com/tqnwhz/p/10559893.html
https://prime21.github.io/2019/03/19/OO-unit1-summary/
代码结构
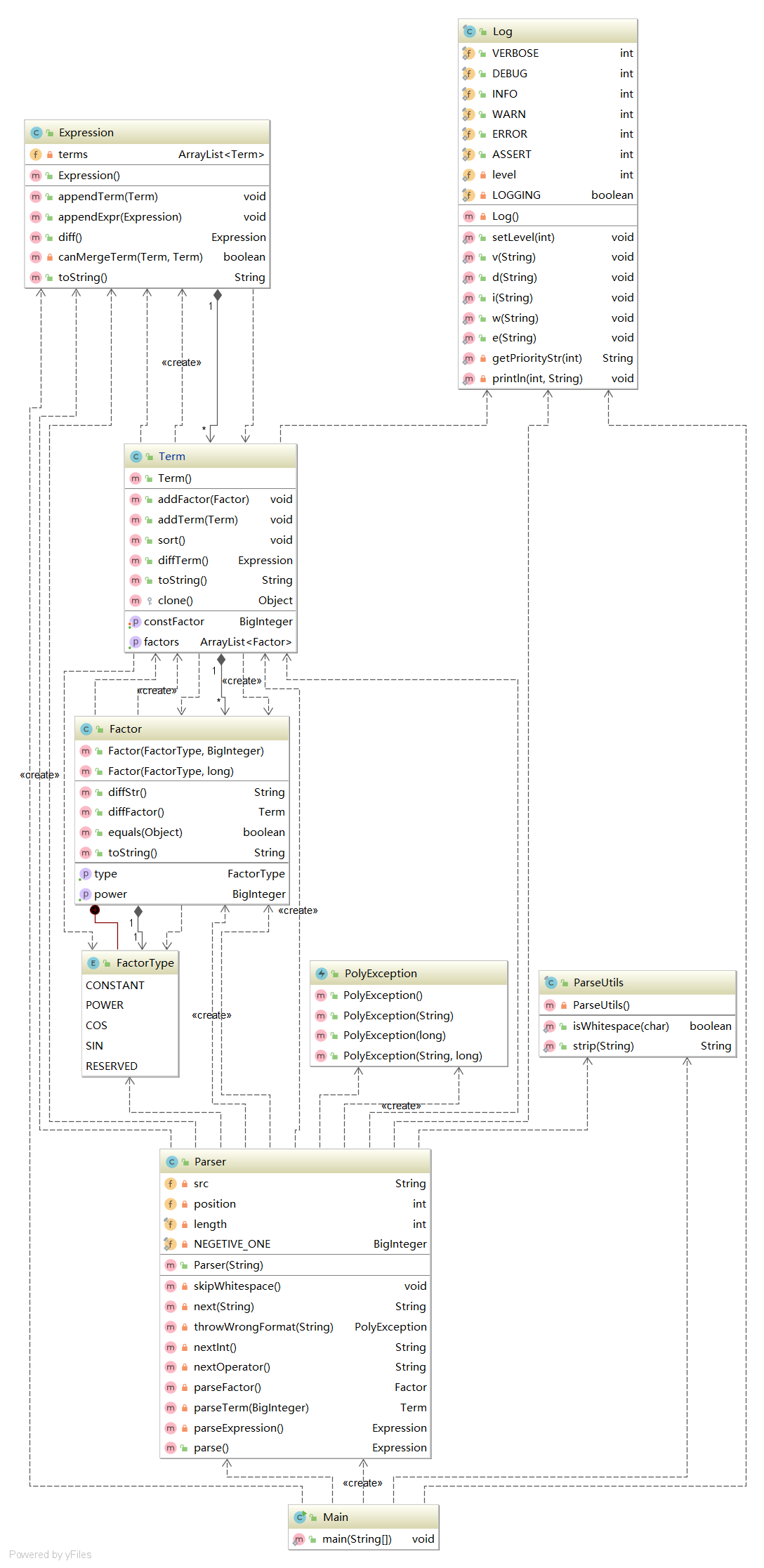
代码复杂度
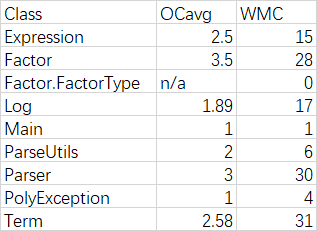
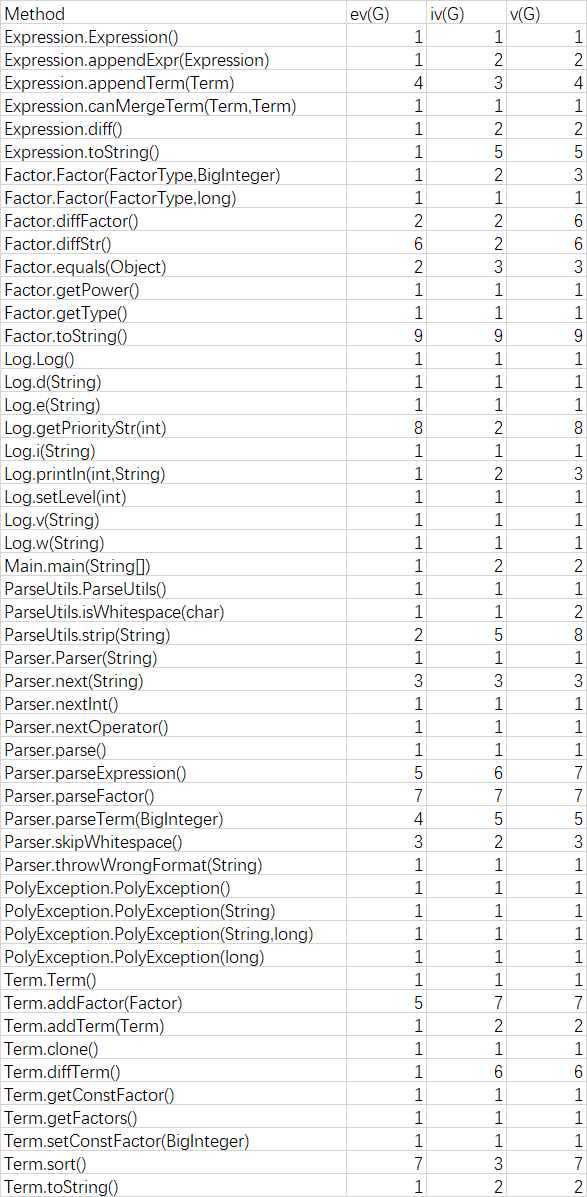
互测环节
第二次作业由于指导书给出了很多错误格式的样例,因此笔者不再着重测试这一点,更加关注正确性。这次笔者首次使用随机生成数据进行黑盒测试的方法,成功找出了很多bug,有些随机生成的样例甚至使3名同学的程序输出错误结果。
这次互测找出的bug主要是首尾空白字符的处理,正负号的判断。
另外,仍有同学使用很长的正则表达式匹配,笔者利用xeger生成的字符串(错误格式)使程序超时。
在这次互测中,笔者没有被找出bug。
第3次作业
第三次作业需要处理括号嵌套的情况,这时已经难以使用正则表达式分离因子,因为表达式本身可以作为因子。相对的,递归下降显示了其巨大的优势。
使用数学公式化简极为困难,比较好写的化简方法有合并常数项等。由于各种因素,笔者没有写化简。
代码结构
由于出现了嵌套,笔者定义了一个求导接口,以便组织代码。
使用接口,构建表达式树并自顶向下求导变得十分自然。代码框图如下图所示。
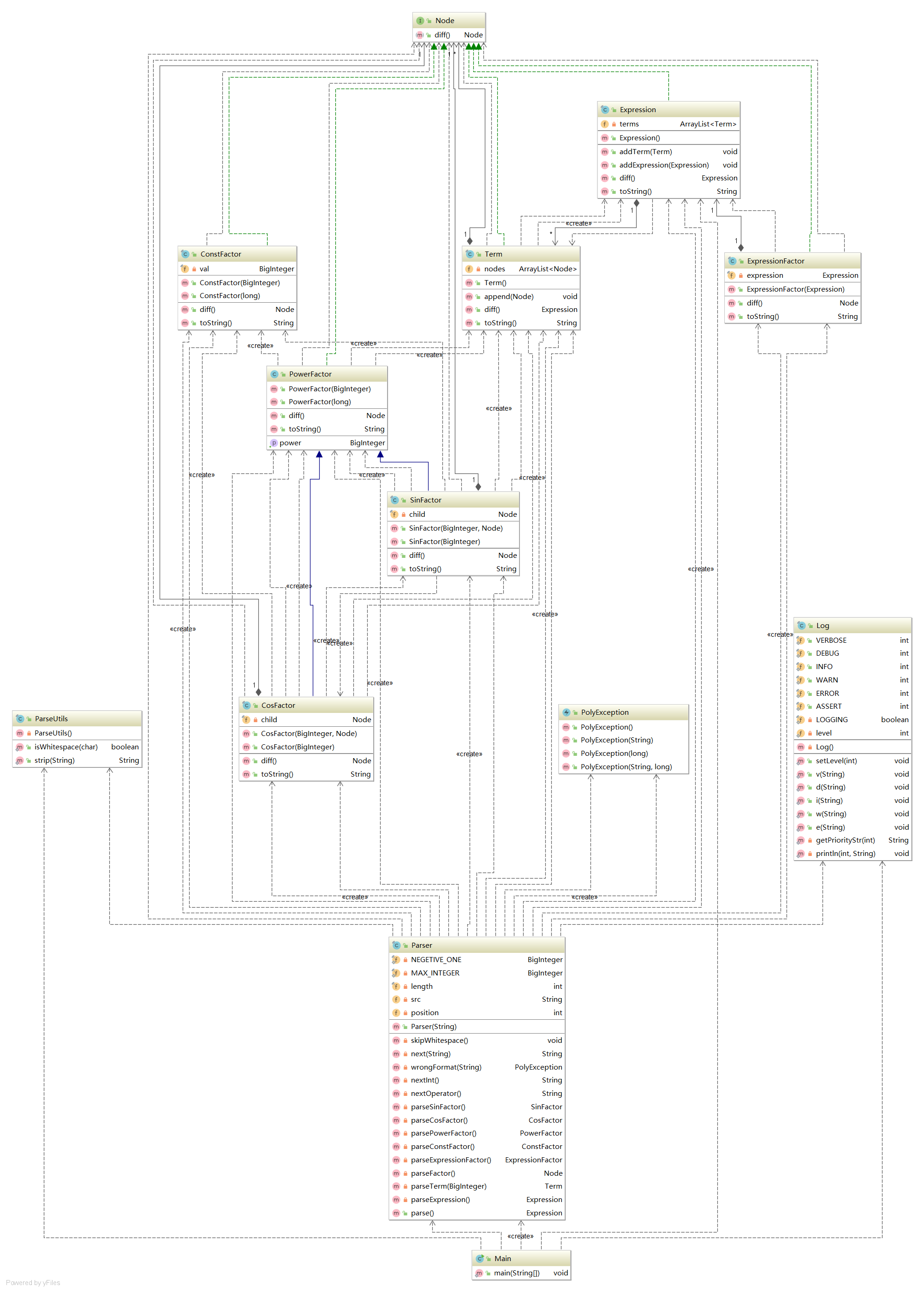
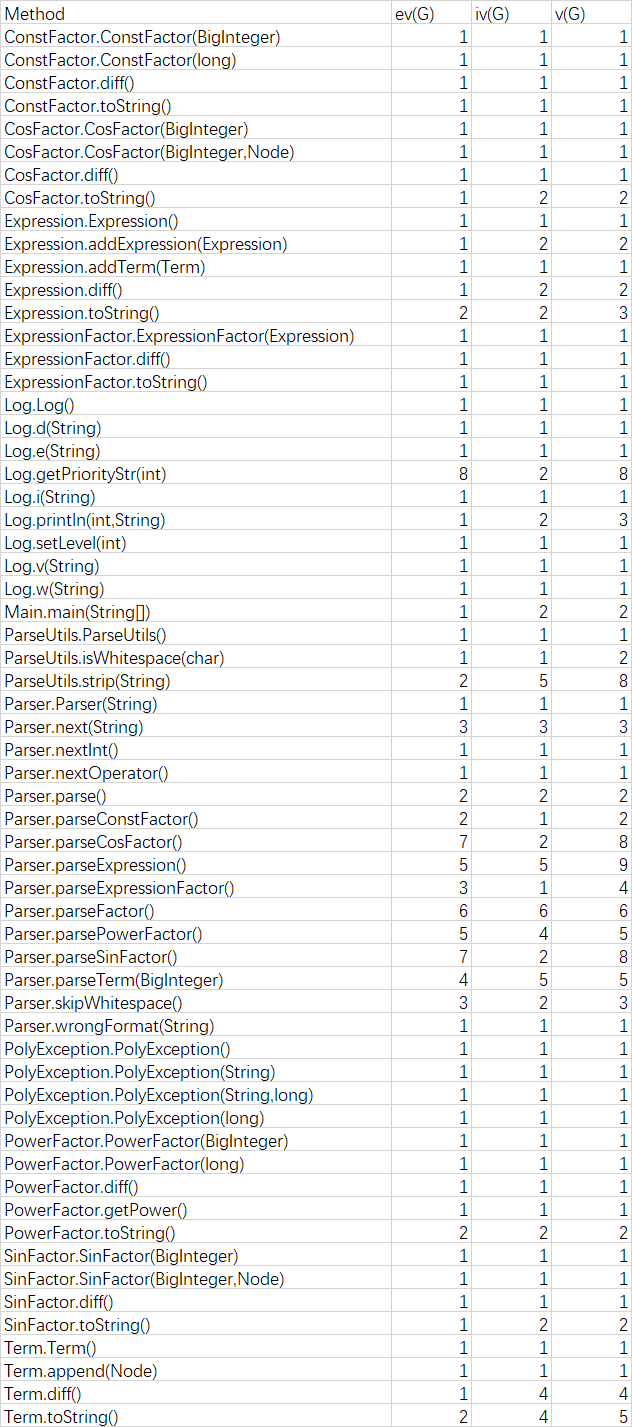
代码复杂度
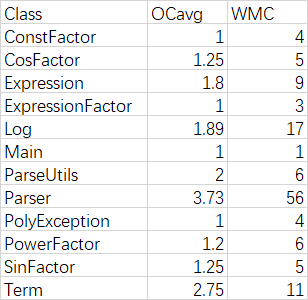
互测环节
这次作业的互测不再关注对错误格式的判断,而是更加关注程序的正确性。
令人吃惊的是,这次作业仍然有人只用一个Class,面向过程编程。在使用随机数据的情况下,这名同学的程序将一半以上的合法输入判断为格式错误。
由于这次作业涉及了递归,如果处理不当,必将出现栈溢出、运行时间过长等后果。笔者在互测环节也成功发现了这些bug。
另外就是输出结果的bug,例如化简结果输出错误等。
在这次互测中,笔者没有被找出bug。
总结
这3次作业过来,同学们对Java语言的掌握程度提升了很多,对面向对象编程的优势有更为深入的认识。同时,也意识到程序鲁棒性的重要意义。
正则表达式是很好的工具,在匹配字符串等方面有极为重要的地位,事实上第1次、第2次作业中,多数同学使用正则表达式来寻找项、分离系数、指数等。但是,过于复杂的正则表达式往往会留下很多问题,不仅阅读起来困难,而且会导致栈溢出、超时等严重的问题。基于以上考虑,这几次作业中,笔者只使用尽可能简单的正则表达式用于提取Token。
关于面向对象编程的优势,在这次作业的主要体现在:利用异常机制将错误输入的处理和正常业务逻辑分开,利用接口将不同代码组织起来。
关于代码结构,从类图来看,在这几次作业中,笔者只是利用到了最基本的继承、接口机制,而class之间相对独立;此外,解析类总代码量将近300行,代码结构还有很大的改进空间。