每个程序员都应该有自己最精通的一门语言,也许是缘分吧 ,很早就认识了Python,一直没多大在意,可是现在越来越发现Python在成长,随着Python 3K的发布,可以说,它的语法功能几乎囊括了现代编程语言中所有的精华。最关键的是,它是开源的,开源意味着自由,集体共享的智慧。
自由之路开始了,呵呵。
今天把Crawl Image 完成了。当然,还有很多地方需要改进。特别是线程方面,等以后空了再改吧,和大家分享一下,也算学python第一阶段的总结。
• 学习了python的urllib ,urlparse,HTMLParser,等模块
• 重点研究了HTMLParser 中的tag_handle 事件处理机制,自定义函数实现tag触发事件
• 采用内存缓存的形式存储数据,以站内页面的URL为字典的索引,方便判断URL是否已经加入URL容器,URL容器存储所有将要分析和已经分析的页面URL,继承了Dict字典类。
• 具体流程如下图: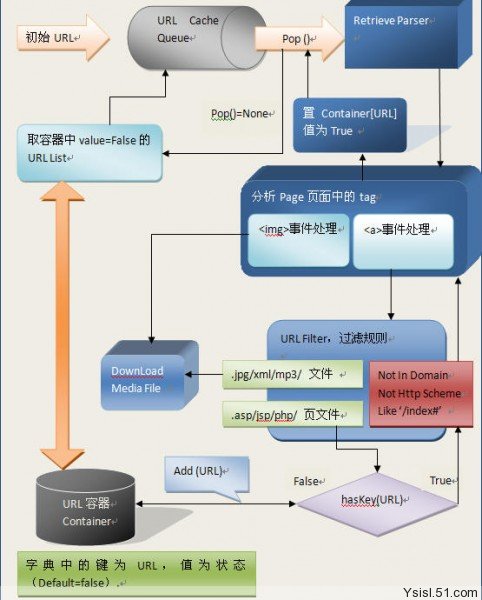
这个过程中还没有用到多线程下载,正在写一个线程通用模块,只要加上修饰符@thread的函数,就表示可以在子线程中独立运行,主线程不用等待,如果有任务需要子线程返回的结果,可以使用线程对象的join()函数。估计要过一段时间才能出下一个版本。
源码下载