scrapy shell 命令请求网页:
scrapy shell "https://www.baidu.com"
就会得到请求的网页源代码,我们通过response.text可以获取请求之后的源代码,然后就可以通过正则匹配我们想要的内容
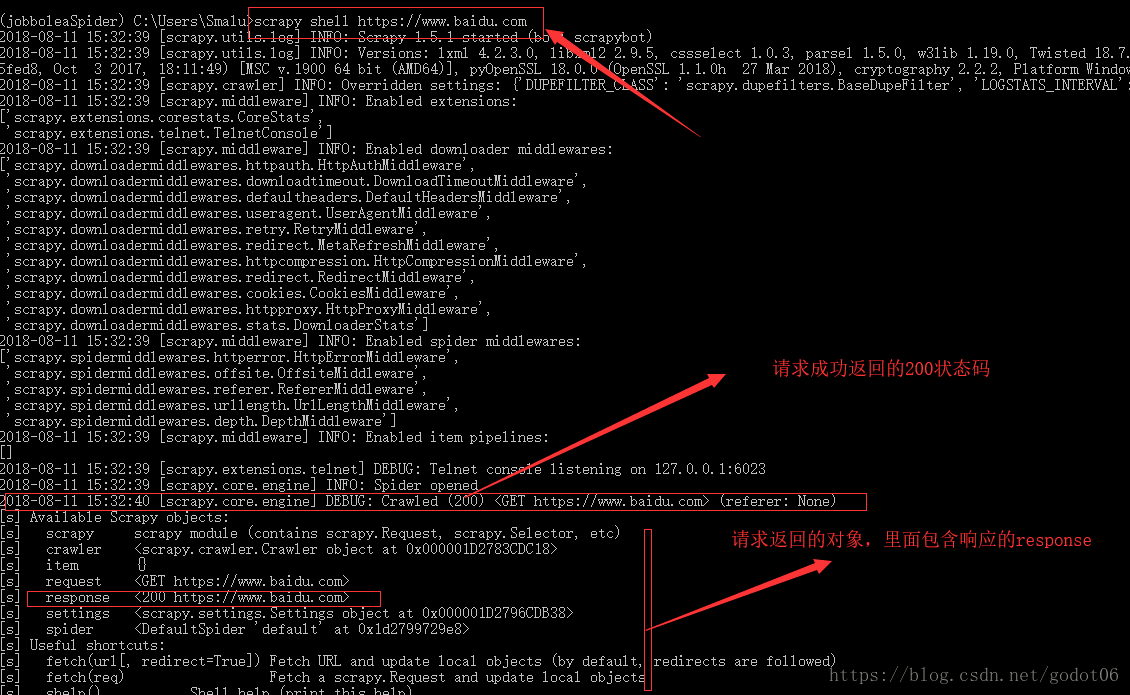

2.然后上面请求方法,对一些不做限制的网站请求时ok,但是就如之前所讲的,很多网站对没有设置请求头的请求都是禁止访问,所以我们的爬虫中都设置了headers头部,那么在scrapy如何设置请求头呢?
问题分析,我们设置请求头很大一部分其实是在于headers,所以我们在scrapy中设置user-agent其实就完成了请求headers头部的设置。
scrapy shell -s USER_AGENT="" request_url 就可以完成带头部的请求添加,如请求知乎(不带头部请求时400错误):
scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0" https://www.zhihu.com/question/285908404
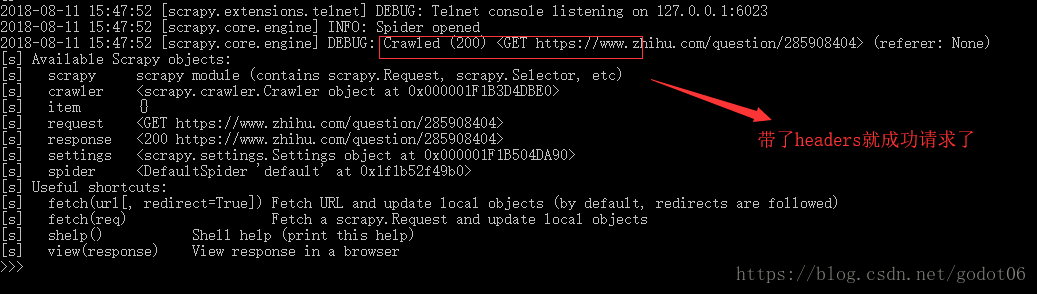
这样我们就可在scrapy查看我们请求的原网页和验证我们写的正则表达式
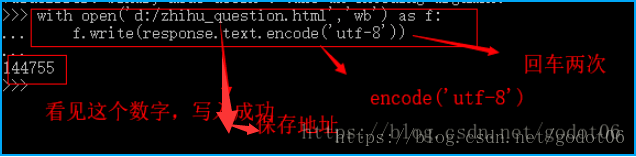
3.通过上述请求后,我们通过response.text可以获得我们请求的源码,那么如何保存呢?
保存代码其实跟编辑器中的代码一样:
with open('d:/zhihu_question.html','wb') as f: f.write(response.text.encode('utf-8'))
原文链接:https://blog.csdn.net/godot06/article/details/81587242