前面配置了三个节点的redis服务后,通过对key的hash取余来决定kev-value来存入哪个节点。但是考虑到对redis服务进行扩容和缩容时(增减redis节点),会出现数据的未命中,严重会导致雪崩,因此不使用哈希取余来分配key-value。redis采用的是哈希一致性的算法,这种算法会优化哈希取余未命中的问题,其中SharedJedis就是实现了这种算法的类,可以通过它底层进行哈希一致性计算后,分配key-value到具体的节点。
哈希取余和哈希一致性
当存在多个redis节点时,不管是哈希取余,还是哈希一致性,都是为了让key-value找到它的"归宿",即具体的redis节点,反过来通过key,可以找到对应的保存了数据的redis节点。
(1)哈希取余,存在redis节点扩容和缩容数据未命中的问题,如图,假设增加一个redis04节点,则原来保存在redis01的某个key-value,扩容后通过key依然可以从redis01获取到数据就变成了概率事件。
概率计算:
a.假设redis01为0号分区,即key.hashCode()&Integer.MAX_VALUE%3=0的分区,则这个key进行31位保真运算后的整数值为3的倍数,以3n表示。
b.扩容后,取余的分母变成4,因此这个key继续落到0号分区的概率,等于3n/4==0的概率,而3不能被4整除,因此就等效于n/4==0的概率,这个概率为25%。
计算完后,发现命中的概率仅为25%,而未命中的概率高达75%,这就容易导致数据大量未命中后雪崩的发生。这是3个节点扩容的情况,以此类推,如果是m个节点,则扩容一个节点后,数据命中的概率为1/m+1,未命中概率为m/m+1,可见节点越多,未命中的概率越大,这是非常可怕的事情。
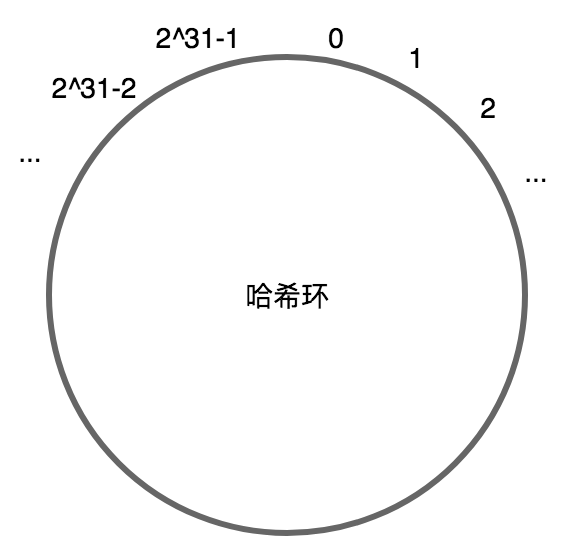
(2)哈希一致性,是基于哈希环的,用一个0-2^31-1的数字区间,包含redis节点的位置信息,以及key-value的位置信息,然后通过某种规则,将redis节点和key-value联系起来,就可以实现上面说的找到key-value的"归宿"。
a.哈希环
内存中的对象数据,通过CRC16算法映射到这个区间,只要对象不变,对象在哈希环中的对应位置就不变,这个跟哈希取余有点类似,都是能确定位置,它就是一个记录地址的载体,通过它可以获取对象数据的地址信息,可以作为中间信息过渡。
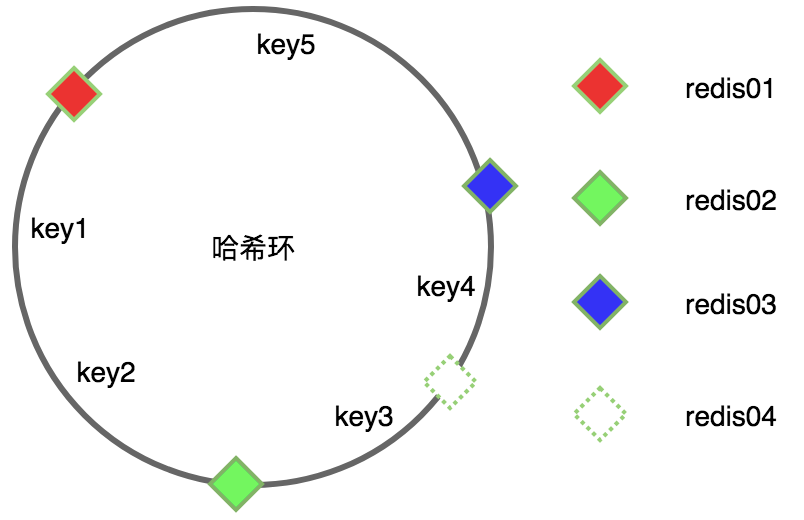
b.redis节点和key在哈希环中的映射
根据CRC16算法,它们都会在哈希环中有个对应的位置,入图所示。接下来就需要将redis节点和key对应起来,采用的规则是以key为参照物,顺时针寻找最近的redis节点,这个节点就是key需要存储的位置,因此下图节点和key之间的对应关系就是(key1 key2→redis01),(key3 key4→redis02),(key5→redis03),这样就确定了key-value存储的位置了。

c.redis节点扩容或缩容时,数据迁移和未命中的问题。
以扩容为例,如图如果添加一个节点redis04,发现key4指向的节点发生了变化,变成了redis04,这样就造成了key4的数据迁移和未命中,这样不跟哈希取余一样的结局吗,其实还是有区别的。hash取余添加节点后,波及的范围是整体,而hash一致性,波及的范围只是添加了这个节点的哈希环的一个弧段,当前也就影响了redis02和redis03之间的区间,其他不受影响,因此造成的数据未命中也只是redis03和redis04之间的数据范围。如果哈希环中的redis节点越多,则影响的范围从概率上来说就越小,所以它是对hash取余的一个大的优化。
d.虚拟节点的引入
事实上,如果上面的redis节点通过CRC16算法计算后映射到hash环中的位置非常集中,这样势必会造成某些节点对应的数据非常少或非常多,产生数据的倾斜。为了解决这个问题引入了虚拟节点,默认一个真实的redis节点会对应160个虚拟节点,key顺时针如果找到了虚拟节点,通过虚拟节点就可以找到真实的节点。由于虚拟节点量大,在哈希环中均匀分布的概率就大,这样数据倾斜的概率就会降低。
一般真实节点做映射会使用ip+端口号,如192.168.200.140:6379,则虚拟节点就是192.168.200.140:6379#1~192.168.200.140:6379#160来做映射。
e.节点的权重
如果想让某个节点能存储更多的数据怎么办,hash一致性也可以设置权重,可以配置更多的虚拟节点,就可以实现,使用API连接操作时可以在JedisShardInfo中指定。
相关API操作
哈希一致性有对应的api操作,在进行hash一致性的api操作之前,先捋一遍redis中目前常用的操作方式,暂时不考虑redis-cluster的情况。
(1)使用Jedis连接单个redis节点
分为单个Jedis实例对象连接,和JedisPool来连接两种。
a.单个实例对象连接,参考上篇https://www.cnblogs.com/youngchaolin/p/11983705.html#_label2。后续所有的api操作是在上次测试的环境中完成。
b.JedisPool连接。
//jedis连接池的使用,连接单个节点 @Test public void test04(){ JedisPool jedisPool=new JedisPool("192.168.200.140",6379); //从连接池中获取redis Jedis jedis=jedisPool.getResource(); //使用jedis jedis.set("clyang","I have a dream"); String s = jedis.get("clyang"); System.out.println(s); //使用完后jedis归还到连接池 jedisPool.returnResource(jedis); //关闭jedis连接 jedis.close(); }
测试ok。
127.0.0.1:6379> get clyang "I have a dream"
(2)使用Jedis连接多个redis节点
这里使用了两种方式,一种是通过Jedis实例对象连接多个redis节点,另外一种类似上面,也是通过JedisPool来连接多个redis节点,两者均使用hash取余。
a.单个Jedis节点连接的情况,也是参考上篇https://www.cnblogs.com/youngchaolin/p/11983705.html#_label2。
b.使用JedisPool的方式连接,这里封装成了一个HashJedis类,在里面添加hash取余。
HashJedis类
package com.boe; import org.junit.Test; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import java.util.ArrayList; import java.util.List; /** * 封装了hash取余算法的类,使用JedisPool来连接 */ public class HashJedis { /** * set,get,hset,hget等,所有jedis底层操作,都可以重写 */ private int N; private List<JedisPool> poolList=new ArrayList<>(); public HashJedis(){ } public HashJedis(List<String> nodes){ N=nodes.size(); for (String node : nodes) { System.out.println(node); String host=node.split(":")[0]; int port=Integer.parseInt(node.split(":")[1]); //构造一个连接池对象 JedisPool pool=new JedisPool(host,port); poolList.add(pool); } } //set、get方法的案例,完成分片 public void set(String key,String value){ //获取hash取余计算后的节点 JedisPool jedisPool= hashKeyToNode(key); Jedis jedis=jedisPool.getResource(); //对获取的节点进行get ,set操作等。 try{ jedis.set(key,value); System.out.println("分片set成功"); }catch (Exception e){ e.printStackTrace(); System.out.println("分片set失败"); }finally { /*if(jedis!=null){ jedis.close(); }else{ jedis=null; }*/ //将jedis归还到jedispool jedisPool.returnResource(jedis); } } public Object get(String key){ //获取hash取余计算后的节点 JedisPool jedisPool = hashKeyToNode(key); Jedis jedis=jedisPool.getResource(); //对获取的节点进行get ,set操作等。 try{ String s = jedis.get(key); System.out.println("分片get成功"); return s; }catch (Exception e){ e.printStackTrace(); System.out.println("分片get失败"); return ""; }finally { /*if(jedis!=null){ jedis.close(); }else{ jedis=null; }*/ jedisPool.returnResource(jedis); } } //自定义获取节点的方法 public JedisPool hashKeyToNode(String key){ int result=(key.hashCode()&Integer.MAX_VALUE)%N; //从上面保存的集合中取出节点 JedisPool jedisPool = poolList.get(result); //Jedis jedis = jedisPool.getResource(); //return jedis; return jedisPool; } //jedis本身也有上述封装的方法,叫做SharedJedis,底层使用的是hash一致性 }
测试方法,只要set进去了,就能通过key的hash取余找到存储的redis节点,将value获取到。
@Test public void test01(){ List<String> nodeList=new ArrayList<>(); String node01="192.168.200.140:6379"; String node02="192.168.200.140:6380"; String node03="192.168.200.140:6381"; nodeList.add(node01); nodeList.add(node02); nodeList.add(node03); //封装了hash取余以及JedisPool的对象 HashJedis hashJedis=new HashJedis(nodeList); //set hashJedis.set("name","messi"); //get Object name = hashJedis.get("name"); System.out.println((String)name); }
测试ok。
127.0.0.1:6379> get name "messi"
(3)通过SharedJedis来连接
这才是主角,它是通过hash一致性来确认连接节点的,跟上面类似,它既有单个SharedJedis对象的连接操作,也有对象SharedJedisPool连接池的操作。这里两种都测试下,并且如上所说,可以对单个redis节点通过SharedJedis设置权重。
//jedis本身也有封装的方法,叫做SharedJedis,底层使用hash一致性来实现 @Test public void test02(){ List<JedisShardInfo> list=new ArrayList<>(); //第一个节点设置权重为3 list.add(new JedisShardInfo("192.168.200.140",6379,500,500,3)); list.add(new JedisShardInfo("192.168.200.140",6380)); list.add(new JedisShardInfo("192.168.200.140",6381)); //使用SharedJedis分片对象 /*ShardedJedis shardedJedis=new ShardedJedis(list); shardedJedis.set("star","herry"); System.out.println(shardedJedis.get("star"));*/ //使用SharedJedisPool分片连接池对象 JedisPoolConfig config=new JedisPoolConfig(); config.setMaxTotal(200); config.setMaxIdle(8); config.setMinIdle(3); ShardedJedisPool pool=new ShardedJedisPool(config,list); //获取一个SharedJedis对象 ShardedJedis resource = pool.getResource(); //set测试 for (int i = 0; i < 1000; i++) { String key= UUID.randomUUID().toString(); resource.set(key,""); } }
a.使用SharedJedis测试,往redis中存入数据,ok。
127.0.0.1:6380> get star "herry"
b.使用ShareJedisPool测试,往redis存入数据,并设置了6379端口的redis权重为3,其他两个端口的默认都为1,因此测试结果理论6379上面数据会是3/5的比例。
redis01结果,621个数据。

redis02结果,177个数据。

redis03结果,202个数据。

可以看出结果跟理论接近,只是实际上有些许数据倾斜。
以上就是对redis哈希一致性和相关API的记录,这里记录一下,后续知识继续补充。
参考博文