调度器scheduler是yarn中重要角色之一,它负责分配container资源给application,有如下三种调度器可供配置选择,分别是FIFO Scheduler,Capacity Scheduler和Fair Scheduler,可以通过yarn-site.xml配置自己的调度器。
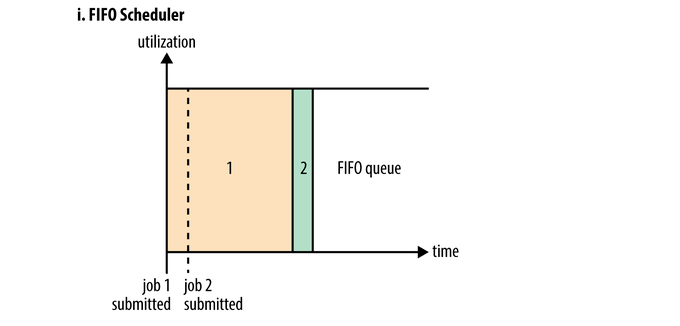
FIFO Scheduler
FIFO调度器使比较low的一种调度器,它遵循先进先出的原则,即一个queue中application先进先出,这种对资源使用的策略是队列中哪个application先拿到了资源,则其需先执行完后释放container资源才能执行队列中下一个application。FIFO Scheduler调度器模式下,一个job提交后抢占到的资源将占据到100%,队列中其他job由于没有多余资源可用只能等待,因此如果一个队列中有一个执行时间很长但不紧急的job和许多执行时间短但紧急的job,则会出现问题。执行时间长的job如果先执行会一直占用资源,而小job只能等待。另外,FIFO Scheduler不需要配置可以直接拿来用。
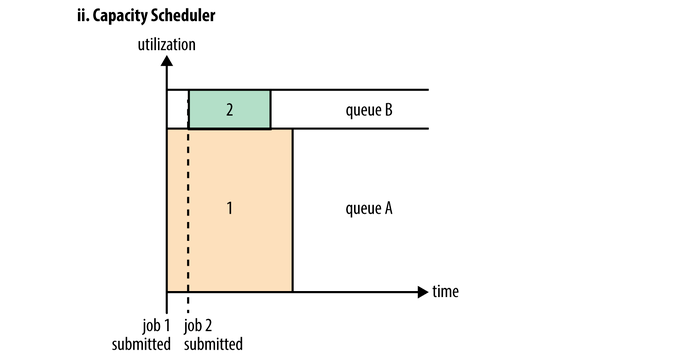
Capacity Scheduler
Apache下的Hadoop调度器默认采用的就是Capacity Scheduler,它对资源的使用不仅仅只有一个队列,一般会给一个执行时间长的application分配一个队列(如图queue A),给执行时间短的application也分配一个队列(如图queue B)。这样的话执行时间长的job和短的job都可以获取container资源执行,如提交job1会立马执行,只占据它所拥有的那一部分container资源,当job2提交后也会获取它的一部分资源执行,这样做的缺点是执行时间长的job会占用相对少的资源,从而比FIFO Scheduler情况下会执行更多的时间来完成任务。另外使用Capacity Scheduler是在etc/hadoop/yarn-site.xml文件中配置的,配置具体信息需在etc/hadoop/Capacity-scheduler.xml中完成,如配置队列A和B、各自权重、队列可以上浮的最大资源占比均是在xml文件中完成。
root是顶级队列,下面可以配置量产(prod)和开发(dev)队列,开发队列中又可以继续拆分A和B队列,队列存在层级关系。
root
├── prod
└── dev
├── A
└── B
以下是配置capacity-scheduler.xml示例。
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<property>
<!--root顶级队列下配置两个队列,分别为量产队列prod和开发队列dev-->
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<!--dev队列下有两个子队列A和B-->
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>A,B</value>
</property>
<property>
<!--prod资源权重,40也可以表示为2-->
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<!--dev资源权重,60也可以表示为3-->
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<!--dev最大资源可上浮到的权重-->
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<!--队列A占用资源,实际为总资源的0.6*0.5=30%-->
<name>yarn.scheduler.capacity.root.dev.A.capacity</name>
<value>50</value>
</property>
<property>
<!--队列B占用资源,实际为总资源的0.6*0.5=30%-->
<name>yarn.scheduler.capacity.root.dev.B.capacity</name>
<value>50</value>
</property>
</configuration>
队列配置完成后如果想让application指派到这个对列中执行,可以在代码中进行配置,注意后面队列名不是全局名,就是队列层级中最后的名字即可,如果配置全局名会报错。
configuration.set("mapreduce.job.queuename","A");
下面在CDH版本hadoop下配置容量调度器,需要先加上如下配置信息到yarn-site.xml中,并且分发到各个hadoop节点。
<!-- cdh版本hadoop,默认是FairScheduler调度器,配置为使用CapacityScheduler-->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
还需要配合capacity-scheduler.xml文件使用,原本在etc/hadoop目录下就已经存在一个这样的文件,可以先备份一下源文件再重新创建一个新的同名文件,将上面内容添加进去,也需分发到各个hadoop节点。
配置完后不会立即生效,还需要重启yarn。
[hadoop@node01 /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop]$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
node02: stopping nodemanager
node03: stopping nodemanager
node01: stopping nodemanager
no proxyserver to stop
You have new mail in /var/spool/mail/root
[hadoop@node01 /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-resourcemanager-node01.out
node03: starting nodemanager, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node03.out
node02: starting nodemanager, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node02.out
node01: starting nodemanager, logging to /kkb/install/hadoop-2.6.0-cdh5.14.2/logs/yarn-hadoop-nodemanager-node01.out
重启yarn后,刷新对应yarn UI界面,可以看到调度器变成了容量调度器,并且队列也是上面配置的队列信息。

举例选取单词统计的代码,需要配置队列名,这里选择dev下的A。
//优先读取conf.set里的属性设置,然后是读取resources下的文件,获取属性
Configuration conf=new Configuration();
//设置指定的队列运行job
conf.set("mapreduce.job.queuename","A");
重新打包,并且使用hadoop jar运行。
[hadoop@node01 /kkb]$ hadoop jar hadoop-1.0-SNAPSHOT.jar com.kaikeba.mapreduce.WordCountMain /readme.txt /wordcount0510
运行后刷新UI界面,可以看到任务运行在指定的队列中。

容量调度器的配置在运行时,可以随时重新加载刷新队列,编辑etc/hadoop目录下的capacity-scheduler.xml文件,并且使用"yarn rmadmin -refreshQueues"命令刷新,但是这个命令不删除队列。
编辑capacity-scheduler.xml文件,在dev下新增一个队列C,将文件重新分发到各个节点。
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<property>
<!--root顶级队列下配置两个队列,分别为量产队列prod和开发队列dev-->
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<!--dev队列下有两个子队列A和B-->
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>A,B,C</value>
</property>
<property>
<!--prod资源权重,40也可以表示为2-->
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<!--dev资源权重,60也可以表示为3-->
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<!--dev最大资源可上浮到的权重-->
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<!--队列A占用资源,实际为总资源的0.6*0.4=24%-->
<name>yarn.scheduler.capacity.root.dev.A.capacity</name>
<value>40</value>
</property>
<property>
<!--队列B占用资源,实际为总资源的0.6*0.5=30%-->
<name>yarn.scheduler.capacity.root.dev.B.capacity</name>
<value>50</value>
</property>
<property>
<!--队列C占用资源,实际为总资源的0.6*0.1=6%-->
<name>yarn.scheduler.capacity.root.dev.C.capacity</name>
<value>10</value>
</property>
</configuration>
刷新队列信息。
[hadoop@node01 /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop]$ yarn rmadmin -refreshQueues
刷新UI界面,可以看到多出了一个队列。
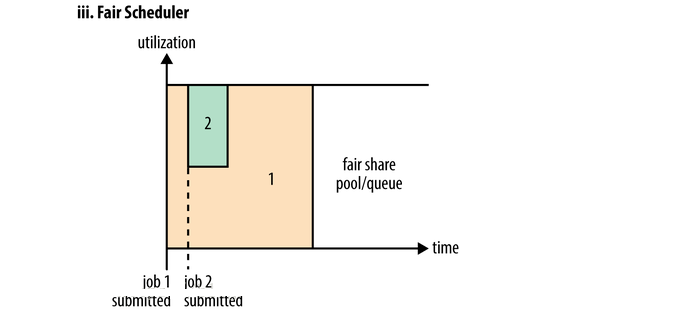
Fair Scheduler
最后一种是Fair Scheduler,也称作公平调度器,这种调度器相对前两个调度器总体来说可以更大的利用资源,即面向整体的job,它是资源利用最好的。如下图所示当job1提交后,发现队列中没有其他application,它会占用总个队列资源开始执行,当job2提交后需要资源,此时队列会分一半的资源给job2,但是不会立马给它,还需要job1释放一半的资源后,job2得到资源才能运行任务,这里有一个等待时间,它是可以设置的,超过等待时间如果job1依然没有释放资源则会抢占资源。当job2执行完后释放资源,job1又会占用队列全部的资源继续执行,这种模式看上去就是充分的利用了资源同时又让任务不会长时间等待资源。Hadoop分布式项目CDH默认会使用Fair Scheduler,其他的如果使用它可以配置yarn-site.xml来完成,将yarn.resourcemanager.scheduler.class设置为公平调度器的完全限定名org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler。
公平调度器具体细节的配置也有一个文件,其在fair-scheduler.xml中完成,参考上面capacity-scheduler的层级关系,也可以在公平调度器实现。
<?xml version="1.0"?>
<allocations>
<!-- 设定默认调度策略为fair-scheduler -->
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<!-- 也可以配置层级队列,默认root依然是顶级队列 -->
<queue name="prod">
<weight>40</weight>
</queue>
<queue name="dev">
<weight>60</weight>
<!-- dev队列下配置A和B两个子队列,没有指定资源权重默认按照五五开 -->
<queue>A</queue>
<queue>B</queue>
</queue>
</allocations>
上面说的抢占资源,也是可以设置的,通过将yarn-site.xml的yarn.scheduler.fair.preemption属性设置为true就全面启动抢占功能,即允许调度器终止job1占用的的本来属于job2的资源,job1被中止的任务需要重新执行,某种意义上来说这样会降低整个集群的任务执行效率。
参考博文:
(1)《hadoop核心权威指南第四版》