目录:
- python简介
- python安装与执行
- pycharm简单设置及使用
- 注释使用及.pyc文件
- python变量
- python用户交互(输入输出)
- if条件语句
- 循环语句(while & for)
- 运算符
- python数据类型初识(int,bool,str,list,dict)
一、python简介:
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
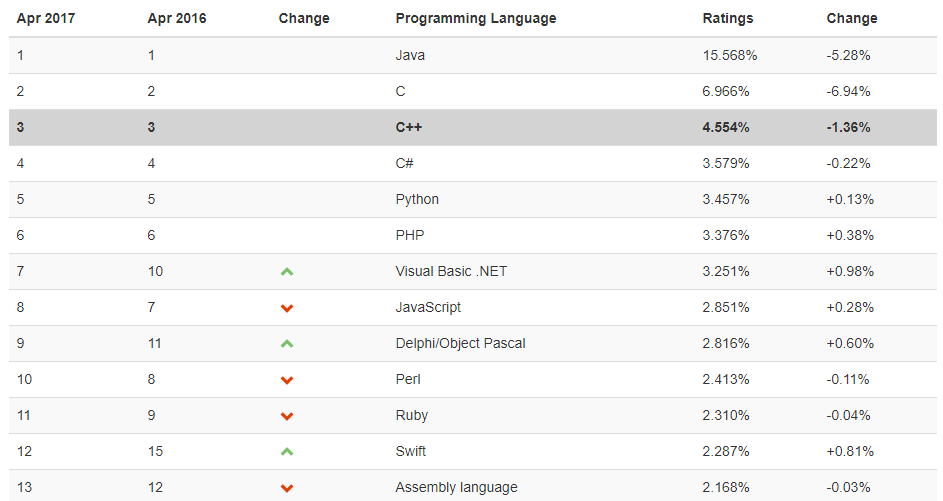
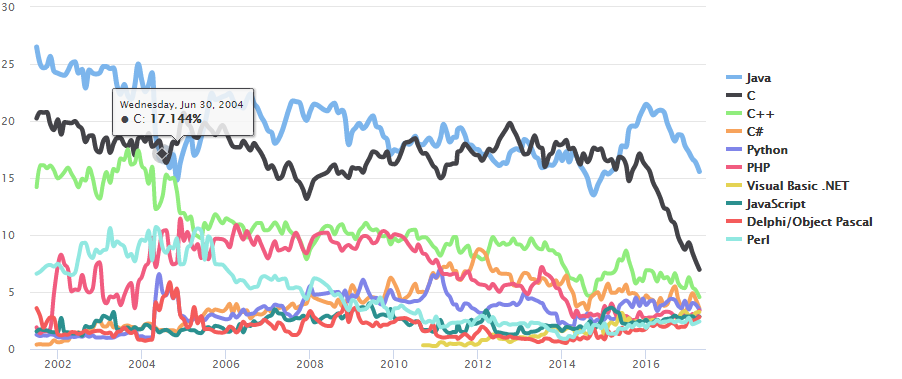
python的目前应用领域:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域
python的目前公司常用领域:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
使用python的公司:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等
ps:有上可知,python正越来越受到程序员们的广泛认可,那python的优势在哪里呢?
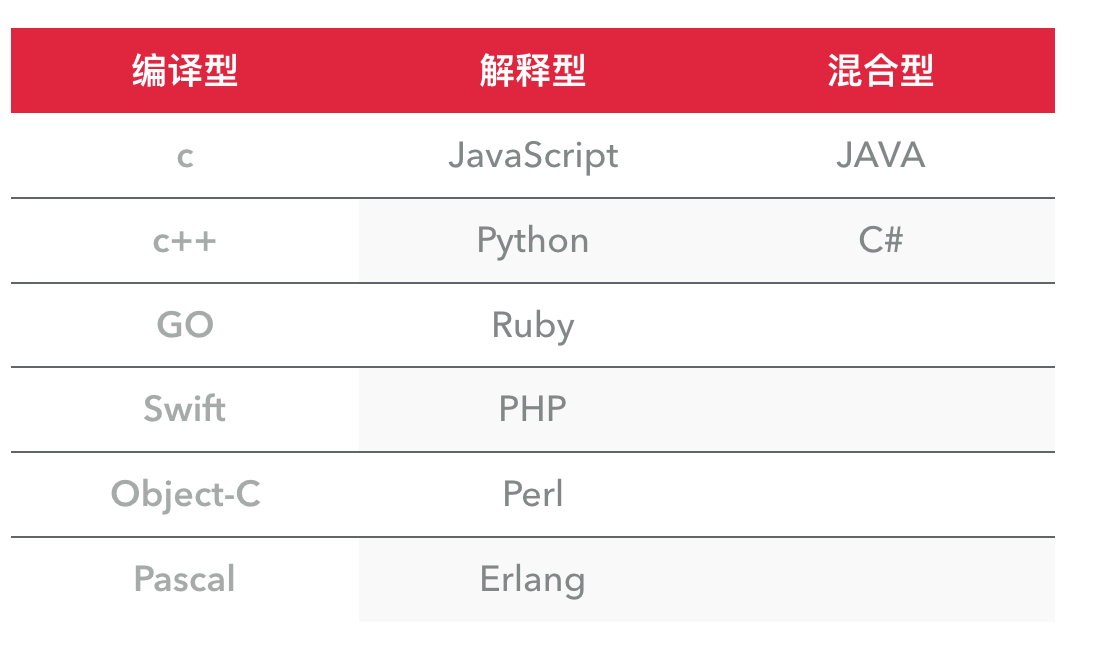
1、python和其他语言对比:
a.C 和 Python、GO、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
b.Python 和 C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
c.python和GO语言
对于使用:Go语言是未来的语言,它属于编译型(有关解释型语言和编译型语言解释,注1)语言,作为新型的语言,网络传输方面目前所有语言第一,就是语法基础等方面还有待于完善。
对于速度: 与C相当,很牛逼的语言,身为小白的我,坐等它的成熟。
d.Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
ps.所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。
2、python的种类:
a.CPython:
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。目前我们建议使用3.5版本。
解释器:CPython。为C语言开发
运行方式:命令行下使用python命令直接运行。
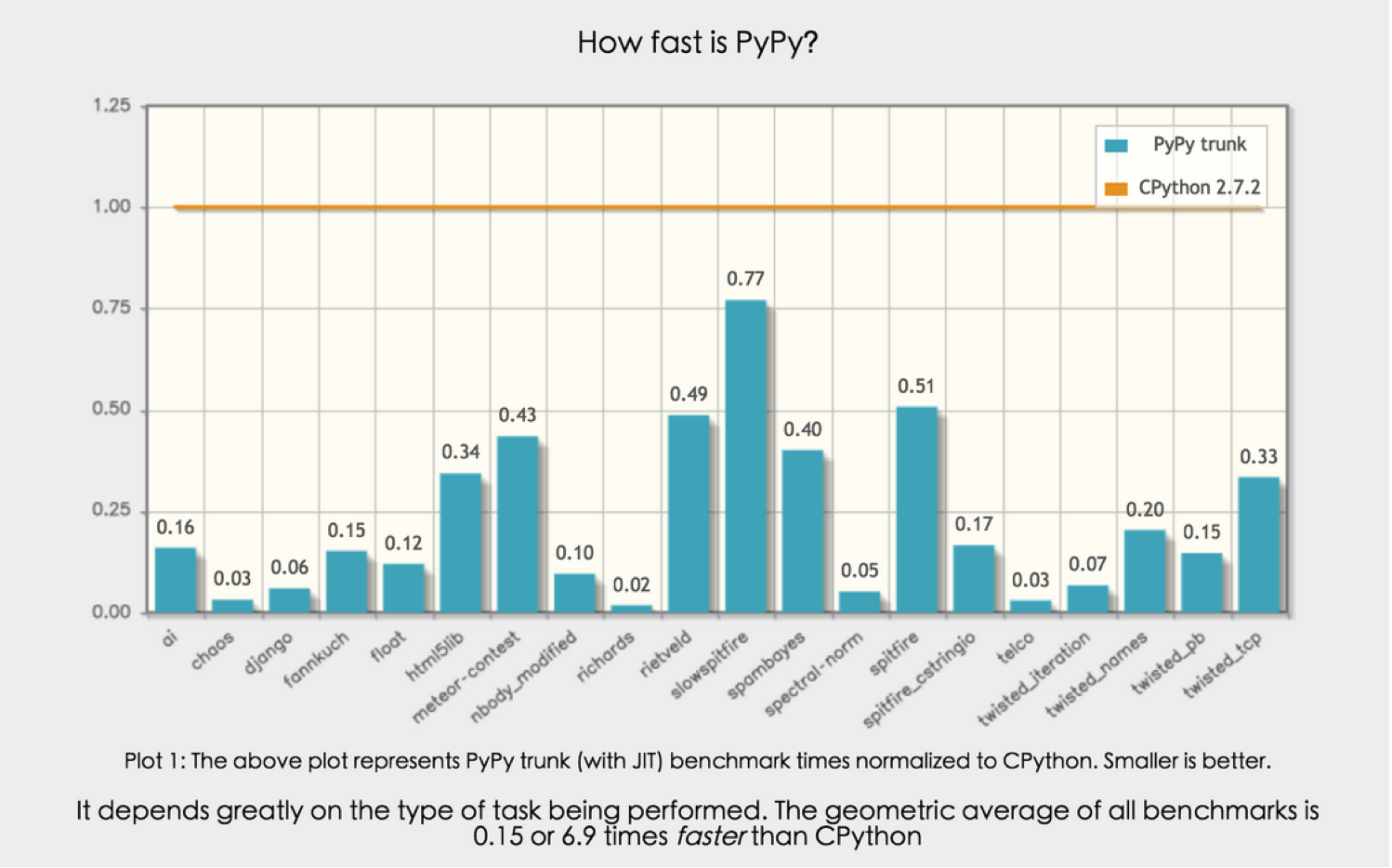
b.pypy:
Python实现的Python,pypy采用JIT技术,将Python的字节码字节码再编译成机器码。其目的就是一次编译所有py变为pyc,直接调用加快程序调用速度。
解释器:pypy。
运行方式:命令行下使用pypy命令运行
c.其他Python:
-
- Jyhton:
Jython是运行在java平台上的python解释器,可以直接把python代码编译成java字节码执行。
- IronPython:
IronPython和Jython类似,只不过IronPython是运行在微软.net平台上的python解释器。可以直接把python代码编译成.net字节码执行。
- Jyhton:
-
- RubyPython、Brython ..
ps.所以目前python对于所有主流语言都有很好的兼容,虽然如此,如果要和java或.net等平台交互,最好的方式还是通过网络调用交互,以此确保各各程序之间的独立性。
ps.PyPy,在Python的基础上对Python的字节码进一步处理,从而提升执行速度!
二、 python安装与执行
前面说了这么多,下面开始正式学习python了。
1、安装:
1、下载安装包
https://www.python.org/downloads/
2、安装
默认安装路径:C:python27
3、配置环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】
如:原来的值;C:python27,切记前面有分号
2.linux安装
查看默认Python版本
python -V
1、安装gcc,用于编译Python源码
yum install gcc
2、下载源码包,https://www.python.org/ftp/python/
3、解压并进入源码文件
4、编译安装
./configure
make all
make install
5、查看版本
/usr/local/bin/python2.7 -V
6、修改默认Python版本
mv /usr/bin/python /usr/bin/python2.6
ln -s /usr/local/bin/python2.7 /usr/bin/python
7、防止yum执行异常,修改yum使用的Python版本
vi /usr/bin/yum
将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.6
2、Hello world!程序
a.创建helloworld.py文件(pyhton程序,一般为.py结尾)
#!/usr/bin/env python
#解释器调用路径
# -*- coding:utf-8 -*-
#声明解释器编码
#程序执行
print('hello world!')
b.执行方式
-
- windows
- "D:Program FilesPython35python.exe" helloword.py #直接文件执行(以后运行程序多为此方式)
- "D:Program FilesPython35python.exe" #进入解释器执行print('helloword!')
- linux
- python helloword.py #直接文件执行(以后运行程序多为此方式)
- ptyhon #进入解释器执行print('helloword!')
- windows
ps.文件头部要加#!/user/bin/evn python及chmod +x helloword.py
然后./helloword.py实行。
3、编码格式(作用:声明编码格式)
可以让计算机直接认识的语言,其实只有汇编语言,即0和1的代码。且计算机是美国人发明的,因此,最早只有英文加特殊字符共127位字母与0和1代码进行一一对应。而美国人觉得够用了2^7 = 128不够他们扩展的,所以采用2^8 =256的内存空间(单位为‘字节’, 即256字节),够美国人用的了。
这就是最早的编码ASCII码。显然,256位字符不够中文用的,中国人也想用,怎么办呢?显然聪明的中国人想到了办法,通过在做一张新的表并把新表通过取ASCII码的几位映射到ASCII码中使用。这就是GBK。有21003字符,2字节一个汉字。
全世界人民都想使用电脑,于是个个国家的编码应运而生,日本shift_JTS,韩国EUC-kr等等。中国身为共产主义多民族国家,不能只搞汉语啊,体现民族平等嘛,于是把满文,回文等等的文字也写了新的编码GB2312.有27484字,2字节一个汉字
国际标准组织一看,世界居然为了编码乱搞,冲突不断,乱码丛生。因此unicode诞生了,把所有语言统一到一个字符编码中,unicode也因此被称为万国码。最少用2个字节表示1个字符。
这时,美国不干了,为什么我建立的计算机,被你们乱改一通,最后我一个字符搞定的事,被你们改成了2个字符,我本来存100MB的东西,莫名其妙变成了200MB。不行,于是utf-8诞生了,utf-8是对uniccode的优化压缩。英文字符占1个字符,欧洲字符占2个字符,中文占3个字符……, 故utf-8又称可变字符编码。
ps.字符编码总结:
| 编码名 | 占用字节(1中文字符) | python版本(默认) |
| ASCII | 没有中文 | python2 |
| GBK | 2个字节 | 无 |
| unciode | 3个字节 | 无 |
| utf-8 | 3个字节 | python3 |
ps.二进制换算:
-
- 最小计算机表示单位为bit(位)
- 8bit = 1byte(字节,最小存储字节)
- 1024byte = 1MB(兆) MB--〉GB--〉TB --〉PB
三、pycharm简单设置及使用
1、使用:
a、创建项目:file ---> new project
b、新建文件夹:右击要创建文件夹的项目或上级目录 ----〉new ---〉directory
c、新建文件:右击要创建文件夹的项目或上级目录 ----〉new ---〉file
d、运行文件:要执行的.py文件内容---〉右击---〉run xx.py
2、文件编码:
file ---->default settings --->editor --->file encodings
3、程序文件模版:
file ---->default settings --->editor --->file and code templates
4、改变字体大小:
file ----〉settings ----〉editor ---> General ---〉mouse
四、注释使用及.pyc文件
1、python文件注释:
# 单行注释
''' '''' 多行注释
2、.pyc文件:
.pyc文件存储的是介于0101计算机语言和我们写的文件之间的语言。是有python解释器根据我们编写的代码自动生成的文件。具体可查看, 注1
五、python变量(初识)
1、变量命名规则:
a.字母
b.数字(不能开头)
c.下划线
ps.硬性规定,命名必须是字母,数字,下划线,且不能以数字开头。
软性规则,以下划线分割
2、实例:
a.写法: age_of_oldboy = 60
b.命名潜规则:age_of_oldboy 普通变量
Age_of_oldboy 首字母大写,一般为类
AGE_OF_OLDBOY 一般为常量写法
六、python用户交互(输入输出):
1、输入
v = input('>>>')
import getpass
v = input('>>>')
2、输出
print('input', v)
3、实例:
'''
输入,输出
'''
#输入终端隐藏,pycharm不好使
import getpass
#正常输入,显示
name = input('name:')
password = getpass.getpass('password:')
age = 18
#正常输出
print(name, password, age)
七、if条件语句
1、if...else...结构
a.含义:
if 条件:
条件成功,执行
else:
条件失败,执行
b.实例:
#!/usr/bin/python
#-*- coding:utf-8 -*-
## 用户登陆(三次机会重试)
user="tianyou.zhu"
password="tianyou123"
for i in range(3):
user_input= input("请输入你的名字:")
pass_input=input("请输入你的密码:")
if user_input ==user and pass_input==password:
print ("登陆成功")
break
else:
print ("登陆失败,请重新输入")
2、if ...elif ... else ...结构
a.含义:
if 条件:
if条件成功,执行
elif 条件:
elif条件成功,执行
elif 条件:
elif条件成功,执行
....
else:
上述条件都失败,执行
b.实例:
username = input('>>>')
if username == 'tianyou.zhu':
print('普通管理')
elif username == 'a':
print('超级管理')
elif username == 'b':
print('人')
elif username == 'c':
print('装逼犯')
else:
print('再见...')
print('end')
八、循环语句(while & for)
1、while循环
a.结构
while 条件:
continue #立即执行下一个循环
break #跳出当前while的所有循环
else: #while条件不成立执行
b.实例1:1,2,3,4,5,6, 8, 9, 10 打印
#!/usr/bin/python
#-*- coding:utf-8 -*-
#1、使用while循环输入 1 2 3 4 5 6 8 9 10
#i=1
#while True:
# if i ==7:
# i=i+1
# continue
# print (i)
# i= i +1
# if i == 11:
# break
for i in range(11):
if i==7:
continue
print (i)
c.实例2:while 计算1到100的和
#!/usr/bin/python
#-*- coding:utf-8 -*-
#求1-100的所有数的和
val = 0
i=1
while i<101:
val = val+i
i= i +1
print (val)
a = 0
b = 1
for i in range(100):
a =a+b
b=b+1
print (a)
d.实例3:求1-2+3-4+5 ... 99的所有数的和
#!/usr/bin/python
#-*- coding:utf-8 -*-
#5、求1-2+3-4+5 ... 99的所有数的和
#value = 0
#i = 1
#while i<100:
# if i % 2 == 1:
# # value = value + i
# value += i
# else:
# # value = value - i
# value -= i
# i += 1 # i = i + 1
#print(value)
e.实例4:用户登陆(三次机会重试)
#!/usr/bin/python
#-*- coding:utf-8 -*-
## 用户登陆(三次机会重试)
user="tianyou.zhu"
password="tianyou123"
for i in range(3):
user_input= input("请输入你的名字:")
pass_input=input("请输入你的密码:")
if user_input ==user and pass_input==password:
print ("登陆成功")
break
else:
print ("登陆失败,请重新输入")
九、运算符
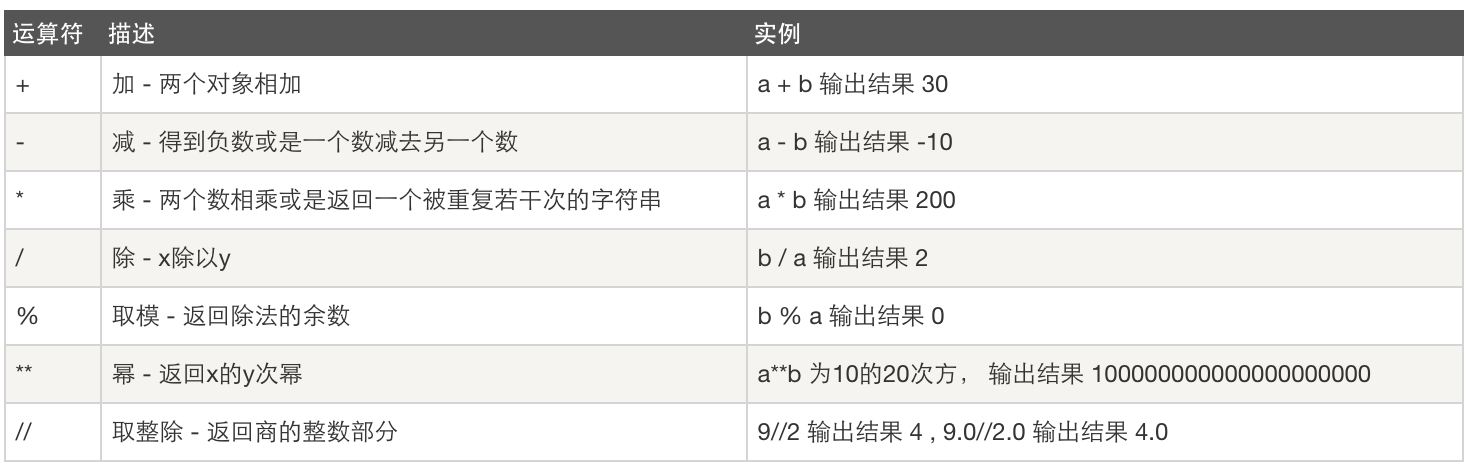
1、算术运算符:
2、比较运算:

3、赋值运算:

4、逻辑运算:

5、成员运算:

6、身份运算:

7、位运算:

a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print "Line 1 - Value of c is ", c
c = a | b; # 61 = 0011 1101
print "Line 2 - Value of c is ", c
c = a ^ b; # 49 = 0011 0001 #相同为0,不同为1
print "Line 3 - Value of c is ", c
c = ~a; # -61 = 1100 0011
print "Line 4 - Value of c is ", c
c = a << 2; # 240 = 1111 0000
print "Line 5 - Value of c is ", c
c = a >> 2; # 15 = 0000 1111
print "Line 6 - Value of c is ", c
补充要点:
a. i += 1 等同于 i = i + 1。同理*= -= 等赋值运算符都为该系列。
b. 逻辑运算,从左往右一个一个看,先算()内的数值。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
逻辑运算
'''
#1正确
if 1 == 1 or 1 > 2 and 1 == 4:
print('正确')
else:
print('错误')
#2错误
if 1 == 1 and 1 > 2 or 1 == 4:
print('正确')
else:
print('错误')
#3错误
if 1 == 0 and 1 > 2 or 1 == 4:
print('正确')
else:
print('错误')
#4错误
if 1 == 0 and (1 < 2 or 1 == 4):
print('正确')
else:
print('错误')
#5错误
if 1 == 0 and 1 > 2 or 1 == 4:
print('正确')
else:
print('错误')
c.成员运算
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
成员运算符
'''
content = "Alex 前几天去泰国玩姑娘,一不小心染上了病,他的内心活动是,真该多来几个"
if "前几天去" in content:
print('包含敏感字符')
else:
print(content)
十、python数据类型初识(int,bool,str,list,dict)
type()查看变量类型。
1、int(整形)
a.创建
b.转换
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
int(整形)
a.创建
b.转换
'''
#创建
age = 19
age1 = int(19)
print(age,age1)
#转换
age2 = '19'
print(type(age2))
#isdigit()判断是否是一个数字,int()只能转数字,不能转字母、中文等。会报错
if age2.isdigit(age2):
int(age2)
print(('tpye:%s age2:%d') % (type(age2), age2))
2、bool(布尔值)
a.创建
b.转换
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
bool(布尔值)
a.创建
b.转换
'''
#创建
a = True
b = False
#转换
#数字转换,只有0是False,其他True
#字符串, 只有""是False,其他True
#其他,待续……
a1 = 0
a2 = 100
a3 = -100
a1_bool = bool(a1)
a2_bool = bool(a2)
a3_bool = bool(a3)
print('a1 %s:%s bool_type:%s'%(a1,a1_bool, type(a1_bool)))
print('a2 %s:%s bool_type:%s'%(a2,a2_bool, type(a1_bool)))
print('a3 %s:%s bool_type:%s'%(a3,a2_bool, type(a1_bool)))
b1 = ''
b2 = 'fafa'
b3 = 'AFSD@'
b1_bool = bool(b1)
b2_bool = bool(b2)
b3_bool = bool(b3)
print('b1 %s:%s bool_type:%s'%(b1,b1_bool, type(a1_bool)))
print('b2 %s:%s bool_type:%s'%(b2,b2_bool, type(a1_bool)))
print('b3 %s:%s bool_type:%s'%(b3,b3_bool, type(a1_bool)))
'''
结果:
a1 0:False bool_type:<class 'bool'>
a2 100:True bool_type:<class 'bool'>
a3 -100:True bool_type:<class 'bool'>
b1 :False bool_type:<class 'bool'>
b2 fafa:True bool_type:<class 'bool'>
b3 AFSD@:True bool_type:<class 'bool'>
'''
3、str(字符串)
a.创建
b.转换
c.拼接
d.格式化
e.是否在子序列中
f.移除空白.strip()
g.分割.split('分割符',步长)
h.长度len()
i.索引[]
j.切片[开始:结束:步长]
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
str(字符串)
a.创建 b.转换 c.拼接 d.格式化 e.是否在子序列中 f.移除空白
g.分割 h.长度 i.索引 j.切片
'''
#创建
name = 'tianyou.zhu'
name1 = str('tianyou.zhu')
print('name: %s tpye:%s
name1:%s tpye:%s
' %(name,type(name),name1,type(name1)))
#转换
age = 19
age_str = str(age)
print('age_str:%s tpye:%s' % (age, age_str))
#字符串拼接
name2 = 'alex'
gender = '女'
new_str = name2 + gender
print(new_str)
#字符串格式化,使用占位符%s(待续...)
name3 = '我叫李杰,性别:%s,我今年%s岁,我在说谎!'
new_str2 = name3 %('男',19,)
print(new_str2)
name4 = '我叫李杰,性别:%s,我今年%s岁,我在说谎!' %('男',19)
print(name4)
#判断子序列是否在其中
content = "Alex 前几天去泰国玩姑娘,一不小心染上了病,他的内心活动是,真该多来几个"
if "前几天去" in content:
print('包含敏感字符')
else:
print(content)
#移除空白
val = " alex "
print(val)
new_val = val.strip() # 左右去
# new_val = val.lstrip()# 左边去
# new_val = val.rstrip() # 右边去
print(new_val)
#分割.split('分隔符',步长)
user_info = "alex|sb123|9"
v = user_info.split('|')
# v = user_info.split('|',1)
# v = user_info.rsplit('|',1) #右分割
# v = user_info.lsplit('|',1) #左分割
print(v)
#长度(字符)python2,中文按2字节算,python按,中文按1字符算
val = "李杰nb"
v = len(val)
print(v)
'''
结果:
4
'''
#索引
val = "李杰mb"
v = val[0]
print(v)
val = input('>>>')
i = 0
while i < len(val):
print(val[i])
i += 1
'''
输入:dd
结果:
d
d
'''
#切片
name = '我叫李杰,性别我今年岁,我在说谎!'
print(name[0])
print(name[0:2])
print(name[3:9])
print(name[7:])
print(name[4:-2])
print(name[-2:])
'''
结果:
我
我叫
杰,性别我今
我今年岁,我在说谎!
,性别我今年岁,我在说
谎!
'''
4、list(列表)
a.创建
b.in判断
c.索引[]
d.追加.append()
e.插入.insert()
f.删除del .remove()
g.更新
h.输出
i.长度len()
j.切片[开始:结束:步长]
创建:
a = ['alex','狗','eric',123]
a = list(['alex','狗','eric',123])
in判断:
if 'al' in a:
pass
if 'al' in a[0]:
pass
索引:
val = a[0]
长度:
val = len(a)
切片:
a = ['alex','狗','eric',123]
v = a[0::2]
print(v)
追加:
a = ['alex','狗','eric',123]
a.append('xxoo')
print(a)
插入:
a = ['alex','狗','eric',123]
a.insert(0,'牛')
print(a)
删除:
a = ['alex','eric','狗','eric',123]
# a.remove('eric')
del a[0]
print(a)
更新:
a = ['alex','eric','狗','eric',123]
a[1] = '阿斯顿发送到'
print(a)
For循环:
a = ['alex','eric','狗','eric',123]
for item in a:
print(item)
# break
# continue
5、dict(字典)
a.创建
b.索引
c.增加&更新
d.删除
e.输出
- 创建
v = {
'name': 'alex',
'password': '123123'
}
# 常用操作
# 索引获取值
# n = v['name']
# print(n)
# 增加,无,增加;有,修改
# v['age'] = 19
# print(v)
# 删除
# del v['name']
# print(v)
# 循环
# for item in v.keys():
# print(item)
# for item in v.values():
# print(item)
# for key,val in v.items():
# print(key,val)
print(len(user_dict))
PS: 相互嵌套
user_dict = {
'k1': 'v1',
'k2': {'kk1':'vv1','kk2':'vv2'},
'k3': 123,
'k4': ['alex','eric',['a','b','c'],'李杰',{'k11':'vv1'}],
}
user_dict['k4'][2].append('123')
user_dict['k4'][4]['n'] = '过啥龙'
应用:
user_list = [
{'name':'alex','pwd':'123123','times':1},
{'name':'eric','pwd':'123123','times':1},
{'name':'tony','pwd':'123123','times':1},
]
user = input('用户名:')
pwd = input('密码:')
for item in user_list:
if user == item['name'] and pwd == item['pwd']:
print('登录成功')
break
list & dict嵌套
a.实例1:相互嵌套
#!/usr/bin/env python 2 # -*- coding:utf-8 -*-
3 4 5 ''' 6 dict&list相互嵌套实例1 7 ''' 8 9 user_dict = { 10 'k1': 'v1', 11 'k2':{'kk1':'vv1', 'kk2':'vv2'}, 12 'k3':123, 13 'k4':[ 'jack', ['a', 'b', 'c'], '李杰',{'k1':'v1'}] 14 } 15 print('dict: %s' % user_dict) 16 17 #添加dict --〉 list的元素 18 user_dict['k4'][2].append('123') 19 print('add_dict_list: %s' % user_dict) 20 21 #添加dict ---〉 dict的元素 22 user_dict['k4'][4]['k2'] = 'v1' 23 print('add_dict_dict: %s' % user_dict)
b.实例2:多用户密码登陆
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
dict_list多用户登陆
'''
user_list = [
{'name':'alex','pwd':'123123','times':1},
{'name':'eric','pwd':'123123','times':1},
]
user = input('用户名:')
pwd = input('密码:')
for item in user_list:
if user == item['name'] and pwd == item['pwd']:
print('登录成功')
1、注解1:
a. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
b.图例:
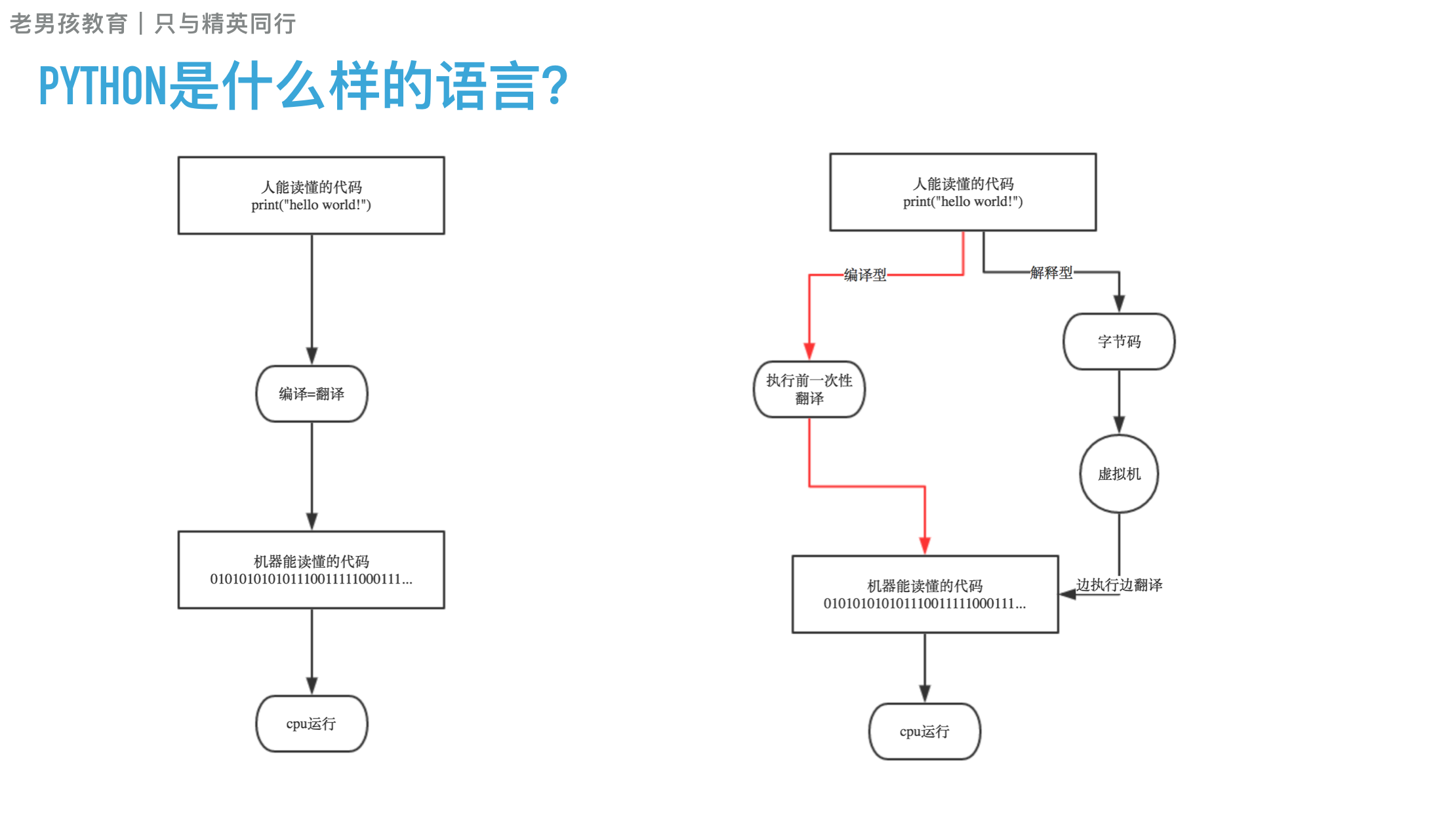
c.编译型vs解释型
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
d.更多解释详见
http://www.cnblogs.com/alex3714/articles/5465198.html
http://www.cnblogs.com/wupeiqi/articles