解决过拟合和欠拟合的思路
过拟合
- 获取更多的数据量
有时数据量大并没有帮助
通常数据量越大,学习模型训练得越好,但是即使这样,也应该做一些初步实验(使用学习曲线)来确保数据量越大,训练越好。(如果一开始就用大量的数据来训练模型,将会耗费大量的时间:收集数据,训练模型)
- 增大正则化系数
- 减少特征量(不太推荐)
细心的从已有的特征量中选出一个子集
可以手工选择,也可以用一些降维( dimensionality reduction)技术,但降维也不一定缓解过拟合
欠拟合
- 增加额外的特征量
有时并不起作用
仔细考虑数据集,是否遗漏了一些重要的特征量(可能花费较多的时间)
添加的特征量可能只是训练集的特征,不适合全体数据集,可能会过拟合
- 添加多项式的特征量
- 减少正则化参数
线性模型的权重分析
线性模型:
Linear Regression ,Logistic Regression , LinearSVM
线性模型得到的是一系列的权重,我们可以将权重提取出来,观察哪些特征的权重系数是比较大的
考虑将这些权重大的特征和其他特征做一个组合,如房屋面积和几居室,作为新的特征加入到训练数据中,
也可以将这些特征进行分拆,如房屋面积分拆成客厅面积、厨房面积、卧室面积,或者是分拆部分面积和总面积的比值,作为新的特征加入到训练数据中。
bad-case分析
我们可以查看哪些训练样本分错了,这些被分错的样本是由哪部分特征所决定的,
然后我们可以查看这些被分错的样本的决定性特征是不是很相似的,
思考哪些特征值的我们去重点关注。
模型融合
stacking
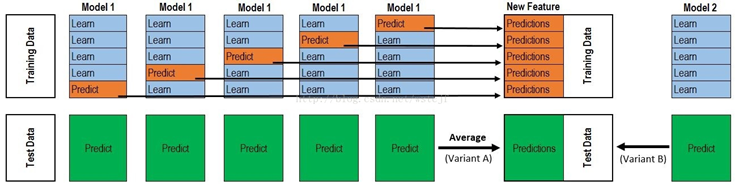
stacking 原理:
- 假设我们使用N个模型进行融合
- 使用一个模型进行如下操作:
将训练集划分为k份,使用k-1份的数据作为训练集,另外一份数据作为验证集,使用训练集进行模型训练,将训练的模型对验证集和测试集进行预测,我们使用k折交叉验证,得到k个模型,这k个模型是不同的,因为训练集是不同的,这k个模型对验证集的预测堆叠起来,其维度是(训练集样本数,1),对测试集的预测结果做一个平均,维度变为(测试集样本数,1)
- 然后对另外N-1个模型使用上面同样的处理方法。
- 将每一个模型得到的验证集的预测结果合起来作为新的训练集,器维度是(训练集样本数,N),输入到模型进行训练。将每一个模型得到的测试机的预测结果合并起来,其维度是(测试集的样本数,N),作为新的测试集。
代码实现:
stack_model = [svm,lr,nn,xgb,lgb]
## train_data 表示训练集,train_label 表示训练集的标签,test_data表示训练集
ntrain = train_data.shape[0] ## 训练集样本数量
ntest = test_data.shape[0] ## 测试集样本数量
train_stack = np.zeros(ntrain,n) ## n表示n个模型
test_stack = np.zeros(ntest,n) ##
kf = kfold.split(train_data, train_label)
for i,model in enumerate(stack_model):
for j, (train_fold, validate) in enumerate(kf):
X_train, X_validate, label_train, label_validate =
train_data[train_fold, :], train_data[validate, :], train_label[train_fold], train_label[validate]
model.fit(X_train,label_train)
train_stack[validate,i] = model.predict(X_validate)
test_stack[:,i] = model.predict(test_data)
### 假设就只有两层,那么最后预测:
final_model = xgb() ## 假设第二层我们还是用xgb吧,这个地方也是简写,仅仅表示这个地方是xgb模型
final_model.fit(train_stack,train_label)
pre = final_model.predict(test_stack)
blending
Blending与Stacking大致相同,只是Blending的主要区别在于:例如从原始训练数据中选取80%作为训练集,另外20%作为验证集,使用训练好的模型预测验证集。这样N个模型就可以得到第二阶段的训练集,其维度是(原始数据集样本数的20%,N),然后使用这些训练集训练出来一个新的模型。
测试集的处理同stacking,最终得到的测试集的维度是(测试集的样本数,N)
Blending的优点:
1.比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
2.避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
3.在团队建模过程中,不需要给队友分享自己的随机种子
缺点在于:
1.使用了很少的数据(第二阶段的blender只使用training set10%的量)
2.blender可能会过拟合(其实大概率是第一点导致的)
3.stacking使用多次的CV会比较稳健
对于实践中的结果而言,stacking和blending的效果是差不多的,所以使用哪种方法都没什么所谓,完全取决于个人爱好。
bagging和boosting
这些算法在其它文章中已经描述,这里不再重述。
超参数估计
网格搜索
from sklearn.model_selection import GridSearchCV
from sklearn import svm
clf = svm.SVC()
param_grid = [{'C': [1, 10, 100, 1000], 'kernel': ['linear']}, { 'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']}]
grid = GridSearchCV(clf, param_grid, cv=10)
grid = grid.fit(X_train, y_train)
grid_search.best_score_
grid_search.best_estimator_.get_params()
网格搜索支持并行化:
grid_search = GridSearchCV(pipeline, parameters, cv=5, n_jobs=-1)