关联规则
1、基本概念
项集:是一个由项目构成的集合
频繁项集:项集的支持度满足给定的阈值,就称该项集是频繁项集
关联规则反应了一个事物和其他事物的相互依存性和关联性
支持度的定义:support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数。
自信度的定义:confidence(X-->Y) = |X交Y|/|X| = 集合X与集合Y中的项在一条记录中同时出现的次数/集合X出现的个数 。
这里定义的支持度和自信度都是相对的支持度和自信度,不是绝对支持度,绝对支持度abs_support = 数据记录数N*support。
支持度和自信度越高,说明规则越强,关联规则挖掘就是挖掘出满足一定强度的规则。
2、Apriori算法
两条性质:
1)频繁项集的所有非空子集为频繁项集
2)非频繁项集的超集一定是非频繁项集
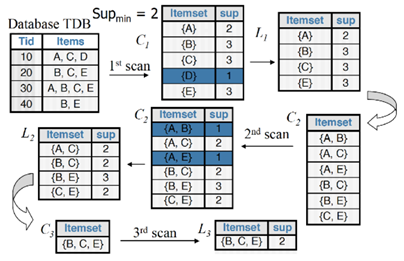
算法步骤:
连接步:为了找Lk,通过将Lk-1与自身连接产生候选k项集的集合,即Ck
剪枝步:Ck是Lk的超集,通过与给定支持度的阈值比较,大于阈值的项集保存在Lk中
优缺点
算法优点:简单、易理解、数据要求低
算法缺点:I/O负载大,产生过多的候选项目集
应用领域:消费市场价格分析,入侵检测,移动通信领域
3、FP-Tree算法
FP-Tree算法的特性:
1)FP-Tree算法只进行2次数据库扫描
2)没有候选集
3)直接压缩数据库成一个频繁模式树
4)通过这颗树生成关联规则
FP-Tree算法步骤:
1、利用事务数据库中的数据构造FP-Tree
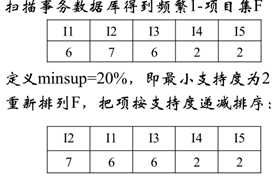
1)扫描数据库一次,得到频繁1-项集
2)把项按支持度递减排序
3)再一次扫描数据库,建立FP-Tree
Tip:
FP-Tree结构的优点:
(1)完备
1)不会打破交易中的任何模式
2)包含了频繁模式挖据所需的全部信息
(2)紧密
1)去处不相关信息----不包含非频繁项
2)支持度降序排列:支持度高的项在FP-Tree中共享的机会也高
3)决不会比原数据库大
2、从FP-Tree中挖掘频繁模式
根据事务数据库D和最小支持度min_sup,调用建树过程建立FP-Tree
if(FP-Tree为简单路径)
将路径上支持度计数大于等于min_sup的节点任意组合,得到所需的频繁模式
else
初始化最大频繁模式集合为空
按照支持频率升序,以每个1-频繁项为后缀,调用挖掘算法来挖掘最大频繁模式集
根据最大频繁模式集合中最大频繁模式,输出全部的频繁模式
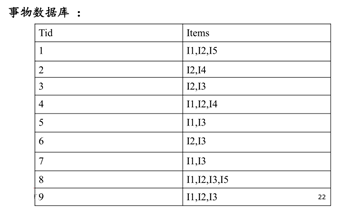
举例说明:
步骤一:
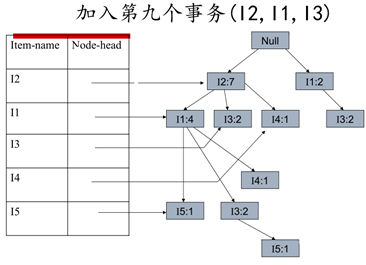
步骤二:
1、按照Iter-name的倒序,先考虑I5,得到条件模式基
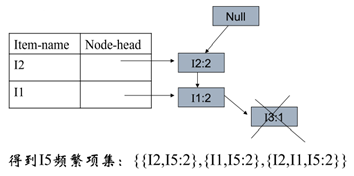
2、接着考虑I4,得到条件模式基
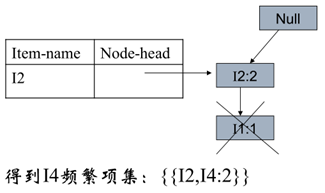
3、接着考虑I3,得到条件模式基

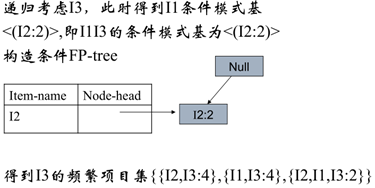
4、按照上述方法,一直进行下去直到完成。
FP-Tree算法的优缺点:
优点:
1)FP-Tree算法只需对事物数据库进行二次扫描
2)避免产生大量候选集
缺点:
1)要递归生成条件数据库和条件FP-Tree,所以内存开销大
2)只能用于挖掘单维的布尔关联规则。