一、列表的定义及操作
列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作。
1、列表的格式及赋值
列表,使用中括号括起来,元素之间用逗号隔开,列表中的元素具有明确的位置,不同位置的元素可以相同(数值相同,字符串相同都可以)
空列表:[]
列表的赋值:names = ["zhangsan","lishi","wangwu","zhaoliu"]
列表的切片:切片,通过下标来选取列表中所需元素的一种方式,下标可以通过使用冒号表示范围,在表示范围时有‘顾前不顾后的原则’。
>>> name=[0,1,2,3,4] >>> print(name[0:3]) [0, 1, 2] >>> print(name[:-1]) [0, 1, 2, 3] >>> print(name[-1]) 4 >>> print(name[-3:-1]) [2, 3] >>> print(name[-3:]) [2, 3, 4] >>>
代码的注意点:[-3:-1]与[-3:]两种形式的区别。
2、列表的插入与追加
插入:list.insert(n,'infor')通过指定下标,将新的元素加入到指定位置,此时原有的元素会向后移动(下标+1)。
追加:list.append('infor')在列表的最后新增一个元素,不会影响原有的列表中已有的元素的位置。
>>> print(name) [0, 111, 1, 2, 3, 4] >>> name.append(666) >>> print(name) [0, 111, 1, 2, 3, 4, 666] >>> name2=['a','b','c'] >>> name.insert(0,name2) >>> print(name) [['a', 'b', 'c'], 0, 111, 1, 2, 3, 4, 666] >>>
代码的注意点:列表的下标是从0开始编号。支持列表嵌套列表的方式,append、insert方式都能给列表新增列表或字典类型的元素。
3、列表的删除方法
列表的清空:list.clear()
>>> name=[0,1,2,3,4] >>> print(name) [0, 1, 2, 3, 4] >>> name.clear() >>> print(name) []
删除元素的三种方式
- list.remove('keyword'):指定元素内容删除,需要注意到的是如果有多个位置的元素内容一样,那么只会删除第一个匹配到的元素。
- del list[n]:通过下标指定位置删除。
- list.pop():不指定位置,直接删除当前列表最好一位元素。
>>> name=['aaa','bbb','ccc','ddd'] >>> name.pop() 'ddd' >>> print(name) ['aaa', 'bbb', 'ccc'] >>> name.append('bbb') >>> name.remove('bbb') >>> print(name) ['aaa', 'ccc', 'bbb'] >>> del name[0] >>> print(name) ['ccc', 'bbb'] >>>
4、列表内容的修改方式
修改列表内容的方式比较简单,就是通过指定下标复制的方式来实现。
name[n]='value'
>>> print(name) ['ccc', 'bbb'] >>> name[0]='new' >>> print(name) ['new', 'bbb'] >>>
5、列表的查询
下标(位置)查询:list.index('value')
次数查询(统计):list.count('value')
>>> print (name) ['new', 'bbb', 'ccc', 'eee', 'ddd', 'fff', 'bbb', 'bbb'] >>> name.index('bbb') 1 >>> name.count('bbb') 3 >>> name.index('aaa') Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: 'aaa' is not in list
>>> name.count('aaa')
0
此代码的注意点:index查询下标的时候,如果一个列表中存在多个相同值的元素,index的查询结果为第一次出现的这个值的元素的位置。如果列表中不存在此元素,会有报错信息。通过count来统计出现次数,值不存在则统计结果为0
6、列表的扩展、取反、排序
扩展:list.extend(listnew),将另外一个列表的元素合并到这个列表中
>>> print(name) ['bbb', 'bbb', 'fff', 'ddd', 'eee', 'ccc', 'bbb', 'new'] >>> name2=[1,2,3,4,5,'aaa'] >>> name.extend(name2) >>> print(name) ['bbb', 'bbb', 'fff', 'ddd', 'eee', 'ccc', 'bbb', 'new', 1, 2, 3, 4, 5, 'aaa']
取反:list.reverse(),将列表中的元素倒序排列,第一个变成最后一个,依此规律转换。
排序:list.sort(),按特殊字符、数字、大写、小写的顺序排序
>>> list.sort() >>> print(list) ['%bc', '*bc', '1', '111', '2', '@bc', 'ABC', 'Abc', '_list'] >>> list.reverse() >>> print(list) ['_list', 'Abc', 'ABC', '@bc', '2', '111', '1', '*bc', '%bc'] >>>
此代码的注意点:排序的时候,排序的顺序为特殊字符、数字、大写字母、小写字母。另外一些字符实际不满足此情况(此处不深究),如@、_这两个字符
7、列表的几种打印方式
逐行输出内容及下标:enumerate与index的对比,建议使用enumerate。
list=['aa','bb','cc','dd','ee','aa'] list2=[[1,'a'],[2,'b'],[3,'c'],[4,'d']] for i in list: print (list.index(i),i) print(''.center(50,'*')) for i,j in enumerate(list): print(i,j) print(''.center(50,'*')) for x,y in enumerate(list2): print (x,y) print(''.center(50, '*')) #for x,y,z in enumerate(list2): # print(x,y,z)
------------------------------------------------------------------------------------------
0 aa
1 bb
2 cc
3 dd
4 ee
0 aa
**************************************************
0 aa
1 bb
2 cc
3 dd
4 ee
5 aa
**************************************************
0 [1, 'a']
1 [2, 'b']
2 [3, 'c']
3 [4, 'd']
**************************************************
该程序的注意点:使用index来显示下标时如果存在重复值的元素会显示第一次出现的下标,导致无法正确显示依次出现的下标。故建议使用emuerate。另,使用emuerate时,不能再继续赋值变量来展开嵌套列表的值。
逐行输出列表中的所有元素:对比for i in list 与 for i in list的区别
list=[1,2,3,4,5] list2=[[1,'a'],[2,'b'],[3,'c'],[4,'d']] list3=[[1,'a','xxx'],[2,'b','yyy'],[3,'c','zzz'],[4,'d','333']] for i in list : print(i) print(''.center(50,'-')) for i in list2: print(i) for i,j in list2: print('---',i,'---',j) for x,y,z in list3: print('---', x, '---', y,'---',z) for x, y in list3: print('---', x, '---', y)
*****************************************************************************************
1
2
3
4
5
--------------------------------------------------
[1, 'a']
[2, 'b']
[3, 'c']
[4, 'd']
--- 1 --- a
--- 2 --- b
--- 3 --- c
--- 4 --- d
--- 1 --- a --- xxx
--- 2 --- b --- yyy
--- 3 --- c --- zzz
--- 4 --- d --- 333
Traceback (most recent call last):
File "D:/python/tmp.py", line 13, in <module>
for x, y in list3:
ValueError: too many values to unpack (expected 2)
二、元组(tuple)的定义及操作
元组其实跟列表差不多,也是存一组数。它一旦创建,便不能再修改,所以又叫只读列表
语法:
tuple=(1,2,3,4)#列表为中括号,元组为小括号
它只有2个方法,一个是count,一个是index
三、浅copy与深copy的对比
深copy完全独立,浅copy藕断丝连
list=[1,2,3,'hello','hi',[1,'a'],[2,'b'],{'a1':'AAA'},{}] list2=list.copy() print(list) print(list2) list[0]=11111 list2[1]=22222 print(list) print(list2) list[3]='hello world' list2[4]='hi man' print(list) print(list2) list[5][1]=['ccc'] list[6][0]=[444] print(list) print(list2) list[6]=['New','list1'] list2[5]=['new2','list2'] print(list) print(list2) list[7]['a1']=('copy1') list2[8]={"xxx":'xxxx2'} print(list) print(list2)
-----------------------------------------------------------------
[1, 2, 3, 'hello', 'hi', [1, 'a'], [2, 'b'], {'a1': 'AAA'}, {}]
[1, 2, 3, 'hello', 'hi', [1, 'a'], [2, 'b'], {'a1': 'AAA'}, {}]
[11111, 2, 3, 'hello', 'hi', [1, 'a'], [2, 'b'], {'a1': 'AAA'}, {}]
[1, 22222, 3, 'hello', 'hi', [1, 'a'], [2, 'b'], {'a1': 'AAA'}, {}]
[11111, 2, 3, 'hello world', 'hi', [1, 'a'], [2, 'b'], {'a1': 'AAA'}, {}]
[1, 22222, 3, 'hello', 'hi man', [1, 'a'], [2, 'b'], {'a1': 'AAA'}, {}]
[11111, 2, 3, 'hello world', 'hi', [1, ['ccc']], [[444], 'b'], {'a1': 'AAA'}, {}]
[1, 22222, 3, 'hello', 'hi man', [1, ['ccc']], [[444], 'b'], {'a1': 'AAA'}, {}]
[11111, 2, 3, 'hello world', 'hi', [1, ['ccc']], ['New', 'list1'], {'a1': 'AAA'}, {}]
[1, 22222, 3, 'hello', 'hi man', ['new2', 'list2'], [[444], 'b'], {'a1': 'AAA'}, {}]
[11111, 2, 3, 'hello world', 'hi', [1, ['ccc']], ['New', 'list1'], {'a1': 'copy1'}, {}]
[1, 22222, 3, 'hello', 'hi man', ['new2', 'list2'], [[444], 'b'], {'a1': 'copy1'}, {'xxx': 'xxxx2'}]
此代码的注意点:此处需要明白python中变量在内存中的形式和c在内存中形式的区别,通过此来深入理解深浅copy,详见 https://www.cnblogs.com/Eva-J/p/5534037.html。写的很详细。我在此处暂时不废话了。快去观望大佬的文章。
四、字符串操作
字符串,简要的说就是一段文字,表示形式为name = "bank of china"
1、统计、判断与查询
统计字母或字段出现的次数:str.count('word')
>>> str_tmp='my teacher is alex. i want to dry a cup of great tea.' >>> str_tmp.count('a') 6 >>> str_tmp.count('ea') 3 >>> str_tmp.count('tea') 2 >>> str_tmp.count('teacher') 1 >>> str_tmp.count('a') 6 >>> str_tmp.count('alex') 1 >>>
查询关键字出现的位置,注意rfind与find的区别
>>> str_tmp='my teacher is alex. i want to dry a cup of great tea.' >>> print(str_tmp.find('a')) 5 >>> print(str_tmp.find('y')) 1 >>> print(str_tmp.find('alex')) 14 >>> print(str_tmp.rfind('alex')) 14 >>> print(str_tmp.rfind('ea')) 50 >>> print(str_tmp.find('ea')) 4 >>>
该代码的注意点:多次出现的字段,使用find为显示第一次出现的位置,使用rfind为最后一次出现的位置。如果字段在字符串中只出现了一次,则find与rfind显示的结果一样。
字符串的切片,与列表的切片一致顾前不顾后
>>> print (str_tmp[:-1]) my teacher is alex. i want to dry a cup of great tea >>> print (str_tmp[:]) my teacher is alex. i want to dry a cup of great tea. >>> print(type(str_tmp)) <class 'str'> >>>
2、字符串的判断
- 字符串结尾的判断endswith()
>>> print(str1) Hello World Abc >>> print(str1.endswith('bc')) True >>> print(str1.endswith('c')) True >>> print(str1.endswith('ABc')) False >>> print(str1.endswith('Abc')) True >>>
- 字符类型的判断str.is*
- 是否输入的为数字(整数):用于判断输入的选项来执行程序的下一步,str.isdigit()
- 是否是空格:str.isspace()
- 全大小写的判断isupper()与islower()
- 是否是一个合理的变量名:str.isidentifier(),变量名三个条件。
- 是否为阿拉伯数字:str.alnum()此处需要注意alnum包括的大小写字母和数字但不包括符号、特殊字符
- 是否为一个数字str:isnumeric()此处不仅包含整数,这个判断不常用,一般都使用isdigit()
- 是否为一个十进制:str.isdecimal()这个也不常用
>>> print('1'.isdigit()) True >>> print(' '.isspace()) True >>> print('HELLO'.isspace()) False >>> print('HELLO'.isupper()) True >>> print('HeLLO'.isupper())#需要全大写 False>>> print('hello'.islower()) True >>> print('_niubi'.isidentifier())#下划线可以做变量开头 True >>> print('abbi'.isalnum())#阿利伯数字包括了字母 True >>> print('123'.isalnum()) True >>> print('123'.isnumeric()) True >>> print('666'.isdecimal())#建议用isdigit() True >>>
3、字符串的转换、替代与切割
首字母的转换:capitalize()与titie(),需要注意capitalize()为句子的首字母,title()为每个单词的首字母。
>>> str1='hello world' >>> str1=str1.capitalize() >>> print(str1) Hello world >>> str2='hi beijing' >>> str2=str2.title() >>> print(str2) Hi Beijing >>>
大小写的转换:upper()、lower()与swapcase(),注意的是:upper与lower为全部修改。swapcase()为大小写互换
>>> str1='just Ok!' >>> str1=str1.upper() >>> print(str1) JUST OK! >>> str2='NI hao' >>> str2=str2.lower() >>> print(str2) ni hao >>> str3='ABCdef'.swapcase() >>> print(str3) abcDEF >>>
列表转换:join(),通过join可以将列表转换为字符串
>>> print(list1) [1, 2, 3, 4, 5] >>> >>> aaa="".join(list1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: sequence item 0: expected str instance, int found >>> list2=['1','2','3','4'] >>> bbb='+'.join(list2) >>> print (bbb) 1+2+3+4 >>> ccc=''.join(list2) >>> print(ccc) 1234 >>>
定义规则转换:maketrans与translate()
>>> str1='123' >>> r=str.maketrans('123','abc') >>> str1.translate(r) 'abc' >>> print(str1) 123 >>> str1=str1.translate(r) >>> str1.upper() 'ABC' >>> print(str1) abc >>>
该代码的注意点:maketrans()为制作规则,之后translate()进行转换,如果只是转换没有做重新赋值的操作,对于变量本身是不会有影响的,包括上文的upper/lower等也是如此。
替代:使用replace()全部替换,不管有几个关键字都会被替换。
>>> str1='allllllllllllllllllllllex' >>> str1.replace('l','L') 'aLLLLLLLLLLLLLLLLLLLLLLex' >>> print(str1) allllllllllllllllllllllex >>> str1=str1.replace('l','L') >>> print(str1) aLLLLLLLLLLLLLLLLLLLLLLex >>>
切割:split()与strip(),split()可以根据指定字符来切割字符串,将字符串转换成相应的列表。strip用来去除字符串前后方的某种字符(常用的场景有‘\n’、'空格'、'#'、‘@’)来切割。
>>> str1='xiaoming#xiaofang#xiaoxue' >>> list=str1.split('#') >>> print(list) ['xiaoming', 'xiaofang', 'xiaoxue'] >>> str2='xiaoming#xiaofang#xiaoxue' >>> str2='######xiaoming#xiaofang#xiaoxue#######' >>> list2=str2.split('#') >>> print(list2) ['', '', '', '', '', '', 'xiaoming', 'xiaofang', 'xiaoxue', '', '', '', '', '', '', ''] >>> list3=str2.strip('#').split('#') >>> print(list3) ['xiaoming', 'xiaofang', 'xiaoxue'] >>>
该代码的注意点:split和strip通常结合使用,strip去除字符串开始或结束的某些字符对切割结果的影响。
4、字符串的格式输出
居中、左对齐与右对齐:center、just、rjust
>>> str1='hello' >>> print(str1.center(50,'-')) ----------------------hello----------------------- >>> print(str1.rjust(50,'-')) ---------------------------------------------hello >>> print(str1.ljust(50,'-')) hello--------------------------------------------- >>>
字符串中变量的引用:format与format_map,通常使用format,format_map为字典使用
>>> print(information_person.format(_name = "tom",_age = 18)) my name is tom, i am 18 years old >>> >>> print(information_person.format_map({"_name":"alex","_age":33})) my name is alex, i am 33 years old
五、字典的概念及操作
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
1、字典的格式:
info = {
'stu1101': "TengLan Wu",
'stu1102': "LongZe Luola",
'stu1103': "XiaoZe Maliya",
}
2、字典的两个特征特性
- 字典是无序的
- key必须是唯一的,所以字典在定义上就有去重的特性
3、字典的新增与修改
字典是无序的,不能像列表一样通过下标的方式来赋值和修改(包括查询),字典的检索方式为key,通过key关键字的方式来进行新增和修改。如果关键字存在,则修改。如果关键字不存在,则新增
>>> dic={1:'x1'}
>>> print(dic)
{1: 'x1'}
>>> dic[1]='xx1'
>>> dic['n002']='xx2'
>>> print(dic)
{1: 'xx1', 'n002': 'xx2'}
>>>
4、字典的查询与判断
值的查询:关键字查询方式和get方式(此处提一下len()的操作):list方式可以通过下标来查询出value值,字典可以通过关键字来查询出value值。
>>> list=['aaa','bbb','ccc'] >>> dic1={'n1':'aaa','n2':'bbb'} >>> dic1.get('n1') 'aaa' >>> >>> print(dic1.get('n3')) None >>> print(dic1['n1']) aaa >>> print(dic1['n3']) Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError:'n3' >>>
该代码的注意点:
字典与list相同,如果下标不存在会提示超出len,字典如果关键字不存在也会有相应的报错(keyerror)。
字典与list不同的是,字典有get的方法,用get方法查询,如果关键字存在则返回value,如果不存在返回none
长度及是否存在的判断:使用len()可以对字典中目前有多少个关键字进行判断,使用in可以判断该key是否在字典中存在,这两个方法都可以使用在列表中。
>>> list=['aaa','bbb','ccc'] >>> dic1={'n1':'aaa','n2':'bbb'} >>> len(list) 3 >>> len(dic1) 2 >>> 'aaa' in list True >>> 'aax' in list False >>> 'aaa' in dic1 False >>> 'n1' in dic1 True >>>
该代码的注意点:字典中可以用in来判断关键字是否存在,不能用in判断value是否存在
5、字典的更新与删除
更新:update(),字典的更新必须要和列表对比,列表没有update的方式,但是列表有extend()这种方式。
>>> dic1={'N001':'xxx1','N002':'xxx2','N003':'xxx3'}
>>> dic2={'N004':'xxx4','N005':'xxx5','N003':'6666'}
>>> dic1.update(dic2)
>>> print(dic1)
{'N001': 'xxx1', 'N002': 'xxx2', 'N003': '6666', 'N004': 'xxx4', 'N005': 'xxx5'}
>>> list1=['n1','n2','n3']
>>> list2=['n4','n5','n3']
>>> list1.extend(list2)
>>> print(list1)
['n1', 'n2', 'n3', 'n4', 'n5', 'n3']
>>>
该代码的注意点:字典的关键字有唯一性,字典update后,新关键字被添加,重复的关键字被修改。列表不同,列表是有序的,允许元素相同,故extend,只是按顺序添加即可
字典的清空和删除:和列表相比字典的删除操作比列表少了一种,字典有del dic[key]的方式,如果[key]不填则del整个列表。字典还能使用pop()操作,必须使用关键字,因为字典无序。字典可以使用clear()来清空。clear()方式和del方式都是直接操作,不需要重新赋值了。这一点和之前的转换不同
>>> print(dic1) {'N001': 'xxx1', 'N002': 'xxx2', 'N003': '6666', 'N004': 'xxx4', 'N005': 'xxx5'} >>> print(dic2) {'N004': 'xxx4', 'N005': 'xxx5', 'N003': '6666'} >>> dic1.pop() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: pop expected at least 1 arguments, got 0 >>> dic1.pop('N003') '6666' >>> print(dic1) {'N001': 'xxx1', 'N002': 'xxx2', 'N004': 'xxx4', 'N005': 'xxx5'} >>> del dic1['N005'] >>> print(dic1) {'N001': 'xxx1', 'N002': 'xxx2', 'N004': 'xxx4'} >>> del dic1 >>> print(dic1) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'dic1' is not defined >>> print(dic2) {'N004': 'xxx4', 'N005': 'xxx5', 'N003': '6666'} >>> dic2.clear() >>> print(dic2) {} >>>
该代码的注意点:字典的pop动作必须指定key,否则会报错。清空字典需要用clear,不能用del,del后整个字典都没有了
6、字典的转换与输出格式
字典转列表:使用item(),列表转字典,字典将会被转换为一个列表,字典中key与value的对应关系会被转换为一个元组。若字段存在嵌套,则嵌套部分会在元组中保留
>>> dicx= { 'n001':"aa", 'n002':"bb", 'n003':"ccc", } >>> print(dicx) {'n001': 'aa', 'n002': 'bb', 'n003': 'ccc'} >>> listx=dicx.items() >>> print(listx) dict_items([('n001', 'aa'), ('n002', 'bb'), ('n003', 'ccc')]) >>>
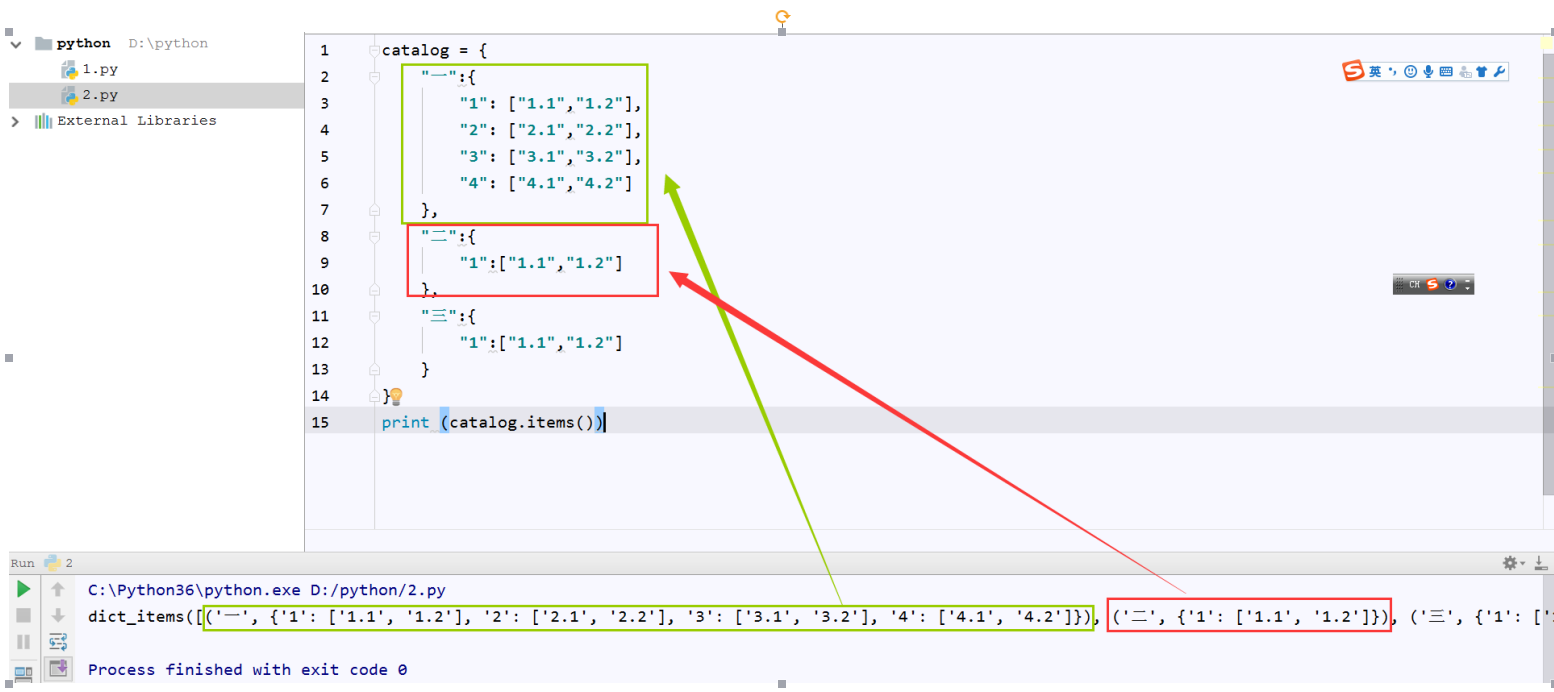
全输出:字典全输出print(dic)、key输出print(dic.keys())、value输出print(dic.values())
>>> dic1={'N001': 'xxx1', 'N002': 'xxx2', 'N004': 'xxx4', 'N005': 'xxx5'}
>>>
>>> print(dic1)
{'N001': 'xxx1', 'N002': 'xxx2', 'N004': 'xxx4', 'N005': 'xxx5'}
>>> print(dic1.keys())
dict_keys(['N001', 'N002', 'N004', 'N005'])
>>> print(dic1.values())
dict_values(['xxx1', 'xxx2', 'xxx4', 'xxx5'])
>>>
逐一输出:使用for来逐一输出。需要对比几种for的输出形式。
dic1={'N001': 'xxx1', 'N002': 'xxx2', 'N004': 'xxx4', 'N005': 'xxx5'}
for i in dic1:
print(i)
#for i , j in dic1:
# print(i,j)
for i in dic1.items():
print(i)
for i , j in dic1.items():
print (i,j)
------------------------------------------------------
N001
N002
N004
N005
('N001', 'xxx1')
('N002', 'xxx2')
('N004', 'xxx4')
('N005', 'xxx5')
N001 xxx1
N002 xxx2
N004 xxx4
N005 xxx5
此代码的注意点:使用for i 来输出字典,输出的值为关键字。使用 for i,j 来输出字典,会报错
六、集合的概念及操作
集合是一个无序的,不重复的数据组合,有两个要点:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
1、集合的创建与类型
list_1 = [1,2,3,4,5,1,8,9,6,8,1,3,5] list_2 = [3,4,5,6,7] a=set(list_1) b=set(list_2) s= set([3, 5, 9, 10]) # 创建一个数值集合 t = set("Hello") # 创建一个唯一字符的集合 print(a,b,s,t,type(a),type(b),type(t)) --------------------------------------------------------------- {1, 2, 3, 4, 5, 6, 8, 9} {3, 4, 5, 6, 7} {9, 10, 3, 5} {'e', 'o', 'H', 'l'} <class 'set'> <class 'set'> <class 'set'>
此代码的注意点:set的使用以及集合的类型set。同时要注意一个字符串如代码中的hello最后被拆成了单个字母。list
2、集合间相互关系的判断
关系有:交集(&)、并集(|)、差集(-)、父集、子集、对称差集(^)、是否有交集,元素是否在集合内
list_1 = [1,2,3,4,5,1,8,9,6,8,1,3,5] list_2 = [3,4,5,6,7] set1=set(list_1) set2=set(list_2) print(set1) print(set2) print(set1&set2,set1|set2,set1-set2,set2-set1,set1^set2) print(set1.intersection(set2),set1.union(set2),set1.difference(set2),set2.difference(set1),set1.symmetric_difference(set2))
--------------------------------------------------------------------------------------------
{1, 2, 3, 4, 5, 6, 8, 9}
{3, 4, 5, 6, 7}
{3, 4, 5, 6} {1, 2, 3, 4, 5, 6, 7, 8, 9} {8, 1, 2, 9} {7} {1, 2, 7, 8, 9}
{3, 4, 5, 6} {1, 2, 3, 4, 5, 6, 7, 8, 9} {8, 1, 2, 9} {7} {1, 2, 7, 8, 9}
对称差集:并集去掉交集
list_1 = [1,2,3,4,5] list_2 = [3,4,5] set1=set(list_1) set2=set(list_2) set3={11,22,33} print(set1) print(set2) print(set3) print(set1.issuperset(set2),set2.issubset(set1),set3.isdisjoint(set1)) ------------------------------------------------------------------ {1, 2, 3, 4, 5} {3, 4, 5}
{33, 11, 22} True True True
此代码的注意点:isdisjoint,如果无交集返回true,如果与交集返回false
3、 集合的添加和删除
两种添加元素的方式:add于update,update的内容可以写成集合的形式也可以写成列表的形式,不能直接写会报错
set3={11,22,33}
print(set3)
set3.update({666,777,888})
print(set3)
#set3.update(999,12345) 报错
set3.update(['ok','test'])
set3.add('aaa')
print(set3)
print(33 in set3)
-----------------------------------------------------
{33, 11, 22}
{33, 22, 888, 777, 666, 11}
{33, 'ok', 22, 'test', 888, 777, 666, 11, 'aaa'}#无序性
True
两种删除元素的方式:remove与discard
Remove 直接删除,如果不存在会报错
Discard 直接删除,不存在则不操作,操作完成返回null(无论是否实质性删除)
set1={11,22,33,666,777,888,999}
set1.remove(999)
print(set1)
#set1.remove(999) 如果放开这代码会有报错
a=set1.discard(999)
b=set1.discard(666)
print(set1,a,b)
----------------------------------------------------
{33, 777, 11, 22, 888, 666}
{33, 777, 11, 22, 888} None None