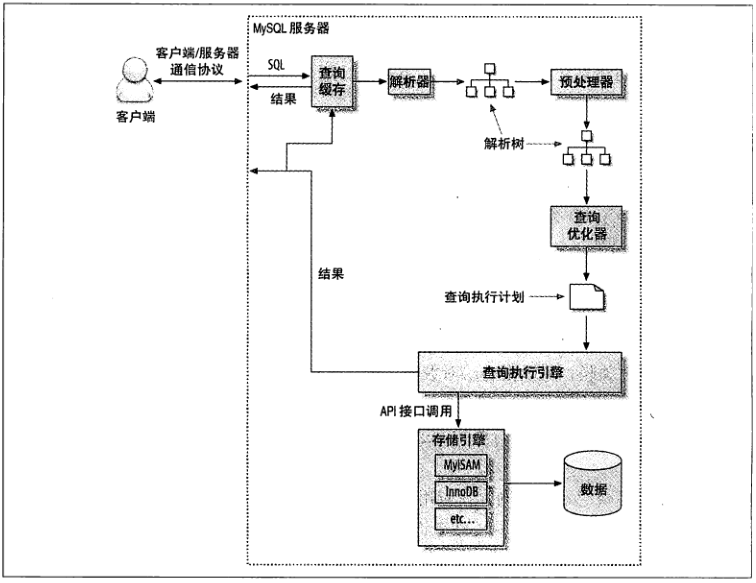
mysql分客户端、服务层、存储引擎层,而索引的实现就是在存储引擎层,因此各个不同的存储引擎之间的索引都有细微的差别。
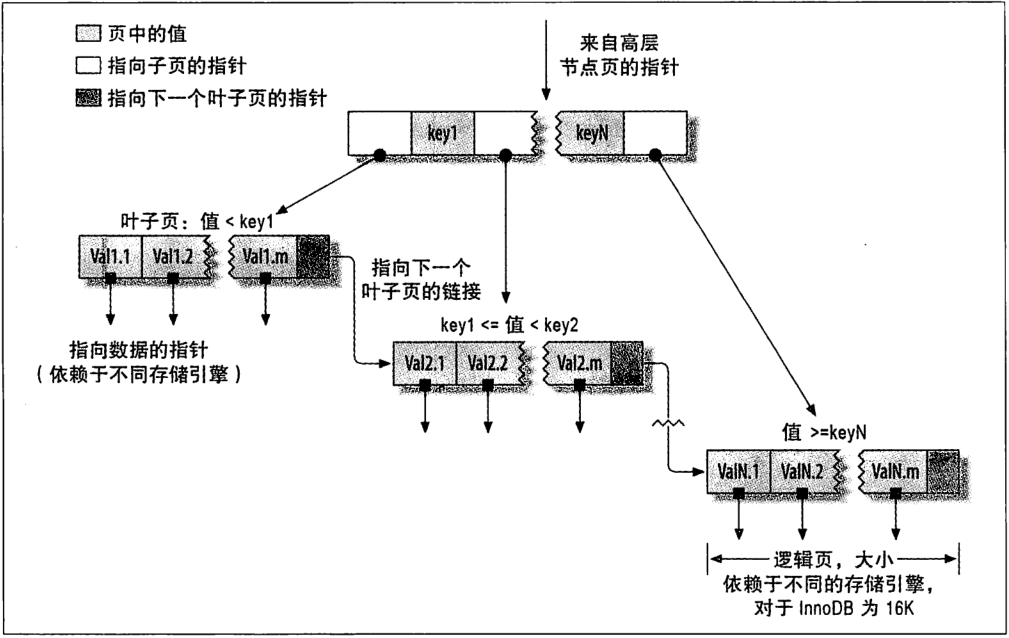
【B-Tree索引】
- MyIsam使用前缀压缩技术使得索引更小,Innodb则按照原数据格式进行存储
- MyIsam索引通过数据的物理位置引用被索引的行,Innodb则根据主键引用被索引的行。
- 索引树中的节点是有序的,所以索引适合全键值、键值范围或键前缀查找(最左)。因为是顺序的,所以也适合排序。
- 联合索引的索引顺序很重要
【哈希索引】
- 基于哈希实现。
- 只有Memory引擎显式支持哈希索引
- 哈希索引只包含哈希值和行指针,而不存储字段值
- 哈希索引数据并不是按照索引值顺序存储的
- 哈希索引不支持部分索引列匹配查找,哈希索引值是使用索引列全部内容来计算哈希值的
- 哈希索引只支持等值比较查询
- 访问哈希索引的数据比较快,但是有多哈希值冲突的风险。
【全文索引】
查找匹配的是文本中的关键词,类似于搜索引擎
【索引的优点】
- 减少表数据的扫描数量,不用全表扫描了
- 避免排序和临时表【索引按顺序的,节省了排序时间】。
- 将随机I/O变为顺序I/O
【重点】【高效实用索引的技巧】
- 在索引列不要进行计算,例如下
select student_id from student where student_id + 1 =5;
-
给text类型添加索引时,可以使用前缀索引,就是将值的内容截取一部分作为索引。
-
联合索引(多列索引)要注意列顺序。一般是考虑的因素是,使用率最高的列放到索引前列,避免随机IO,排序。
- 聚簇索引,表示数据行和相邻的键值紧凑的存储在一起。innodb默认会拿主键作为聚簇索引,若没有主键,就是用非空索引,主键为顺序的整数更加有利。
- 表中的索引越多,插入的速度越慢,准确的说是insert update delete
- 索引可以让查询锁定更少的行
- 确保任何group by和order by中的表达式只涉及到一个表中的列。
- 除非确实需要服务器小虫重复的行,否则一定要使用union all,mysql是通过创建临时表的方式来执行union查询。
【MySQL能够使用三种方式应用WHERE条件,从好到坏的顺序为】
- 在索引中使用where条件来过滤不匹配的记录,在存储引擎层完成
- 使用索引覆盖扫描来返回记录,直接从索引中过滤不需要的记录并返回命中的结果,在服务器层完成的
- 从数据表返回数据。
【查询的执行流程】