1.在ssd/caffe/data下创建VOC2007的目录,将ssd/caffe/data/VOC0712里的create_data.sh、create_list.sh和labelmap_voc.prototxt拷贝到VOC2007下,得如下图:

2.在/home/bnrc下创建data目录,在data目录下创建VOCdevkit2007目录,直接把VOC2007整个数据的文件夹放在VOCdevkit2007目录下,结构如图:

VOC2007文件夹所包含的目录:

3.在ssd/caffe/examples目录下,创建VOC2007文件夹,这个文件夹之后要存储生成的lmdb数据
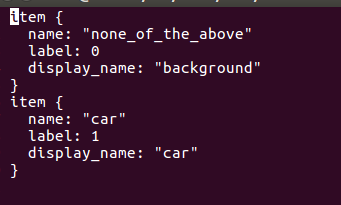
4.修改labelmap_voc.prototxt成你自己的格式:
运行create_list.sh:./create_list.sh,报以下错误:

因为我的data目录下是VOCdevkit2007,所以需要修改create_list.sh中的root_dir=$HOME/data/VOCdevkit/为root_dir=$HOME/data/VOCdevkit2007/
修改之后依旧报以下错:

这是因为/data/VOCdevkit2007下只有VOC2007,没有2012,所以需要把for name in VOC2007 VOC2012中的VOC2012删除
修改之后报以下错误:

这是还没有编译ssd这个目录的原因
之后再运行create_data.sh :./create_data.sh,报以下错误:

需要将create_data.sh中的data_root_dir="$HOME/data/VOCdevkit"改为data_root_dir="$HOME/data/VOCdevkit2007",将dataset_name="VOC0712"改为dataset_name="VOC2007"
再运行报以下错误:

用export PYTHONPATH=/home/bnrc/ssd/caffe/python修改PYTHONPATH
修改之后又报错:
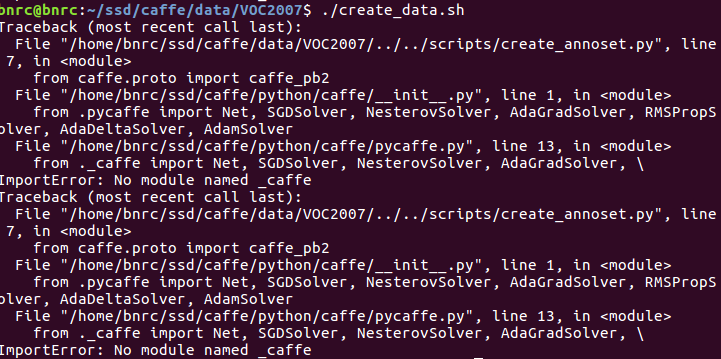
这是因为我之前只在ssd/caffe进行make,没有make pycaffe
make pycaffe的显示:

可以看到,生成了_caffe
再运行就能正确在./examples/VOC2007下生成lmdb数据了
5.修改ssd_pascal.py代码:

自己的是VOC2007

model_name修改为VOC2007
save_dir修改为VOC2007
snapshot_dir修改为VOC2007
job_dir修改为VOC2007
output_result_dir在/data前加/home/bnrc
name_size_file修改为VOC2007
label_map_file修改为VOC2007
num_classes修改为2

gpu可以根据需要选择

6.训练数据:python ./examples/ssd/ssd_pascal.py