import xlrd
import re
def excel_table_byindex():
data = xlrd.open_workbook('crawlingPhonePrice_new.xlsx') #打开一个excel表格,表格有手机名,价格
table=data.sheets()[0]
nrows=table.nrows
ncols=table.ncols
colnames=table.row_values(0)
#print(colnames)
info={} #存放键值对,手机名价格
spam=[] #将info字典存放在spam列表中
for rownum in range(1,4):#循环3个数据,Python循环是减1
phone_name=table.row_values(rownum)[0]
phone_price=table.row_values(rownum)[1]
info['phoneName']=phone_name
info['phonePrice']=phone_price
print(info)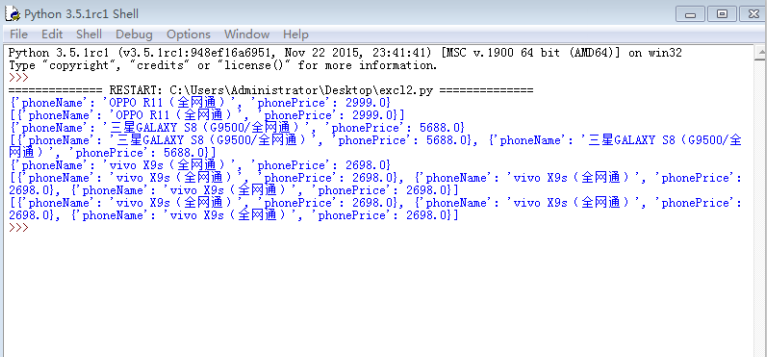 spam.append(info)
print(spam)
#print(spam)
def main():
tables=excel_table_byindex()
#tianjia()
def tianjia():
spam=[]
for i in range(1,5):
spam.append('hello%d'%i)
print(spam)
if __name__=="__main__":
main()
spam.append(info)
print(spam)
#print(spam)
def main():
tables=excel_table_byindex()
#tianjia()
def tianjia():
spam=[]
for i in range(1,5):
spam.append('hello%d'%i)
print(spam)
if __name__=="__main__":
main()
#######
打印出来info每次都不一样,第一次是OPPO,插入到列表中,
第二次是三星,再次放入列表中,此时列表有两个数据,两个都是info,安按照之前想法是应该两个值不相同,但是明显都是相同的,都变成了三星。
思索良久,列表存放的知识info,而info是只创建了一个地址,每次会改变数据,所以第一次改变后,之前的OPPO数据也就变成了三星数据,而列表
存放的两个数据,都是同一个info,所以每次插入都是改变后的值。
虽然没什么用,不过感悟电脑其实都是循规蹈矩的,只是我们不懂他们的工作原理。这两天被用爬虫爬取链家,京东,zlo商城的数据,发现很多基本原理的问题,
包括正则表达式匹配,包括页面代码获取不到价格,原来页面的价格为了防爬虫,是通过二次调用请求得到的,不是写死在页面代码中。
知识无止境,人生需努力。