netty版本
netty版本:io.netty:netty-all:4.1.33.Final
简介
- 网络数据的基本单位总是字节,java NIO提供
ByteBuffer作为字节的容器,但是ByteBuffer使用起来过于复杂和繁琐。 ByteBuf是netty的Server与Client之间通信的数据传输载体(Netty的数据容器),它提供了一个byte数组(byte[])的抽象视图,既解决了JDK API的局限性,又为网络应用程序的开发者提供了更好的APIByteBuffer缺点ByteBuffer长度固定,一旦分配完成,它的容量不能动态扩展和收缩,当需要编码的POJO对象大于ByteBuffer的容量时,会发生索引越界异常;ByteBuffer只有一个标识位置的指针position,读写的时候需要手工调用flip()和rewind()等,使用者必须小心谨慎地处理这些API,否则很容易导致程序处理失败;ByteBuffer的API功能有限,一些高级和实用的特性它不支持,需要使用者自己编程实现。
ByteBuf优点- 容量可以按需增长
- 读写模式切换不需要调用flip()
- 读写使用了不同的索引
- 支持方法的链式调用
- 支持引用计数
- 支持池化
- 可以被用户自定义的缓冲区类型扩展
- 通过内置的复合缓冲区类型实现透明的零拷贝
API详解
ByteBuf工作机制:ByteBuf维护了两个不同的索引,一个用于读取,一个用于写入。readerIndex和writerIndex的初始值都是0,当从ByteBuf中读取数据时,它的readerIndex将会被递增(它不会超过writerIndex),当向ByteBuf写入数据时,它的writerIndex会递增。- 名称以
readXXX或者writeXXX开头的ByteBuf方法,会推进对应的索引,而以setXXX或getXXX开头的操作不会。 - 在读取之后,
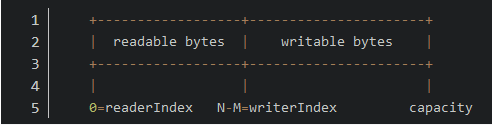
0~readerIndex的就被视为discard的,调用discardReadBytes方法,可以释放这部分空间,它的作用类似ByteBuffer的compact()方法。 readerIndex和writerIndex之间的数据是可读取的,等价于ByteBuffer的position和limit之间的数据。writerIndex和capacity之间的空间是可写的,等价于ByteBuffer的limit和capacity之间的可用空间。
索引变化图
-
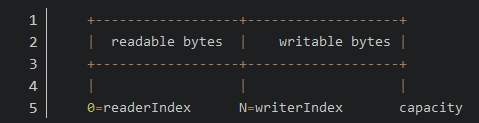
初始分配

-
写入N个字节
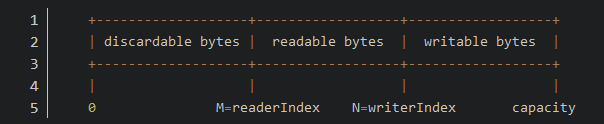
-
读取M(<N)个字节之后
-
调用discardReadBytes操作之后
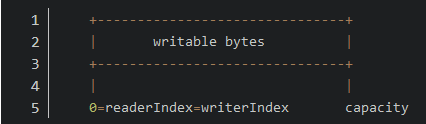
-
调用clear操作之后
创建
-
推荐通过一个Unpooled的工具类来创建新的buffer而不是通过构造器来创建
-
创建堆缓冲区
@Test public void testHeapByteBuf() { ByteBuf heapBuf = Unpooled.buffer(10); if (heapBuf.hasArray()) { byte[] array = heapBuf.array(); int offset = heapBuf.arrayOffset() + heapBuf.readerIndex(); int length = heapBuf.readableBytes(); //0,0 logger.info("offset:{},length:{}", offset, length); } }
3. 直接内存缓冲区
@Test public void testDirectByteBuf() { ByteBuf directBuffer = Unpooled.directBuffer(10); if (!directBuffer.hasArray()) { int length = directBuffer.readableBytes(); byte[] array = new byte[length]; ByteBuf bytes = directBuffer.getBytes(directBuffer.readerIndex(), array); //0,0 logger.info("offset:{},length:{}",bytes.readerIndex() , array.length); } }
访问
1. ByteBuf提供了两个指针变量来支持顺序读写操作readerIndex用来支持读操作, writerIndex用来支持写操作。下图展示了ByteBuf是如何被两个索引分成三个区域的

2. 可读字节:ByteBuf的可读字节分段存储了实际数据。新分配的、包装的或者复制的缓冲区的默认的readerIndex值为0。任何名称以read或者skip开头的操作都将检索或者跳过位于当前readerIndex的数据,并且将它增加已读字节数。如果被调用的方法需要一个ByteBuf参数作为写入的目标,并且没有指定目标索引参数,那么该目标缓冲区的writeIndex也将增加(例如:readBytes(ByteBuf dst))
//读取所有可读的字节 ByteBuf buffer = ...; while (buffer.readable()) { System.out.println(buffer.readByte()); }
3. 可写字节:可写字节分段是指一个拥有未定义内容的、写人就绪的内存区域。 新分配的缓冲区的writerindex的默认值为0。 任何名称以write开头的操作都将从当前的 writerIndex处开始写数据,并将它增加已经写入的字节数。如果写操作的目标也是 ByteBuf时,并且没有指定源索引的值,则源缓冲区的readerIndex也同样会被增加相同的大小(例如:writeBytes(ByteBuf dest))。
@Test public void testWrite() { ByteBuf heapBuf = Unpooled.buffer(10); while (heapBuf.writableBytes() > 4) { heapBuf.writeInt(new Random().nextInt()); } }
4. 丢弃字节:可丢弃字节的分段包含了已经被读过的字节。通过调用discardReadBytes()方法,可以丢弃它们并回收空间。这个分段的初始大小为0,存储在readerIndex中, 会随着read操作的执行而增加 (get*操作不会移动readerindex )
5. 虽然你可能会倾向于频繁地调用discardReadBytes()方法以确保可写分段的最大化,但是请注意,这将极有可能会导致内存复制, 因为可读字节必须被移动到缓冲区的开始位置。我们建议只在有真正需要的时候才这样做,例如,当内存非常宝贵的时候
6. 清除buffer索引:你可以通过调用clear()将readerIndex和writerIndex都设为0。这不会清除buffer内容(例如用0填充), 他仅仅是清除了两个指针。请注意这个操作的语义和ByteBuffer.clear()是不一样的。调用clear()比调用discardReadBytes()轻量的多,因为只是重置索引而不会复制内存
7. 查找操作:
@Test public void testFind() { ByteBuf heapBuf = Unpooled.buffer(13); heapBuf.writeByte(new Random().nextInt()); heapBuf.writeByte(new Random().nextInt()); heapBuf.writeBytes(" ".getBytes()); int i = heapBuf.indexOf(0, 12, (byte) ' '); //2 System.out.println(i); i = heapBuf.forEachByte(ByteProcessor.FIND_CRLF); //2 System.out.println(i); }
8. 派生缓冲区为ByteBuf提供以专门的方式呈现其内容的视图。
duplicate() slice() slice(int, int) Unpooled.unmodifiableBuffer () order (ByteOrder) readSlice (int) 每个这些方法都将返回一个新的ByteBuf实例,它具有自己的读索引、写索引和标记 索引。其内部存储和 JDK 的ByteBuffer一样也是共享的。这使得派生缓冲区的创建成本 是很低廉的,但是这也意味着,如果你修改了它的内容,也同时修改了其对应的源实例,所以要小心。