转自:https://www.cnblogs.com/wangtao_20/p/8294974.html
术语备注:
1、OLTP - 这是on-line transaction processing的简写。翻译成联机事务处理。就是在线交易的业务数据。这方面的数据库是关系型数据库。
2、OLAP - On-Line Analytical Processing 翻译成联机分析处理。通俗理解,就是做数据统计、分析的平台。顺应这个需求产生了数据仓库的概念。
3、数据仓库 - 只是一个概念,数据的仓库。搭建数据仓库的技术方案可以是关系型数据库,也可以是列存储。为了通俗理解,可以把数据仓库和OLAP看作一个东西。
4、商业智能BI - 本质还是依赖于数据仓库做支持的,没有数据存储,没有大量数据,无法统计、无法分析。
为什么数据仓库喜欢使用列式关系型储数据库?
数据仓库使用的技术方案,有很多种。可以使用关系型数据库mysql,目前,业界一般使用列存储。
为什么不用mysql等行存储关系数据库来做数据仓库? 而一般使用列存储数据库, 是考虑到数据仓库的以下特点:
1、数据仓库的数据来源多个系统。可能是文件、可能是其他关系型数据库中的交易数据。
2、需要多个维度建立数据统计模型。
3、存储数据量。历史的,存档的,归纳的,计算的数据。
4、需要访问大量的记录才能统计出结果。如果统计性能上不能很慢,无法出统计结果。就满足不了分析统计的需求。
涉及到复杂的聚合统计查询,这类系统就比较难以处理了,比如要查询某一些类型的用户过去三个月购买最多的商品,因为同一时间需要查询大量数据,OLTP(关系数据库) 系统并不擅长处理这类需求。
5、更新数据很少。都是添加数据、查询数据。于是对查询速度要求高。
对比行存储和列存储
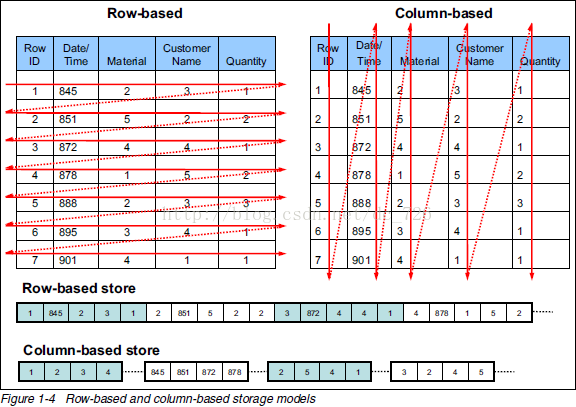
行存储的一行数据(此行的所有数据)都在一起,紧接着就是第二行数据,依次下去。
列存储不同的是,一列的所有数据都放在一起了。
从上图可以很清楚地看到,行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。所以它们就有了如下这些优缺点:


|
行式存储
|
列式存储
|
|
|
优点
|
Ø 数据被保存在一起
Ø INSERT/UPDATE容易
|
Ø 查询时只有涉及到的列会被读取
Ø 投影(projection)很高效
Ø 任何列都能作为索引
|
|
缺点
|
Ø 选择(Selection)时即使只涉及某几列,所有数据也都会被读取
|
Ø 选择完成时,被选择的列要重新组装
Ø INSERT/UPDATE比较麻烦
|
注:关系型数据库理论回顾 - 选择(Selection)和投影(Projection)
列存储在做 join 联合的时候,效率更高。
在列存储中,下面查询语句:select customers,material from table where customers="miler" and material="refrigerator"
一列的所有数据都在一块,所以每一列都是一个索引。对一列数据压缩也很方便,变成数字存储了。存储空间变小,存储空间变小,操作速度就更快。

关键步骤如下:
1. 去字典表里找到字符串对应数字(只进行一次字符串比较)。
2. 用数字去列表里匹配,匹配上的位置设为1。
3. 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
4. 使用这个下标组装出最终的结果集。
业界常来搭建数据仓库的数据库
在数据仓库领域的收费列数据库
1、惠普公司的Vertica
2、oracle公司Oracle Warehouse Builder的
3、sybase公司的Sybase IQ/SAPIQ
4、mysql公司出的Infobright。
5、Greenplum公司的Greenplum
互联网公司自主研发的
1、华为的Carbondata
2、百度研发给内部使用的palo。
3、腾讯Hermes
4、Druid:广告分析,互联网广告系统监控、度量和网络监控。开源免费。
5、俄罗斯的yandex公司为自己内部统计需要研发的clickhouse。yandex为俄罗斯的"百度"、"百度统计"业务。2016年6月份才开源发布出来。这个文档全,对php语言支持好。性能不弱于百度的palo。