一、滑动平均
公式(窗口为7):

也就是说7个数做一次平均
二、指数平均
公式:
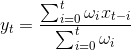
其中

因此
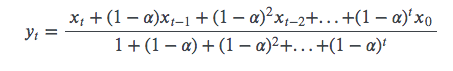
也就是说离本点越近,考虑的权重也越大。
python code:
# author: adrian.wu import numpy as np from matplotlib import pyplot as plt import pandas as pd """ count : count(1) day: d """ path = '/Users/adrian.wu/PycharmProjects/jobs/time_series/data/ord_count_by_day.csv' data_raw = pd.read_csv(path) data_raw.sort_values("d", inplace=True) """ draw raw time series picture """ # plt.plot(data_raw['d'], data_raw['count(1)']) # plt.show() win_7 = data_raw['count(1)'].rolling(window=7).mean() ewma_30 = data_raw['count(1)'].ewm(span=30).mean() d = [i for i in range(0, len(ewma_30))] fig, ax = plt.subplots(1, 1) ax.plot(d, data_raw['count(1)'], label='raw_data') ax.plot(d, win_7, label='win_7') ax.plot(d, ewma_30, label='ewma_span=30') plt.legend() plt.show()

三、趋势和周期
时间序列经过合理的函数变换后都可以被认为是由3个部分叠加而成。分别是趋势项部分、周期项部分和噪声项部分

其中s(t)表示周期项,如weekly seasonality(周一和周二是不一样的)和yearly seasonality (平时和寒暑假是不一样的等)。对于一些特别的场景,比如和寒暑假是不一样的等。对于一些特别的场景,还要考虑节假日。
四、从频域看可能存在的周期
同样可以利用傅立叶变换看看频域里面的时间序列。