第一:文件基本处理流程
1 f=open('text') 2 one_line=f.readline() 3 print('one_line:',one_line) #读取一行 4 5 print('分割线'.center(50,'-')) #读取一行分割 6 7 end_line=f.read() #读取剩余的内容 8 print(end_line) 9 10 f.close() #关闭文件
第三:文件打开方式
文件句柄 = open('文件路径', '打开模式')
文件的打开模式有:
1 f = file(name[, mode[, buffering]]) 2 3 入口参数: name 文件名 4 5 mode 选项,字符串 6 7 buffering 是否缓冲 (0=不缓冲,1=缓冲, >1的int数=缓冲区大小) 8 9 返回值 : 文件对象 10 11 mode 选项: 12 13 "r" 以读方式打开,只能读文件 , 如果文件不存在,会发生异常 14 15 "w" 以写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,先清空,再打开文件 16 17 "a" 追加模式,是可读的;如果不存在则创建;存在则只追加内容 18 19 "rb" 以二进制读方式打开,只能读文件 , 如果文件不存在,会发生异常 20 21 "wb" 以二进制写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,先清空,再打开文件 22 23 "ab" 以二进制追加方式打开,可读的,如果文件不存在,创建该文件,如果文件存在,只追加新的内容 24 25 补充:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码 26 27 "r+" 可以读、写文件 , 如果文件不存在,会发生异常 28 29 "w+" 可以读、写文件, 如果文件不存在,创建该文件;如果文件已存在,先清空,再打开文件 30 31 "a+" 可读可写,如果文件不存在,则创建
总结:
r、w、a为打开文件的基本模式,对应着只读、只写、追加模式;
b、t、+、U这四个字符,与以上的文件打开模式组合使用,二进制模式,文本模式,读写模式、通用换行符,根据实际情况组合使用
第三:文件的字符编码
先看下文件存储的编码方式

文件以UTF-8存储,已utf-8的编码方式可以打开
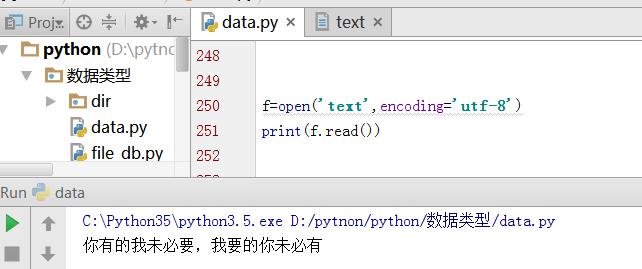
错误示例:使用gbk方式打开

第四:文件中光标内置函数:
read & readline & readlines:
1 # 打开文件 2 f = open("text", "r+") 3 4 print(f.read(2)) #读取字节到字符串中,有可选参数size,默认是-1,如果为-1或复数则文件将会被读取到文件末尾。 5 #输出结果为: 12 6 7 print(f.readline(2)) #读取文件的一行,包括行结束符。同read()也有个可选参数size。 8 #输出结果: 34 9 10 print(f.readline()) #读取一行中剩余内容 11 #输出结果:567890 12 13 print(f.readlines())#读取所有(剩余的)然后将它们作为字符串列表返回,它有个可选参数sizhint代表返回的最大字大小 14 #输出结果:['abcde ', 'ABCDE']
seek:seek(offset,where)
seek(offset,where): where=0从起始位置移动,1从当前位置移动,2从结束位置移动。当有换行时,会被换行截断。seek()无返回值,故值为None
示例:
1 f.seek(1,0) #从开始位置即文件首行首个字符开始移动一个字符 2 print(f.tell()) #此时tell()为1 3 print(f.readline()) #读取当前行的内容,即文件的第一行,从第二个字符开始读 4 #读取结果为:2345
tell:
文件的当前位置,即tell是获得文件指针位置,受seek、readline、read、readlines影响,不受truncate影响
示例:
1 f=open('text','w+') #文件以w+方式打开,则源文件被清空 2 print(f.tell()) #源文件被清空,故此时输出为0 3 4 f.write("12345") #在文件中写入12345,故站用5个字符 5 print(f.tell()) #此时tell()=5
truncate:
1 示例一: 2 # 打开文件 3 f = open("text", "r+") 4 line = f.readline() 5 print(line) 6 7 #输出结果:12345 8 9 # 截断剩下的字符串 10 f.truncate() 11 12 # 尝试再次读取数据 13 line = f.readline() 14 print(line) 15 #输出结果为空 16 17 # 关闭文件 18 f.close() 19 20 示例二: 21 # 打开文件 22 f = open("text", "r+") 23 24 # 截取3个字节 25 f.truncate(3) 26 27 msg = f.read() 28 print(msg) 29 30 输出结果:123 31 # 关闭文件 32 f.close()
第四:文件内置函数flush
flush()方法的理解:
1.文件的读取,是通过软件将文件从硬盘中读取到内存中
2.文件的写入,是通过软件将文件写入内存缓存区buffer中,然后刷到硬盘中。
现在如果写入内存的数据过大,并且内存速度比硬盘的速度要快,文件的数据都从内存刷到硬盘,内存与硬盘的速度延迟会被无限的放大,效率变低,所以要刷到硬盘的数据我们统一往内存的一小块空间即buffer中放,一段时间后操作系统会将buffer中数据一次性刷到硬盘
3.flush:用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 4 # 打开文件 5 f = open("file.txt", "wb") 6 print(f) 7 8 # 刷新缓冲区 9 f.flush() 10 11 # 关闭文件 12 f.close()
第五:文件的open函数详解
open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
以上全部都是open的参数,有很多,但是常用的是file,mode,encoding
file:文件路径,这个要加上引号
mode:打开模式,详细见上面的第二:文件打开方式
buffering:的可取值有0,1,>1三个,0代表buffer关闭(只适用于二进制模式)(不缓冲),1代表line buffer(只适用于文本模式)(缓冲),>1表示初始化的buffer大小(缓冲区大小);
encoding:指定编码方式,一般是utf-8或者gbk
errors:一般取值为strict,ignore,当取strict的时候,字符编码出现问题的时候,会报错,当取ignore的时候,编码出现问题,程序会忽略而过,继续执行下面的程序。
newline:一般取值有None, , , ”, ‘ ',用于区分换行符,但是这个参数只对文本模式有效;
closefd:是与传入的文件参数有关,默认情况下为True,传入的file参数为文件的文件名,取值为False的时候,file只能是文件描述符,什么是文件描述符,就是一个非负整数,在Unix内核的系统中,打开一个文件,便会返回一个文件描述符。
file与open对比:(python2中同时含有file与open两方法,python3中只有open方法)
两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别:
file为文件类,用file()来打开文件,相当于这是在构造文件类,
open()打开文件,是用python的内建函数来操作。
建议不论python2还是python3都使用open来操作