前言
本文是根据蚂蚁课堂余胜军老师的课程所做笔记,记录的要点,部分自己的理解可能有所偏差,不当之处会进行修改。
CAP原则
CPA即一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP三个要素不可能全部实现,最多实现两个。一般的实际都是基于AP和CP。
而Nacos支持CP/AP两个模式和混合模式,可以进行切换,默认为AP。
Eureka与Zookeeper的区别
都是分布式服务注册中心。
zookeeper采用CP保证数据一致性,原理采用Zab原子广播协议,当zk集群的leader宕机后,会自动重新选择一个新的领导角色,在选举过程中,zk环境不可使用。zk可运行的节点必须过半才能使用。
Eureka采用AP设计,完全去中心化。各个节点之间相互注册,只要有一个节点,整个微服务就可以通讯。
Eureka与Nacos的区别
Eureka采用AP模式
Nacos采用AP+CP模式混合实现,默认为AP。
Eureka底层实现集群协议是去中心化对等,Nacos使用Raft协议会产生领导角色。
分布式系统一致性算法
分布式系统一致性算法是用来保证集群节点的数据一致性的问题。
有raft(nacos)、zab(zookeeper)、paxos等。
Zab协议集群模式原理
Zab是中心化思想的集群模式,zookeeper采用的便是此协议。
zookeeper为了保持数据一致性,需要满足大多数情况,即多数节点可用时集群才能工作,>n/2+1个节点可用。
在zookeeper集群中有领导者和跟随者,对每个结点有比较其能力的myid值,根据能力值的大小选择出领导者。不过一旦启动的可用节点过半后选择出了领导者后,就不会再选举领导者了,除非当前领导者宕机。
Zab数据一致性
所有的写请求统一交给领导角色实现,领导角色写完数据之后,领导角色再将数据同步给每个节点。
数据同步采用2pc两阶段提交协议
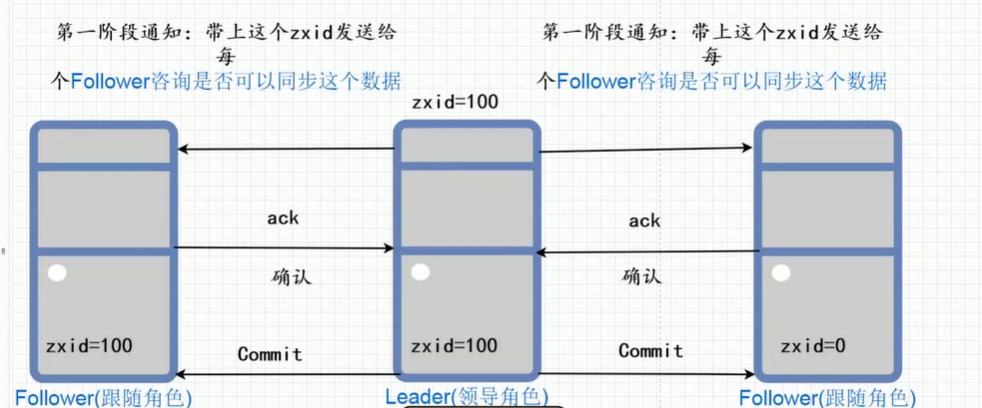
如上图,先去比较zxid的大小,将zxid大的作为领导角色。如果zxid相同,则比较myid,myid大的作为领导者。
每次写入数据时,领导角色会携带上自己zxid去询问跟随者,若有过半的跟随者回应,则进行写入操作,并将领导者的zxid写给同步的跟随者。
Raft协议选举实现原理
Raft协议中有三种状态:跟随者、竞选者、领导者。
默认情况下每个节点都是跟随者,每个节点会随机生成一个选举的超时时间,在这个超时的时间范围类节点必须要等待。
超时时间过后,当前结点有跟随者变为竞选者,会给其他发出选举的投票通知,只要该竞选者有超过半数以上即可成为领导者。
超时时间短的成为领导者的可能大。
Raft随机数一样的处理方式
- 如果所有节点的超时随机数都是一样的情况下,当前投票全部作废,重新生成超时时间。
- 如果多个节点生成的随机数一样,得票高的为领导者。如果票数完全一样,直接作废。
集群节点建议为奇数。
Raft故障重新选举
如果跟随者节点不能及时收到领导角色的消息,那么跟随者就会变为竞选者,给其他节点发送选举投票通知,有过半票数则称为领导者。
Raft采用日志复制形式同步数据
- 所有的写请求都交给领导者,将请求操作写入日志,标记该状态为未提交状态。
- 为了提交该日志,领导者就会将日志以心跳形式发送给其他跟随者,只要满足过半的跟随者可以写入该数据,则直接通知其他节点同步该数据,这个过程称为日志复制。