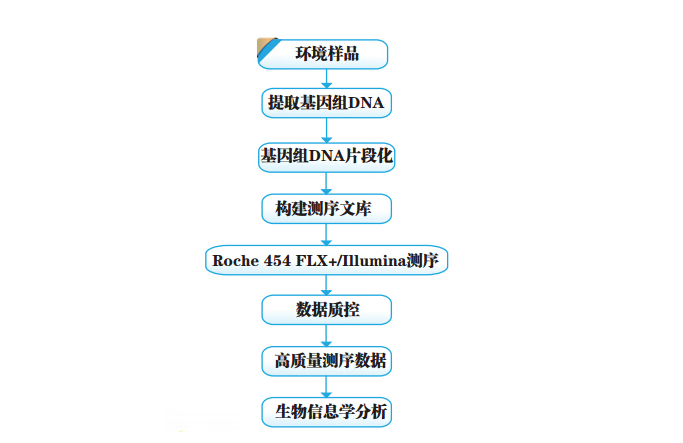
宏基因组 ( Metagenome)(也称微生物环境基因组 Microbial Environmental Genome, 或元基因组) 。是由 Handelsman 等 1998 年提出的新名词, 其定义为“the genomes of the total microbiota found in nature” , 即生境中全部微小生物遗传物质的总和。它包含了可培养的和未可培养的微生物的基因, 目前主要指环境样品中的细菌和真菌的基因组总和。而所谓宏基因组学 (或元基因组学, metagenomics) 就是一种以环境样品中的微生群物体基因组为研究对象, 以功能基因筛选和/或测序分析为研究手段, 以微生物多样性、 种群结构、 进化关系、 功能活性、 相互协作关系及与环境之间的关系为研究目的的新的微生物研究方法。
如何估计宏基因组样本中的物种组成及丰度?
宏基因组中的物种分类,一般用OTU (operational taxonomic unit), 即可操作物种单元,来表示。在典型情况下,原核生物的OTU使用16S rDNA来衡量,真核生物的OUT使用18s rDNA来衡量。
但选择16S/18S rDNA鉴定物种,存在以下几个问题:
1)rDNA之间的平行转移来干扰rDNA鉴定的可靠性。
2)在单个细菌中,16r DNA可能存在序列不同的几个拷贝,干扰估计OTU数目的准确性。
所以,其他备选的标记基因,比如单拷贝的看家基因被推荐用来作为菌种鉴定的标记。
如何衡量样本中物种的多样性?
为了估算测序的物种的比例,通常用rarefaction curse来表示。
宏基因组如何做De Novo拼接?
由于宏基因组测序的覆盖率通常是不完全的,所以组装所需要的序列并不是很完整。并且组装的时候,可能会把来自不同分类单元(OTU)的序列组装在一起,产生嵌合体基因组。Phrap,Forge,Arachne,JAZZ和Celera
Assembler等可用来组装由sanger法产生的宏基因组序列。这些算法大部分都利用mate-pair信息来参与组装。这些算法用顶点来代表每条read,互相重叠的read之间用边连起来,它们的组装问题可以转换成“哈密尔顿路径”搜索问题,即找到一条路径走过所有顶点,且每个顶点只走一次。
如何进行菌群间差异分析?
有几种基于序列特征的比较,包括样品间GC含量的比较,微生物基因组大小的比较,系统发育关系树的比较和功能组分的比较。许多比较分析都用到了关联统计学的方法,通常假设有几种元数据影响观测到的宏基因组群体的组分。主成分分析(PCA)和非度量多维标度(NM-MDS)用来图形化展示数据并揭示有哪些因素最影响数据。
有几种进行宏基因组比较分析的软件。第一个是MEGAN,可以比较两个或几个标准化后的样品的GC含量。第二种是MG-RAST,提供了一种比较功能和基于序列的分析来上传样本。第三种是CAMERA,提供了BLAST接口让客户可以比对40多种现有的宏基因组数据。
如何预测编码基因?(重点学习部分)
目前发现编码基因的方法有两种。一种是基于BLAST比对的方法,这种方法通过比对已有的数据库,可以发现宏基因组数据中有哪些已知基因的同源基因的存在,但缺陷是找不到哪些和已经基因没有同源关系的新基因。第二方法是重新预测基因的方法,这些方法大部分是基于有指导学习和统计模式识别的方法,包括隐马尔科夫模型。GeneMark.hmm就是基于单密码子频率的非均一马尔科夫模型来预测基因的软件,当这些软件用到宏基因组数据上时,这些软件通常无法确定部分的ORF,即使这些
ORF是真实基因的一部分。