孙剑博士分享的是《深度学习变革视觉计算》,分别从视觉智能、计算机摄影学和AI计算三个方面去介绍。
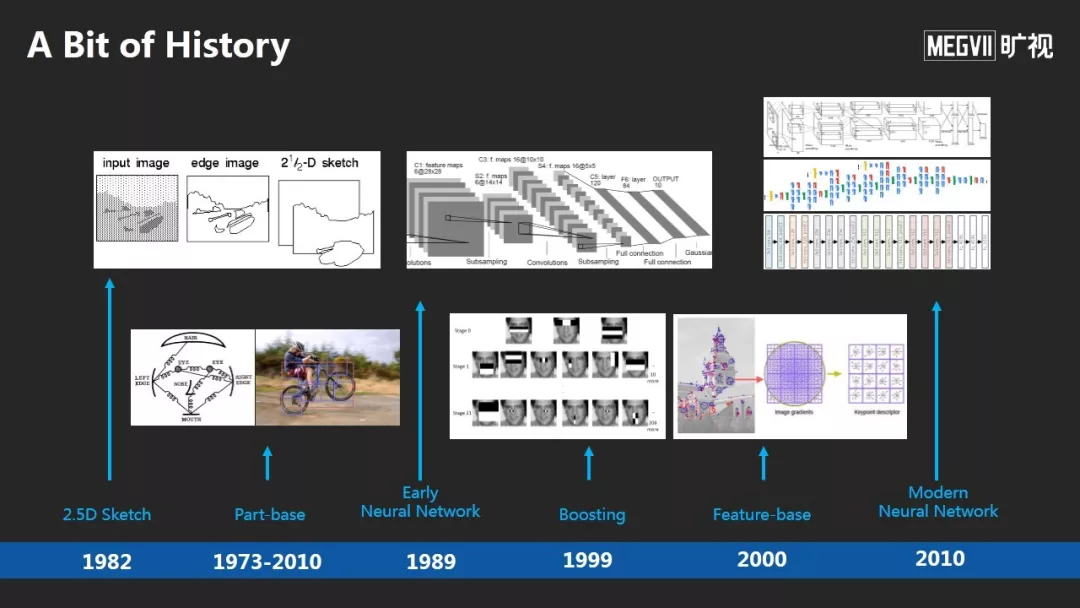
他首先回顾了深度学习发展历史,深度学习发展到今天并不容易,过程中遇到了两个主要障碍:
第一,深度神经网络能否很好地被训练。在深度学习获得成功之前曾被很多人怀疑,相比传统的机器学习理论,深度学习神经网络的参数要比数据大10倍甚至上百倍;
第二,当时的训练过程非常不稳定,论文即使给出了神经网络训练方法,其他研究者也很难把结果复现出来。
这些障碍直到2012年才开始慢慢被解除。
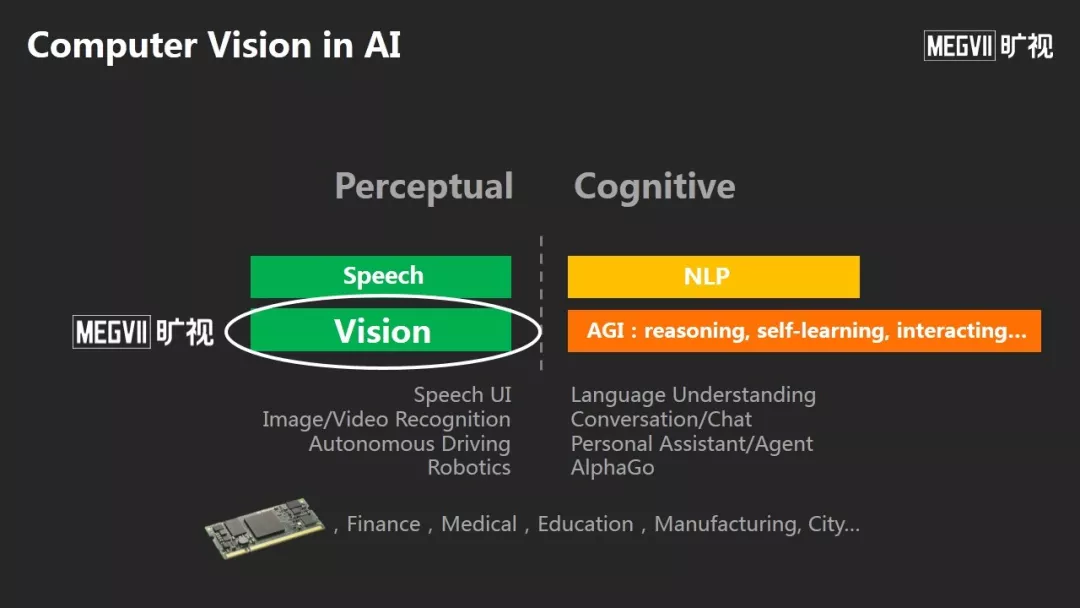
人工智能可以分为感知和认知两大部分,语音、NLP和CV是AI的三大支柱。
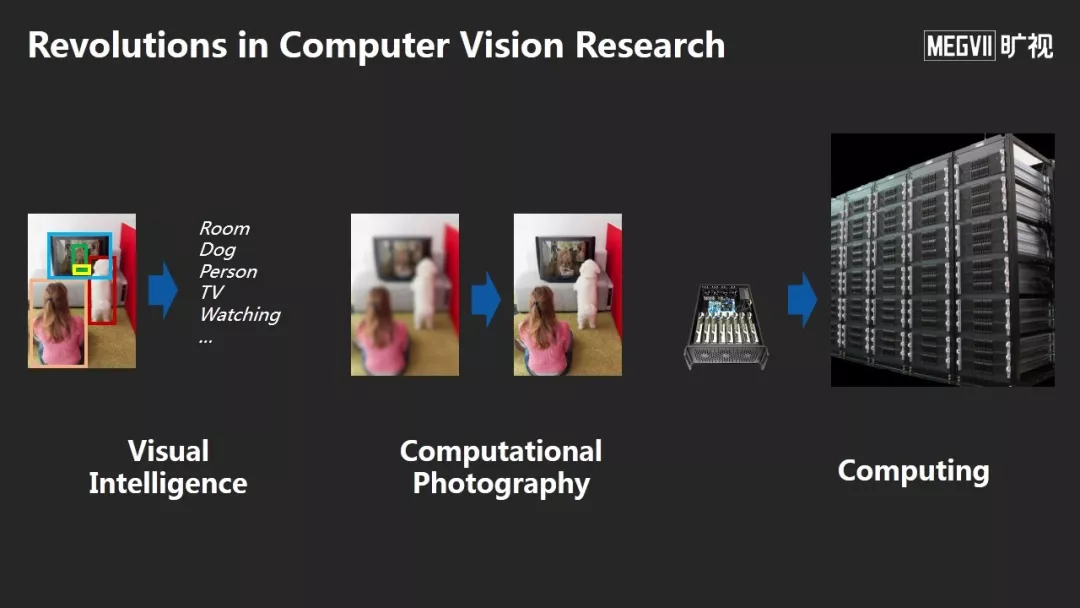
今天的分享主要分为三个方面,这也是深度学习引入计算机视觉后,对我们的研究带来的三大变革:
-
第一,视觉智能是回答了机器如何理解一张照片或者视频,这方面的研究发生了哪些变化?
-
第二,计算机摄影学研究如何从输入图像生成另一幅我们期望的图像,这个领域发生了哪些变化?
-
第三,今天的AI计算发生了哪些变化?
视觉智能
计算机视觉研究的几个问题:分类、检测、分割及将前三者用于视频序列的识别工作。
计算机视觉尤其是语义理解核心是如何在计算机中表示一张照片,以至于可以操作它、理解它,用它做各种各样的应用。
2000年后最好的方法是Feature-base,从一张图中抽取很多局部的特征,编码成一个非常长的向量。2010年深度学习后,神经网络给我们带来了更强大的视觉表示方法。
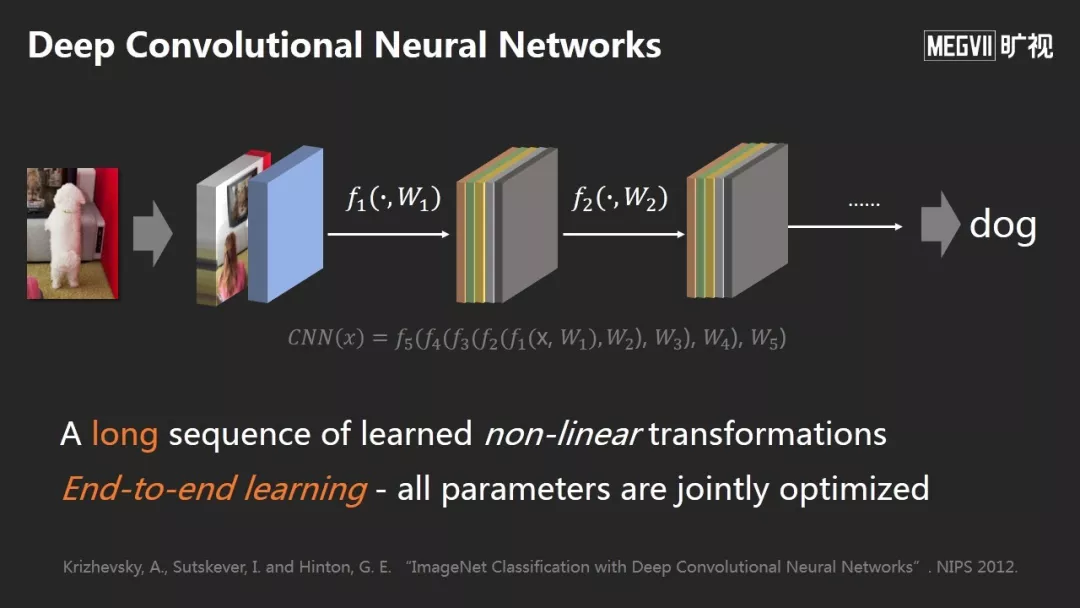
深度神经网络有两个特征:
首先,它是对一张图片做映射,映射到一个高维空间的向量上;它由非常长的非线性变换组成,进来的信号进行多次非线性变换,直到人们得到想要的图像表示。
第二,这个非线性变换中的所有参数都是根据监督信号全自动学习的,不需要人工设计。
神经网络在前面一些层学到了类似边缘、角点或纹理等初级模式,在后面一些层学到越来越多的语义模式例如物体或物体部分。整体学到了分层结构的表示。
从2012年AlexNet,一个8 Layers的神经网络,后来有VGG, 一个19 Layers的神经网络,到了2015年,我们提出了152 Layers的神经网络。随着网络层数的增加与数据的增多,我们第一次在ImageNet数据集上让机器超越了人类。
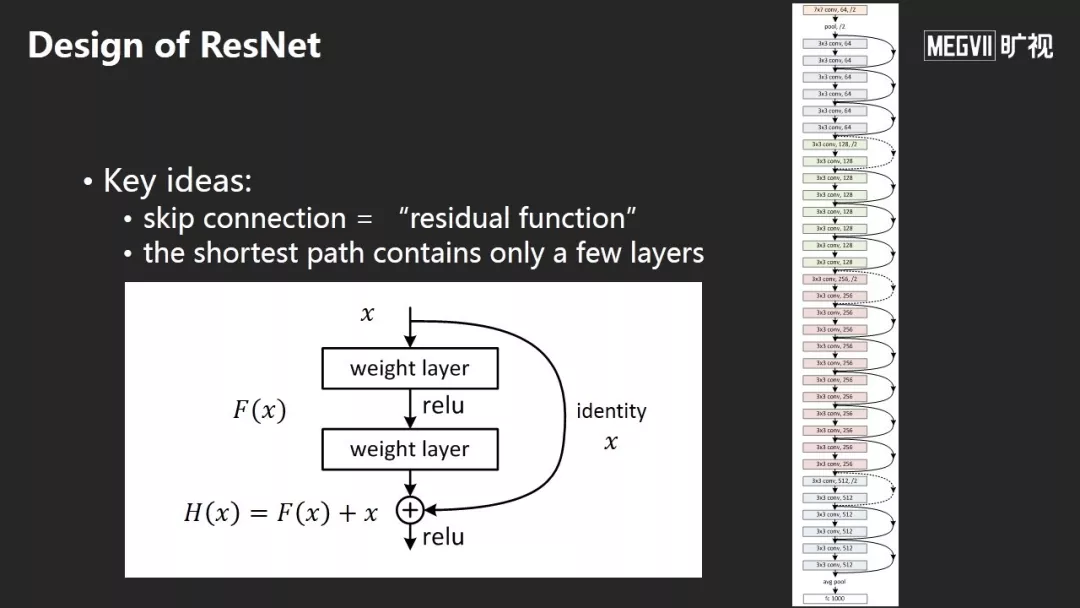
esNet的核心思想是加入跳层连接,不要学习直接的映射而是学习残差映射,这样非常有利于训练或优化。
ResNet出来后,同行给了各种各样的解释。这是我比较相信的解释:而非ResNet很容易表示0映射,即输入信号和输出很接近0;而ResNet很容易表示Identity映射,即输入信号和输出很接近,直观的理解是当一个网络非常深时,相邻的变化越来越小。这种参数化的形式更利于学习,以至于我们神经网络的优化更容易。
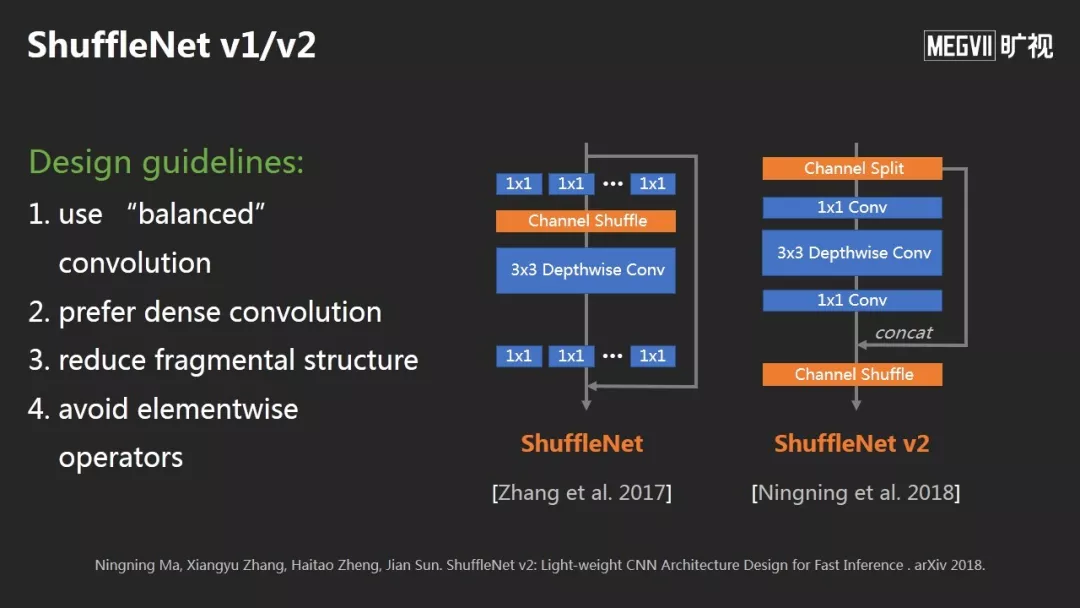
ShuffleNet有V1和V2版本,核心是提出了一套设计原理:比如让卷积更平衡;尽量不要产生分支;降低整体结构的碎片化,避免逐元素操作。
神经网络设计的最新研究方面,目前很热的趋势叫AutoML或者NAS。这是一个很好的网站(automl.org),大家可以在这里看最新的文章。
NAS的问题核心是解一个嵌套的权重训练问题和网络结构搜索问题。

以上是今天的第一部分,说的是视觉智能,我们从Feature的功能化定义,到走向模型的设计,再走到现在的模型搜索。
计算摄影学
二部分,我想分享以前做了很多年的研究方向——计算摄影学。除了计算智能,计算机视觉中还有一个问题是给输入一个图像,输出是另一个图像。从输入质量比较差的图像(比如模糊、有噪声、光照不好)恢复更好的图像,这就是计算摄影学,也是目前研究很活跃的方向。

计算摄影学以前是怎么做的?这篇(上图)是我们2009年的Dehaze去雾,引入黑通道先验并结合雾的物理产生过程来恢复没有雾的图像,效果非常好,并获得了CVPR 2009最佳论文。如何从一张模糊图像和噪声图像恢复成清晰的图像,这里用了很多传统的反卷积方法。

这是另一问题,被称为图像抠图:左边是输入,右边是输出,目的是把前景精细分离出来。
今天的深度学习的方法是抛弃了以前的做法,不需要做任何显式的假设,通过全卷积的Encoder-Decoder输出想要的图像。
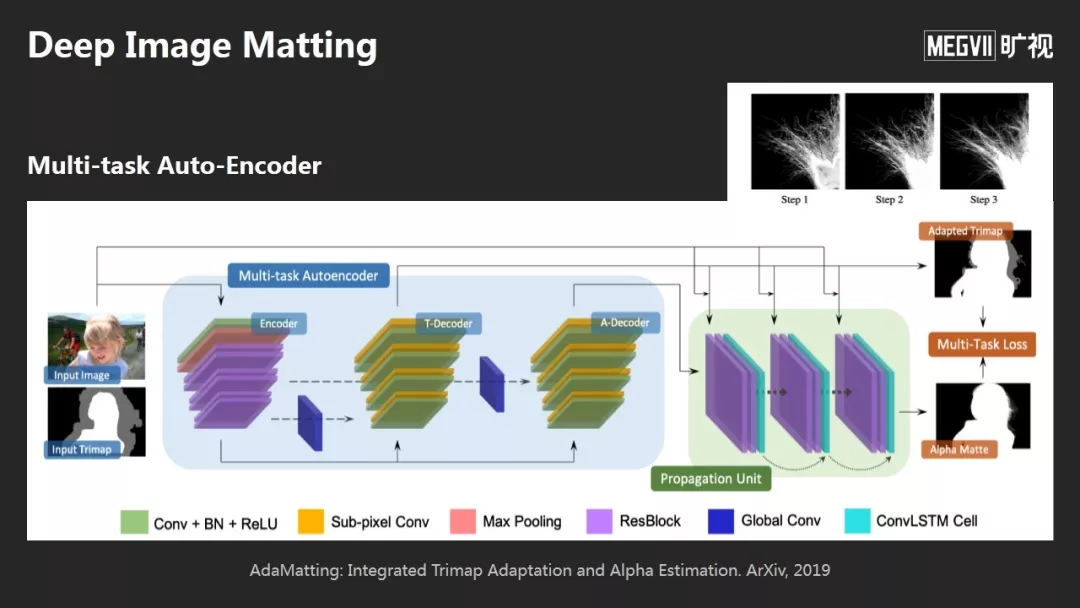
举个例子,关于Image Matting问题,今天的方法是:通过一个多任务的网络,可以直接输出Matting的结果,非常细的毛发都能提取出来。

Matting不光可以做图像合成,它还可以用单摄像头就拍出像单反一样的效果。
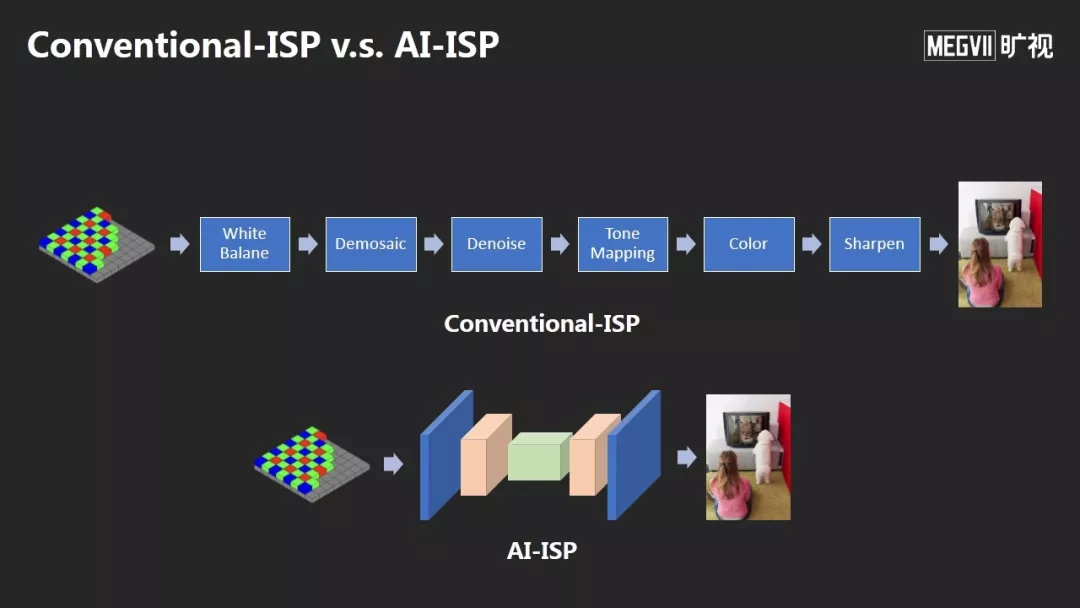
AI-ISP可以得到非常好的降噪效果和高质量的图像。
这个方法获得了今年CVPR图像降噪的冠军,同时我们将这个方法应用在OPPO今年最新的旗舰手机OPPO Reno 10倍变焦版的夜摄超画质拍摄技术上。
AI计算
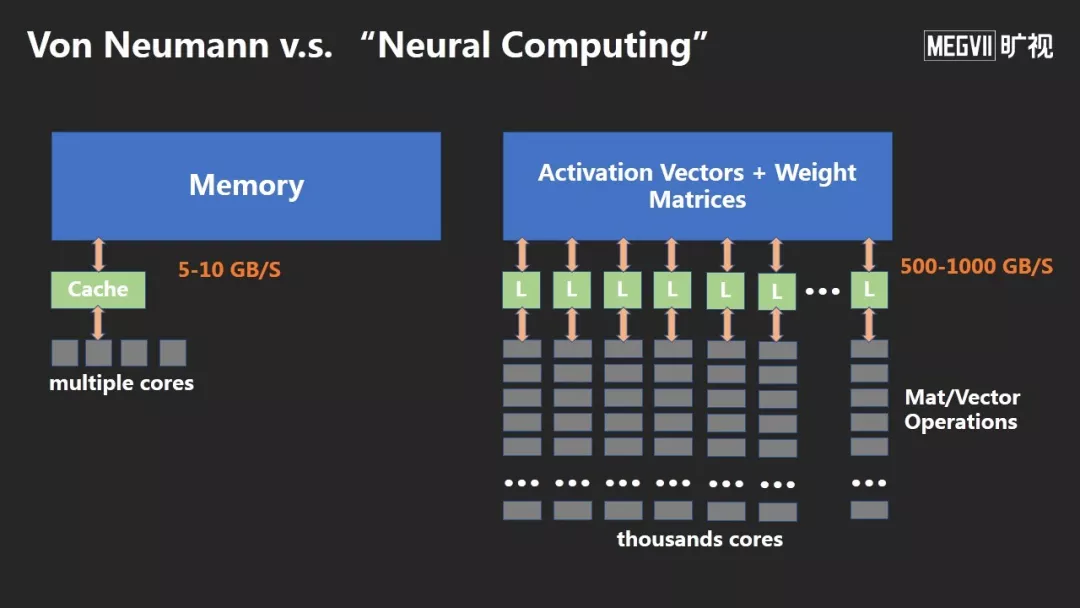
左边传统的冯诺伊曼计算架构,服务了我们很多年。但随着数据的日益增大,出现了“冯诺伊曼瓶颈”,指内存和计算单元之间搬运数据的瓶颈。
右边是今天神经网络做训练、推理的方法,它突破了这个瓶颈。因为神经网络计算非常简单,基本上只包含向量和矩阵之间的操作,可以避免很多判断和分支,用大规模并行的计算方式消除瓶颈。
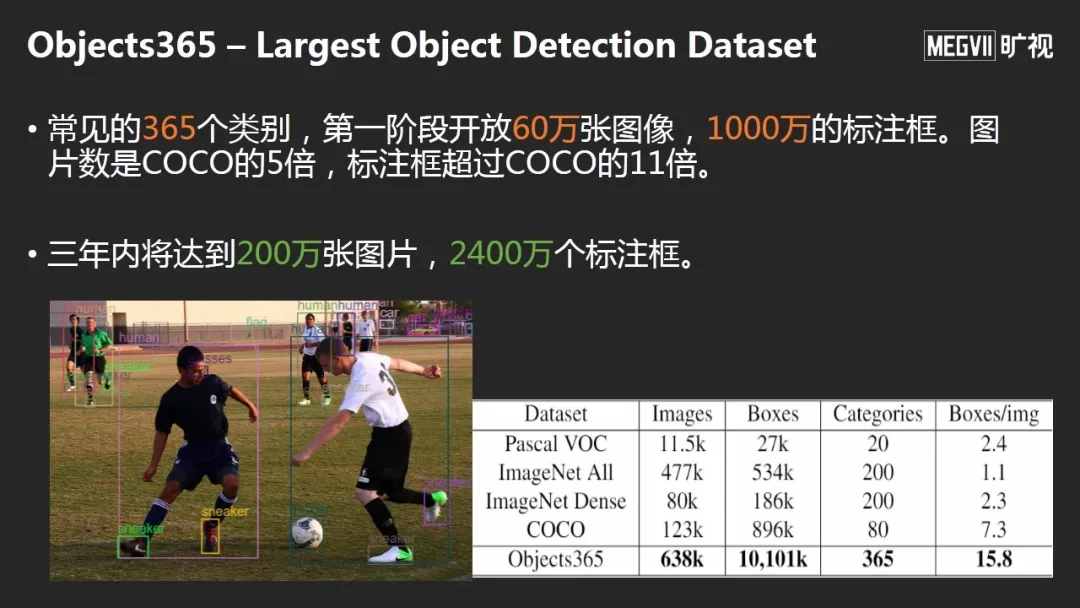
旷视和北京智源人工智能研究院共同推出的Objects365,第一阶段开源超过1000万的标注框,这是目前世界上最大的检测数据集,不光是数据大,可以真正学到更好的Feature,这是第二方面。