通常,异常值的识别可以借助于图形法(如箱线图、正态分布图)和建模法(如线性回归、聚类算法、K近邻算法),在本期内容中,将分享两种图形法,在下一期将分享基于模型识别异常值的方法。
1、可以使用线箱法
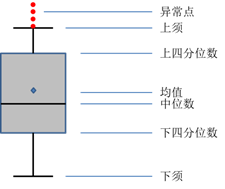
图中的下四分位数指的是数据的25%分位点所对应的值(Q1);中位数即为数据的50%分位点所对应的值(Q2);上四分位数则为数据的75%分位点所对应的值(Q3);上须的计算公式为Q3+1.5(Q3-Q1);下须的计算公式为Q1-1.5(Q3-Q1)。其中,Q3-Q1表示四分位差。如果采用箱线图识别异常值,其判断标准是,当变量的数据值大于箱线图的上须或者小于箱线图的下须时,就可以认为这样的数据点为异常点。
2、正态分布图法
根据正态分布的定义可知,数据点落在偏离均值正负1倍标准差(即sigma值)内的概率为68.2%;数据点落在偏离均值正负2倍标准差内的概率为95.4%;数据点落在偏离均值正负3倍标准差内的概率为99.6%。
outlier_ll = df45.kedanjia.mean()-3*df45.kedanjia.std()
outlier_ul = df45.kedanjia.mean()+3*df45.kedanjia.std()
df45[df45.kedanjia>outlier_ul]
在行业报告中,正太分布比线箱法有用,因为即便是同一个子类,他们的客单价差距也可能会很大,使用3倍的方差比较安全。