任务:分类出优质问题与非优质问题。
任务背景:用户实际与智能客服交互的时候,如果只做阈值限制,在相似问题匹配的时候(由于词的重复),依然会匹配出部分结果。如:问题为 "设置好了?", "可以操作?",
并不属于优质问题,但是却因为跟库里的问题有一定的相似度,所以依然会返回问题list。所以我们需要训练一个分类器,作为非优质问题的另外一个判断依据。并且后续,该分类器也可用于意图识别。
样本:
正类POS:为 既往的所有已标注的问题 + 去除停用词的既往的所有已标注的问题
之所以增加去除停用词的部分,是因为用户可能会简略的问,“优惠券?”,或者“优惠券设置?”,而不会完整的问“优惠券怎么设置?”,而库里的问题都是非常完整的,所以增加去除停用词的版本,进行训练。
负类NEG:为 SELECT content FROM kfmessage WHERE char_length(content)<6 and char_length(content)>2
之所以选择这个长度的样本,是因为,大部分不优质的问题,都在这个长度区间,这样选取出来的样本90%以上,即便不标注,都是确实是非优质问题,而我也另外导出了一部分给文其标注。
样本分词使用HMM=False, is_ignore_words=False
模型选择:
在有限的时间和人力下,只做一个baseline,要求训练快、易于调整、准确率95左右。
因为本次任务只是二分类,任务简单,且每个分类之间,有很明显的区别,所以经验上觉得使用传统的机器学习方法,或者浅层神经网络应该可以达到。
有以下几个可选
sklearn 库里现成的Linear SVC, Bayes
facebook 2016年开源 fasttext
深度学习(备选):
textCNN, 双向LSTM
测试结果:
Linear SVC:
self.train_vector = SelectKBest(chi2, k=4000).fit_transform(train_vector, self.training_tags)
self.classifier = LinearSVC(C=1.0, loss='squared_hinge', penalty='l2')
分类器参数基本猜用默认参数,特征使用卡方检验选取4000个特征,10折的交叉检验结果如下
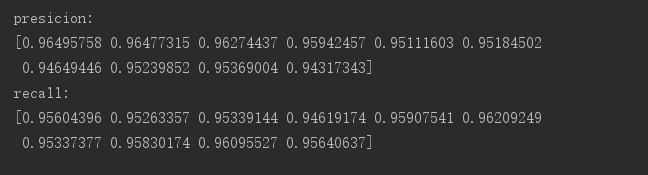
fasttext:
参数如下
classifier = fasttext.supervised(input_file = './data/binary_svc_train/fasttext/training1.txt',
output = './data/binary_svc_train/fasttext/model',
word_ngrams = 2, #n-gram
ws = 2, #windows
bucket = 20000, #bucket 用来存放ngram,如果不设置,在windows里会出现内存错误。其大小一般取决于N-gram的数量,数量少会出现两个Ngram共享一个向量
epoch = 10, #epoch
lr=0.05 # learn rate
)
10折,两次交叉验证的平均准确率,召回率:

注意:
1、fasttext原版在windoes下是无法运行的,需要使用另外一个版本,下载之后pip install . 进行安装。
地址:https://github.com/salestock/fastText.py
2、需要cython, pip install cython
3、需要visual C++ 14.0
地址:https://visualstudio.microsoft.com/zh-hans/thank-you-downloading-visual-studio/?sku=Community&rel=15
4、使用的时候,记得加bucket参数, 否则在windoes下会报错。
结果:
经过测试,还是fasttext略高一点,实际当中,也使用这个。
在判定非优质问题的时候,除了使用fasttext,还有相似度最高的检验,如果一个问题,返回的相似度列表TOP1的similarity > 阈值,则我们依然会返回列表,避免了少数情况,比如“优惠券”这种,虽然不是完整的问题,
却依然应该返回问题列表的情况。