Hadoop综合大作业 要求:
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
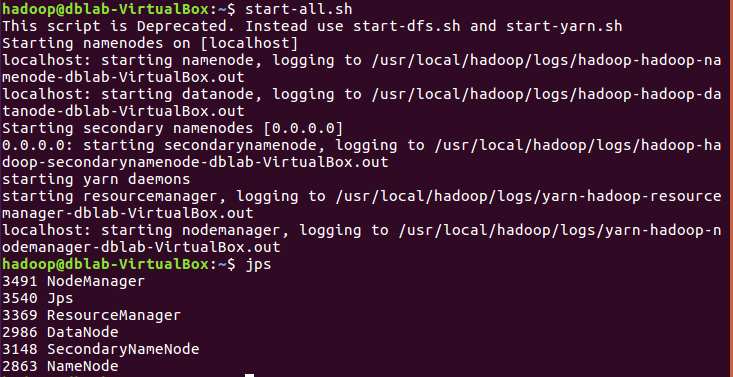
启动hadoop:
start-all.sh jps
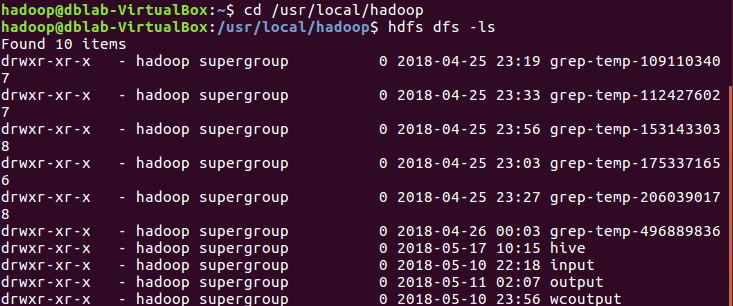
查看hdfs上的文件夹:
cd /usr/local/hadoop hdfs dfs -ls
将本地系统hadoop文件夹里的小王子英文版故事LittlePrince.txt上传至hdfs的hive文件夹中:
hdfs dfs -put ~/hadoop/LittlePrince.txt hive

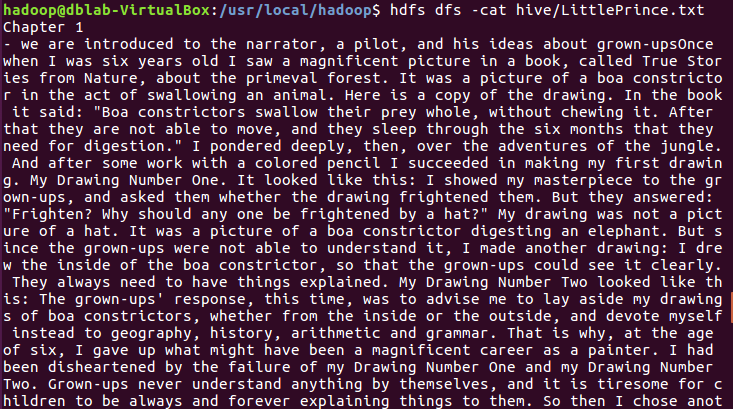
查看hdfs上的LittlePrince.txt文件内容:
hdfs dfs -cat hive/LittlePrince.txt
启动hive:
hive

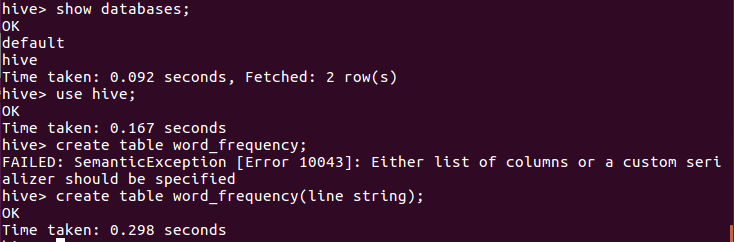
创建文档表word_frequency:
show databases; use hive; create table word_frequency(line string);
导入文件内容到表word_frequency:
load data inpath '/user/hadoop/hive/LittlePrince.txt' overwrite into table word_frequency;

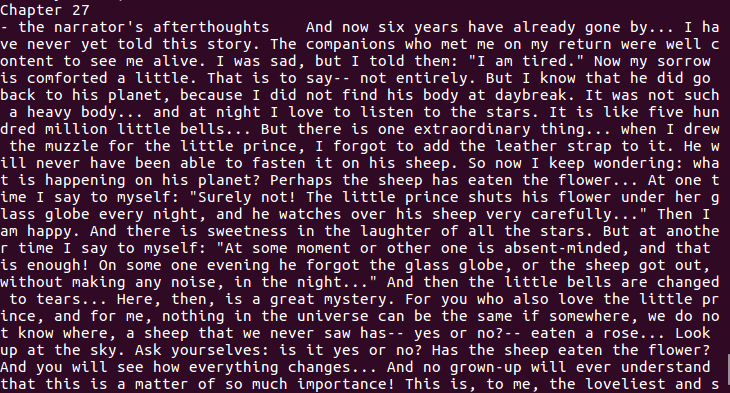
查看表word_frequency里的内容(总共27章):
select * from word_frequency;

用HQL进行词频统计,结果放在表words里:
create table words as select word,count(1) from (select explode(split(line,' ')) as word from word_frequency) word group by word;

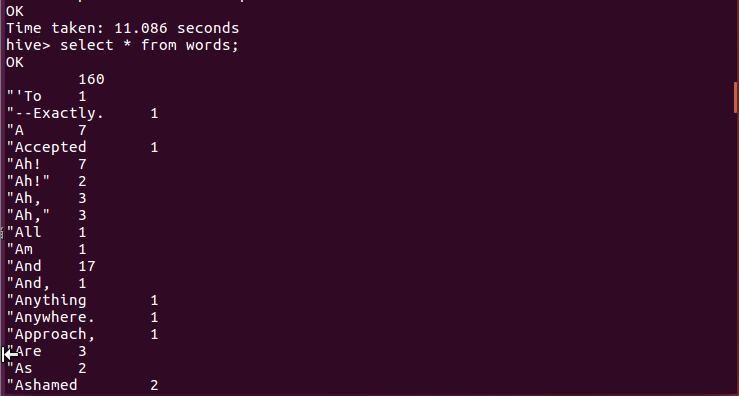
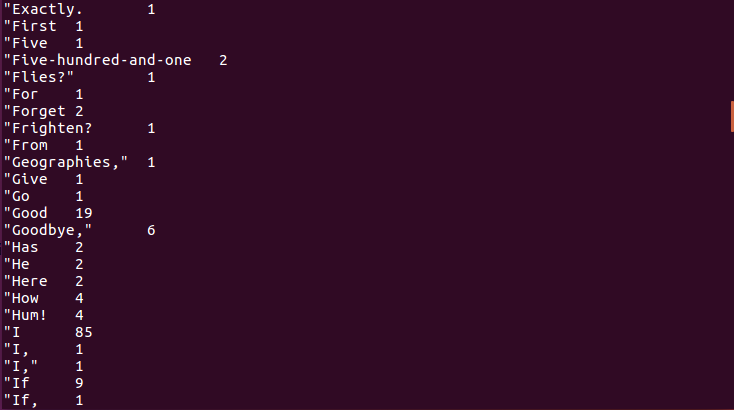
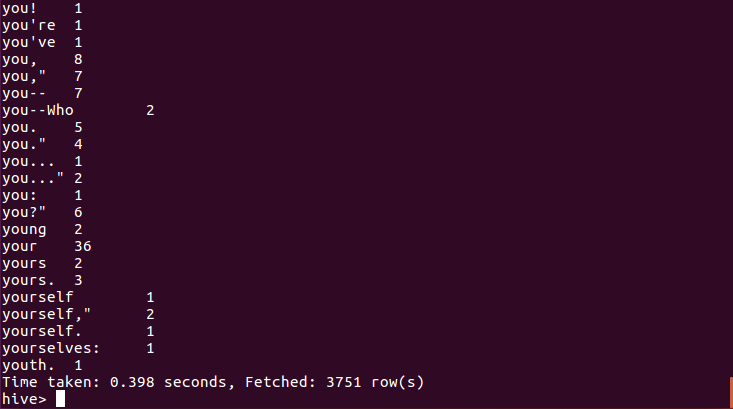
查看统计结果(总共3751 row(s)):
select * from words;

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
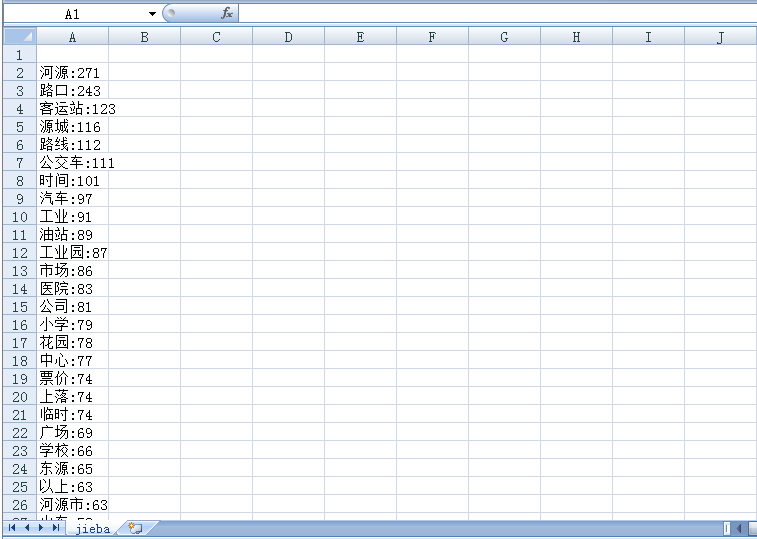
我爬取的是河源市的所有公交信息词频统计后放到jieba.csv文件中:

先把爬取的文件上传到邮箱,然后在虚拟机上下载并放到本地的hadoop文件中:
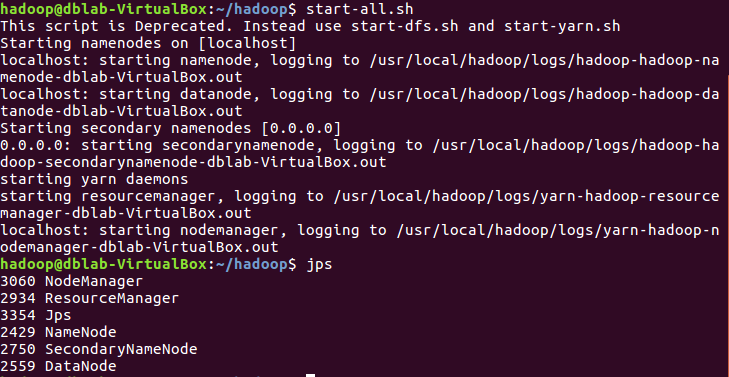
启动hadoop:
start-all.sh jps
将本地系统hadoop文件夹里的jieba.csv上传至hdfs的hive文件夹中:
cd /usr/local/hadoop hdfs dfs -put ~/hadoop/jieba.csv hive

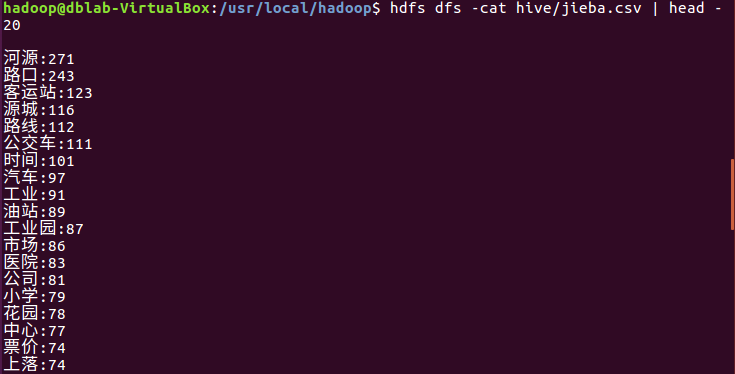
查看hdfs上的jieba.csv文件前20条数据的内容:
hdfs dfs -cat hive/jieba.csv | head -20
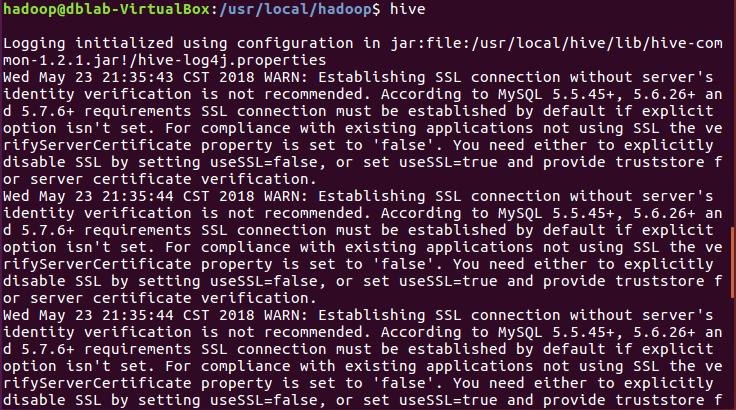
启动hive:
hive
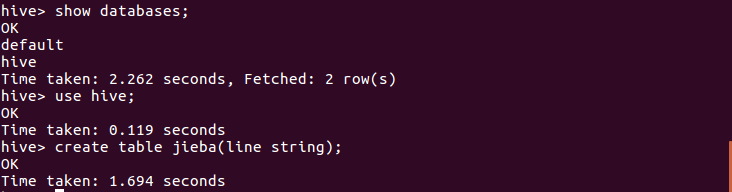
在数据库hive里创建文档表jieba:
show databases; use hive; create table jieba(line string);
导入文件内容到表jieba:
load data inpath '/user/hadoop/hive/jieba.csv' overwrite into table jieba;

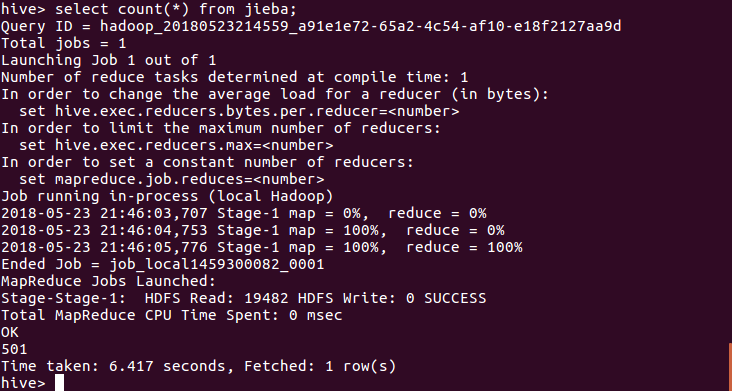
查看表的总数据条数:
select count(*) from jieba;
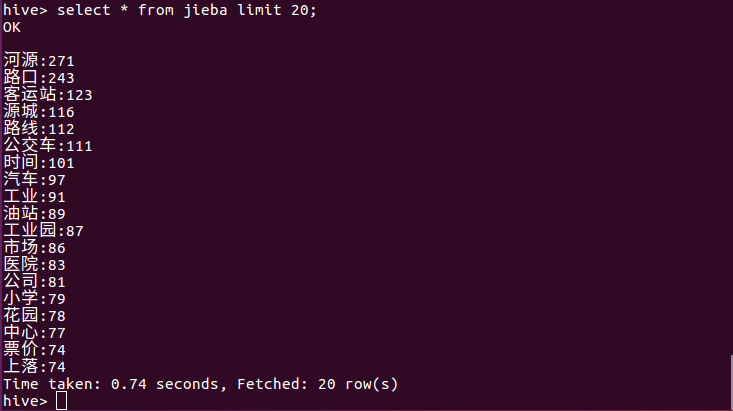
查看表的前20条数据:
select * from jieba limit 20;