什么是HA?
HA的意思是High Availability高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用。
HA方式安装部署才是最常见的生产环境上的安装部署方式。Hadoop HA是Hadoop 2.x中新添加的特性,包括NameNode HA 和 ResourceManager HA。因为DataNode和NodeManager本身就是被设计为高可用的,所以不用对他们进行特殊的高可用处理。
Zookeeper
一、介绍
Zookeeper在Hadoop集群中的作用。
Zookeeper是分布式管理协作框架,Zookeeper集群用来保证Hadoop集群的高可用,(高可用的含义是:集群中就算有一部分服务器宕机,也能保证正常地对外提供服务。)
Zookeeper保证高可用的原理。
Zookeeper集群能够保证NamaNode服务高可用的原理是:Hadoop集群中有两个NameNode服务,两个NaameNode都定时地给Zookeeper发送心跳,告诉Zookeeper我还活着,可以提供服务,单某一个时间只有一个是Action状态,另外一个是Standby状态,一旦Zookeeper检测不到Action NameNode发送来的心跳后,就切换到Standby状态的NameNode上,将它设置为Action状态,所以集群中总有一个可用的NameNode,达到了NameNode的高可用目的。
Zookeeper的选举机制。
Zookeeper集群也能保证自身的高可用,保证自身高可用的原理是,Zookeeper集群中的各个机器分为Leader和Follower两个角色,写入数据时,要先写入Leader,Leader同意写入后,再通知Follower写入。客户端读取数时,因为数据都是一样的,可以从任意一台机器上读取数据。
这里Leader角色就存在单点故障的隐患,高可用就是解决单点故障隐患的。Zookeeper从机制上解决了Leader的单点故障问题,Leader是哪一台机器是不固定的,Leader是选举出来的。选举流程是,集群中任何一台机器发现集群中没有Leader时,就推荐自己为Leader,其他机器来同意,当超过一半数的机器同意它为Leader时,选举结束,所以Zookeeper集群中的机器数据必须是奇数。这样就算当Leader机器宕机后,会很快选举出新的Leader,保证了Zookeeper集群本身的高可用。
写入高可用。
集群中的写入操作都是先通知Leader,Leader再通知Follower写入,实际上当超过一半的机器写入成功后,就认为写入成功了,所以就算有些机器宕机,写入也是成功的。
读取高可用。
zookeeperk客户端读取数据时,可以读取集群中的任何一个机器。所以部分机器的宕机并不影响读取。
zookeeper服务器必须是奇数台,因为zookeeper有选举制度,角色有:领导者、跟随者、观察者,选举的目的是保证集群中数据的一致性。
二、安装zookeeper
在三台机器上安装zookeeper集群,这三台机器的主机名我分别命名为:master、slave1、slave2
去官网下载zookeeper的二进制包到master
<1>解压下载的包
在解压包的时候,先创建一个Hadoop用户,这个用户用于以后管理Hadoop集群,三台机器都要创建。
[root@master ~]# groupadd hadoop
[root@master~]#useradd -g hadoop hadoop
在master机器上操作:
[root@master ~]#su - hadoop
[hadoop@master ~]$ tar -zxvf zookeeper-3.4.13.tar.gz
<2>配置zookeeper:
拷贝conf下的zoo_sample.cfg副本,改名为zoo.cfg。zoo.cfg是zookeeper的配置文件:
[hadoop@master ~]$ cd zookeeper-3.4.13/conf/
[hadoop@master conf]$ cp zoo_sample.cfg zoo.cfg
dataDir属性设置zookeeper的数据文件存放的目录:
dataDir=/home/hadoop/zookeeper-3.4.13/data/zdata
以下是在文件最后添加的:
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
erver后面的数字范围是1到255,所以一个zookeeper集群最多可以有255个机器
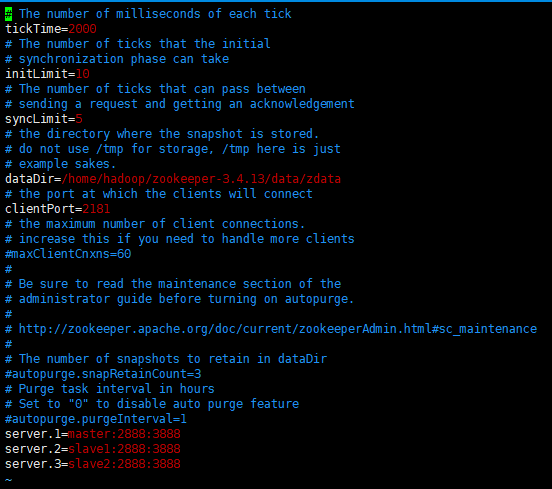
端口解释:
zookeeper一共有三个端口:
2181:客户端连接zookeeper服务器的端口
2888:领导者(leader)监控的端口
3888:zookeeper集群之间相互通信的端口,用于集群选举leader
<3>创建myid文件
在dataDir所指定的目录下创一个名为myid的文件,文件内容为server点后面的数字
[hadoop@master ~]$ mkdir -p /home/hadoop/zookeeper-3.4.13/data/zdata
[hadoop@master zdata]$ pwd
/home/hadoop/zookeeper-3.4.13/data/zdata
hadoop@master zdata]$ touch myid
[hadoop@master zdata]$ echo 1 > myid
分发到其他两台机器,也就是slave1、slave2
[hadoop@master ~]$ scp -r zookeeper-3.4.13/ hadoop@slave1:~
[hadoop@master ~]$ scp -r zookeeper-3.4.13/ hadoop@slave2:~
在其他两台机器修改myid文件
[hadoop@slave1 zdata]$ echo 2 > myid
[hadoop@slave2 zdata]$ echo 3 > myid
<4>启动zookeeper
需要在各个机器上分别启动zookeeper。
[hadoop@slave1 zookeeper-3.4.13]$ pwd
/home/hadoop/zookeeper-3.4.13
[hadoop@master zookeeper-3.4.13]$ ./bin/zkServer.sh start
[hadoop@slave1 zookeeper-3.4.13]$ ./bin/zkServer.sh start
[hadoop@slave2 zookeeper-3.4.13]$ ./bin/zkServer.sh start
<5>zookeeper命令
进入zookeeper Shell
在zookeeper根目录下执行 bin/zkCli.sh进入zk shell模式。
zookeeper很像一个小型的文件系统,/是根目录,下面的所有节点都叫zNode。
进入zk shell 后输入任意字符,可以列出所有的zookeeper命令
[hadoop@slave1 zookeeper-3.4.13]$ ./bin/zkCli.sh
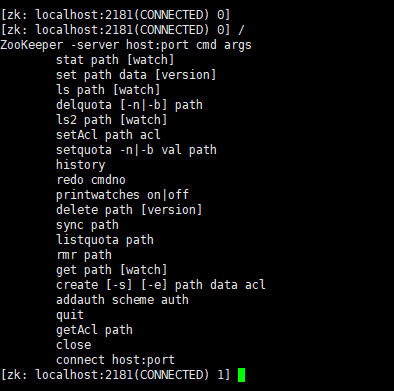
查询zNode上的数据:get /zookeeper
创建一个zNode : create /znode1 “demodata “
列出所有子zNode:ls /
删除znode : rmr /znode1
退出shell模式:quit
安装Hadoop
1、HDFS--HA原理
(1)单NameNode的缺陷存在单点故障的问题,如果NameNode不可用,则会导致整个HDFS文件系统不可用。所以需要设计高可用的HDFS(Hadoop HA)来解决NameNode单点故障的问题。解决的方法是在HDFS集群中设置多个NameNode节点。但是一旦引入多个NameNode,就有一些问题需要解决。
-
HDFS HA需要保证的四个问题:
-
保证NameNode内存中元数据数据一致,并保证编辑日志文件的安全性。
-
多个NameNode如何协作
-
客户端如何能正确地访问到可用的那个NameNode。
-
怎么保证任意时刻只能有一个NameNode处于对外服务状态。
-
-
解决方法
-
对于保证NameNode元数据的一致性和编辑日志的安全性,采用Zookeeper来存储编辑日志文件。
-
两个NameNode一个是Active状态的,一个是Standby状态的,一个时间点只能有一个Active状态的
NameNode提供服务,两个NameNode上存储的元数据是实时同步的,当Active的NameNode出现问题时,通过Zookeeper实时切换到Standby的NameNode上,并将Standby改为Active状态。 - 客户端通过连接一个Zookeeper的代理来确定当时哪个NameNode处于服务状态。
-
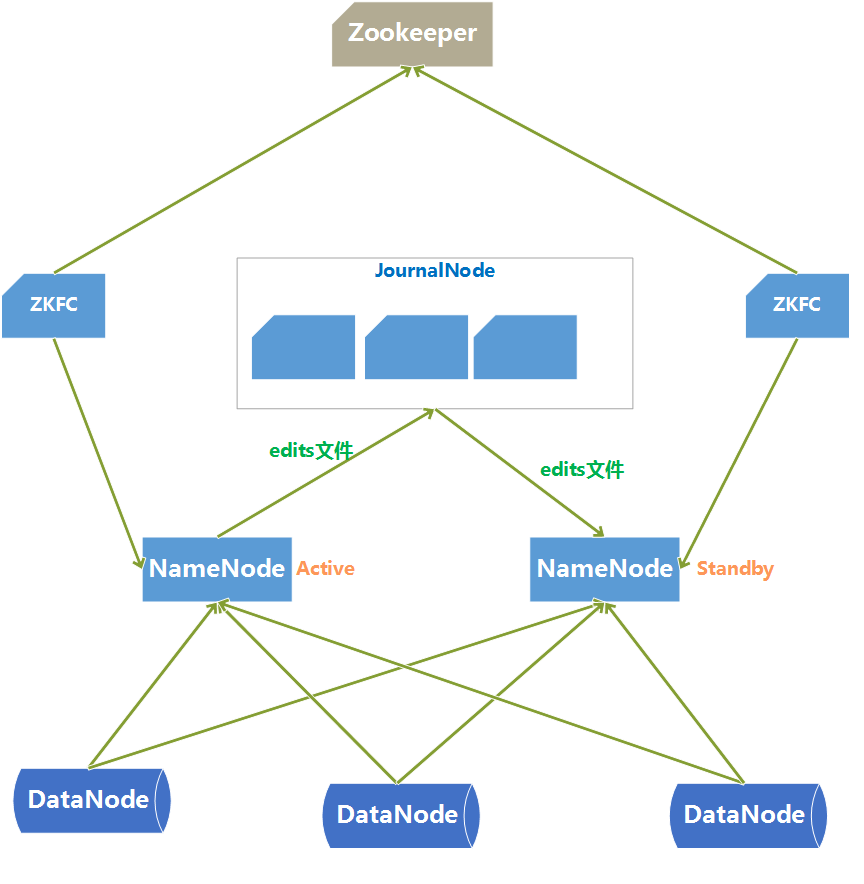
(2)HDFS-HA架构图:
-
HDFS HA架构中有两台NameNode节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
-
元数据文件有两个文件:fsimage和edits,备份元数据就是备份这两个文件。JournalNode用来实时从Active NameNode上拷贝edits文件,JournalNode有三台也是为了实现高可用。
-
Standby NameNode不对外提供元数据的访问,它从Active NameNode上拷贝fsimage文件,从JournalNode上拷贝edits文件,然后负责合并fsimage和edits文件,相当于SecondaryNameNode的作用。最终目的是保证Standby NameNode上的元数据信息和Active NameNode上的元数据信息一致,以实现热备份。
-
Zookeeper来保证在Active NameNode失效时及时将Standby NameNode修改为Active状态。
-
ZKFC(失效检测控制)是Hadoop里的一个Zookeeper客户端,在每一个NameNode节点上都启动一个ZKFC进程,来监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群,其实就是在Zookeeper上创建了一个Znode节点,节点里保存了NameNode状态信息。当NameNode失效后,ZKFC检测到报告给Zookeeper,Zookeeper把对应的Znode删除掉,Standby ZKFC发现没有Active状态的NameNode时,就会用shell命令将自己监控的NameNode改为Active状态,并修改Znode上的数据。
Znode是个临时的节点,临时节点特征是客户端的连接断了后就会把znode删除,所以当ZKFC失效时,也会导致切换NameNode。 -
DataNode会将心跳信息和Block汇报信息同时发给两台NameNode,DataNode只接受Active NameNode发来的文件读写操作指令。
(3)服务器角色规划
| master | slave1 | slave2 |
|---|---|---|
| NameNode | NameNode | |
| Zookeeper | Zookeeper | Zookeeper |
| DataNode | DataNode | DataNode |
| ResourceManage | ResourceManage | |
| NodeManager | NodeManager | NodeManager |
| journalnode | journalnode | journalnode |
2、下载
下载Hadoop二进制包到本地系统,或者你也可以自己创建一个存放包的目录
解压:
[hadoop@master xinjian]$ tar -zxvf hadoop-2.9.0.tar.gz
3、配置JDK路径
1.修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径
2.export JAVA_HOME=/data/jdk1.8.0_181
配置hadoop环境变量
[hadoop@master hadoop-2.9.0]$ vim ~/.bashrc
添加:
export HADOOP_HOME=/home/hadoop/hadoop-2.9.0 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=${HADOOP_HOME} export YARN_HOME=${HADOOP_HOME} export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
[hadoop@master hadoop-2.9.0]$ source ~/.bashrc
4、配置core.site.xml
[hadoop@master hadoop]$ pwd
/home/hadoop/xinjian/hadoop-2.9.0/etc/hadoop
<configuration> <property> <name>hadoop.native.lib</name> <value>false</value> </property> <property> <!-- 从任何主机登录的hadoop用户可以伪装成一个属于任何组的用户--> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> <property> <!-- fs.trash(垃圾).interval(间隔)是在指在这个回收周期之内,文件实际上是被移动到trash的这个目录下面,而不是马上把数据删除掉。等到回收周期真正到了以后,hdfs才会将数据真正删除。默认的单位是分钟,1440分钟=60*24,刚好是一天。 fs.trash.checkpoint.interval则是指垃圾回收的检查间隔,应该是小于或者等于fs.trash.interval。 --> <name>fs.trash.interval</name> <value>1440</value> <description>回收站保存周期</description> </property> <property> <!-- hdfs 地址,ha中是连接到nameservice --> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <property> <!-- dfs产生的数据临时存放的目录,由自己定义 --> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hadoop-2.9.0/tmp</value> </property> <property> <!-- namenode产生的数据存放的目录 --> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/hadoop-2.9.0/name</value> </property> <property> <!-- datanode产生的数据存放的目录。 --> <name>dfs.datanode.name.dir</name> <value>/home/hadoop/hadoop-2.9.0/data</value> </property> <property> <!-- 指定zookeeper地址 quorum(数量,人数)--> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> </configuration>
5、配置hdfs.site.xml
<configuration> <property> <!-- 为namenode集群定义一个services name --> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <!-- nameservice 包含哪些namenode,为各个namenode起名 --> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <!-- 名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯 --> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>master:8020</value> </property> <property> <!-- 名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯 --> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>slave1:8020</value> </property> <property> <!--名为nn1的namenode 的http地址和端口号,web客户端 --> <name>dfs.namenode.http-address.ns1.nn1</name> <value>master:50070</value> </property> <property> <!--名为nn2的namenode 的http地址和端口号,web客户端 --> <name>dfs.namenode.http-address.ns1.nn2</name> <value>slave1:50070</value> </property> <property> <!-- namenode间用于共享编辑日志的journal节点列表 --> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master:8485;slave1:8485;slave2:8485/ns1</value> </property> <property> <!-- journalnode 上用于存放edits日志的目录 --> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/xinjian/hadoop-2.9.0/tmp/data/dfs/jn</value> </property> <property> <!-- 客户端连接可用状态的NameNode所用的代理类 --> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <!-- --> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.journalnode.http-address</name> <value>0.0.0.0:8480</value> </property> <property> <name>dfs.journalnode.rpc-address</name> <value>0.0.0.0:8485</value> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <name>dfs.permissions.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.acls.enabled</name> <value>true</value> </property> </configuration>
6、配置slaves文件
这个文件是指定datanode、nodemanager的节点
[hadoop@master hadoop]$ cat slaves
slave1
slave2
7、分发配置
分发到其他节点
分发之前先将share/doc目录删除,这个目录中是帮助文件,并且很大,可以删除。
[hadoop@master hadoop]$ scp -r ~/xinjian/hadoop-2.9.0/ hadoop@slave1:~/xinjian/
[hadoop@master hadoop]$ scp -r ~/xinjian/hadoop-2.9.0/ hadoop@slave2:~/xinjian/
8、启动journalnode
启动HDFS HA集群
三台机器分别启动Journalnode。
[hadoop@master hadoop-2.9.0]$ pwd
/home/hadoop/xinjian/hadoop-2.9.0
[hadoop@master hadoop-2.9.0]$ ./sbin/hadoop-daemon.sh start journalnode
[hadoop@slave1 hadoop-2.9.0]$ ./sbin/hadoop-daemon.sh start journalnode
[hadoop@slave2 hadoop-2.9.0]$ ./sbin/hadoop-daemon.sh start journalnode
jps命令查看是否启动。
9、格式化namenode
在第一台上进行NameNode格式化:
[hadoop@master hadoop-2.9.0]$ hdfs namenode -format
在第二台NameNode上:
[hadoop@master hadoop-2.9.0]$hdfs namenode -bootstrapStandby #如果这一步失败,那就启动master机器的namenode,在进行这一步。
10、启动NameNode,备节点同步数据
在第一台、第二台上启动NameNode:
[hadoop@master hadoop-2.9.0]$ hadoop-daemon.sh start namenode
[hadoop@slave1 hadoop-2.9.0]$ hadoop-daemon.sh start namenode
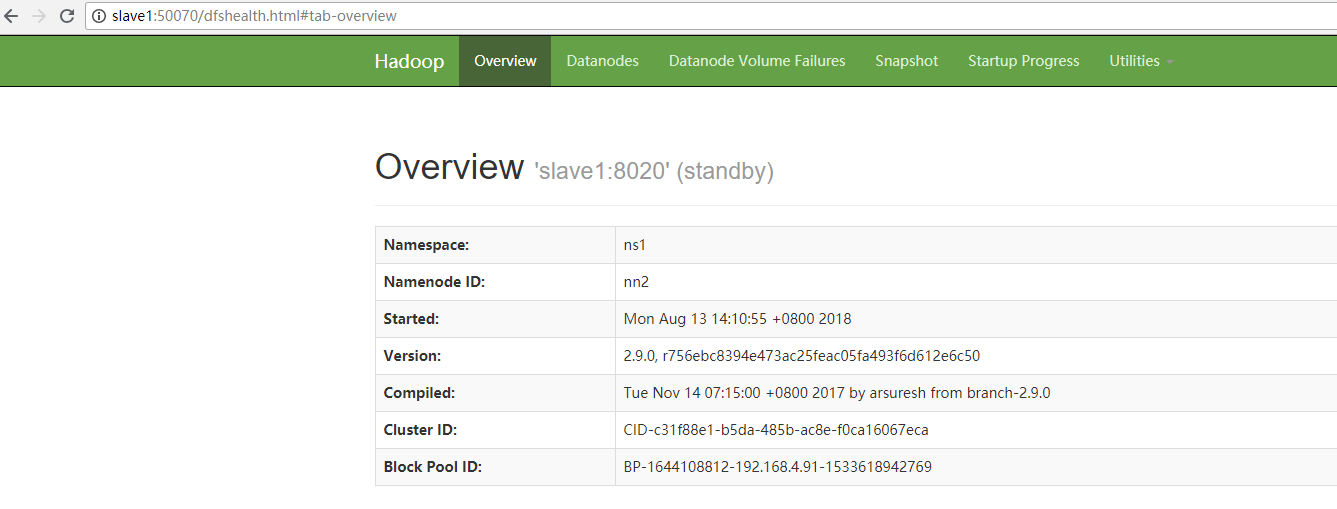
查看HDFS Web页面,此时两个NameNode都是standby状态。
[hadoop@master hadoop-2.9.0]$ hdfs haadmin -transitionToActive nn1
可以添加上forcemanual参数,强制将一个NameNode转换为Active状态。
[hadoop@master hadoop-2.9.0]$ hdfs haadmin -transitionToActive -forcemanual nn1
此时去web界面查看两台namenode的状态
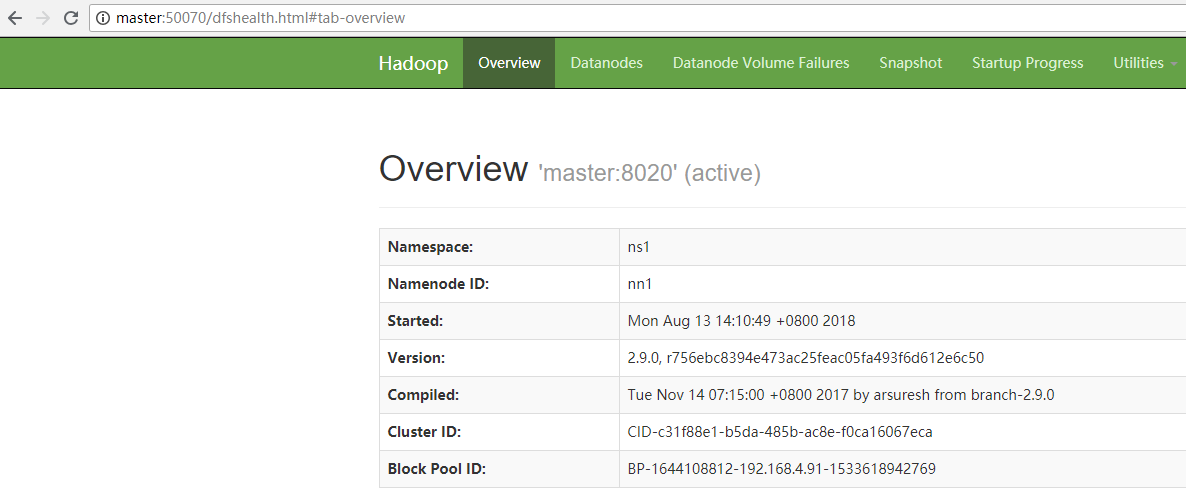
11、配置故障自动转移
利用zookeeper集群实现故障自动转移,在配置故障自动转移之前,要先关闭集群,不能在HDFS运行期间进行配置。
关闭NameNode、DataNode、JournalNode、zookeeper
<1>修改hdfs-site.xml <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <2>修改core-site.xml <property> <!-- 指定zookeeper地址 quorum(数量,人数)--> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> </property>
其实细心的你已经发现我在最上面对这两个文件进行配置的时候,就已经把这两个参数加进去了,,如果,你没有,那就请加进去,然后分发到其他节点。
12、启动集群
<1>三台机器分别启动zookeeper
<2>master机器创建zNode
[hadoop@master hadoop]$hdfs zkfc -formatZK
zNode的作用主要是活跃的namenode节点定期往里面写数据,zookeeper集群通过它来判断该namenode节点是否还活动。
<3>启动NameNode、DataNode、JournalNode、zkfc
[hadoop@master hadoop]$ start-dfs.sh #该脚本可以同时启动它们,就不用一个一个去启动了,怪麻烦的,当然全部进程停止也可以使用[hadoop@master hadoop]$ stop-dfs.sh
zkfc只针对NameNode监听。# zkfc就是zookeeper的失效控制检测器,用于检测namenode的状态。
[hadoop@master hadoop-2.9.0]$ jps
71873 NameNode
72240 DFSZKFailoverController
72359 Jps
72086 JournalNode
5178 QuorumPeerMain
13、测试
<1>测试故障自动转移和数据是否共享
在nn1(master)上传数据
[hadoop@master hadoop-2.9.0]$ hadoop fs -put wc.input /
然后杀掉master上面的namenode进程
[hadoop@master hadoop-2.9.0]$jps
28068 NameNode #28068就是进程号
接下来就去slave1的web界面查看是否有文件
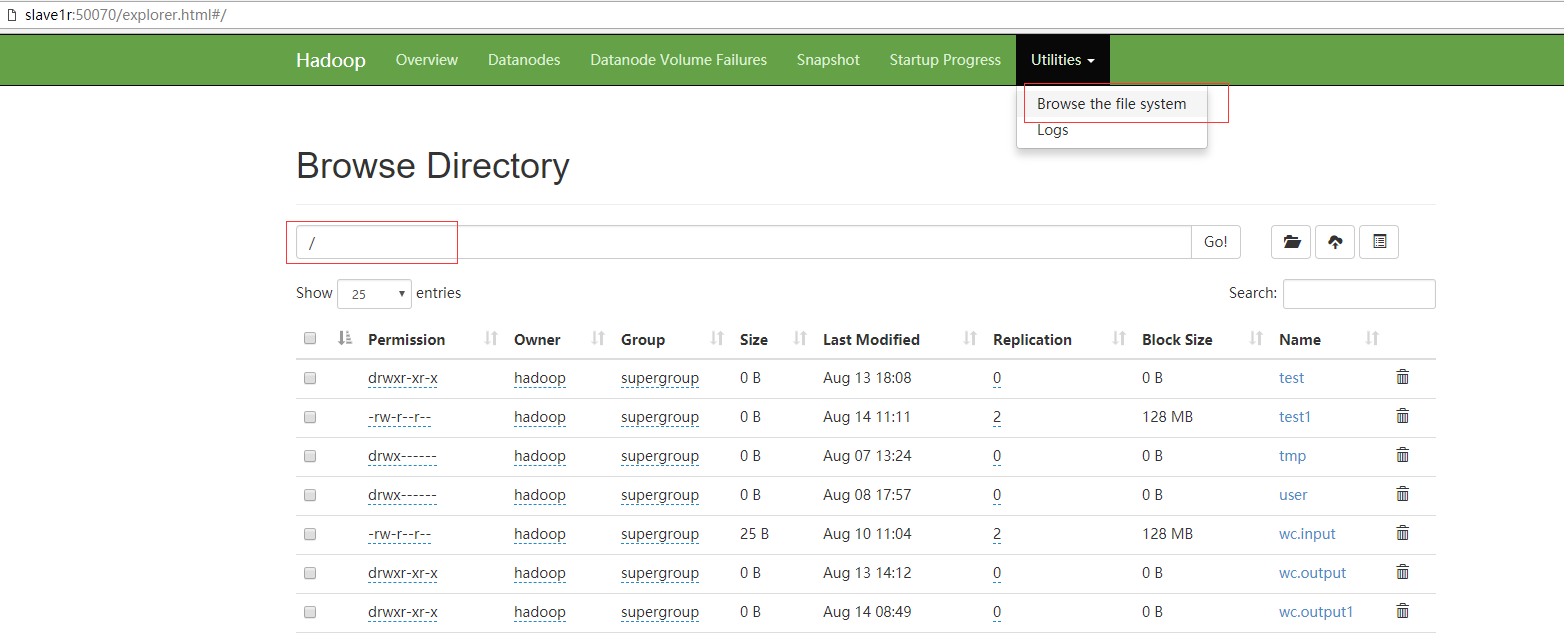
经以上验证,已经实现了nn1和nn2之间的文件同步和故障自动转移。自此,dfs--HA就算搭建完了。
Yarn
1、YARN HA 原理
Hadoop2.4版本之前,ResourceManager也存在单点故障的问题,也需要实现HA来保证ResourceManger的高可也用性。
ResouceManager从记录着当前集群的资源分配情况和JOB的运行状态,YRAN HA 利用Zookeeper等共享存储介质来存储这些信息来达到高可用。另外利用Zookeeper来实现ResourceManager自动故障转移。
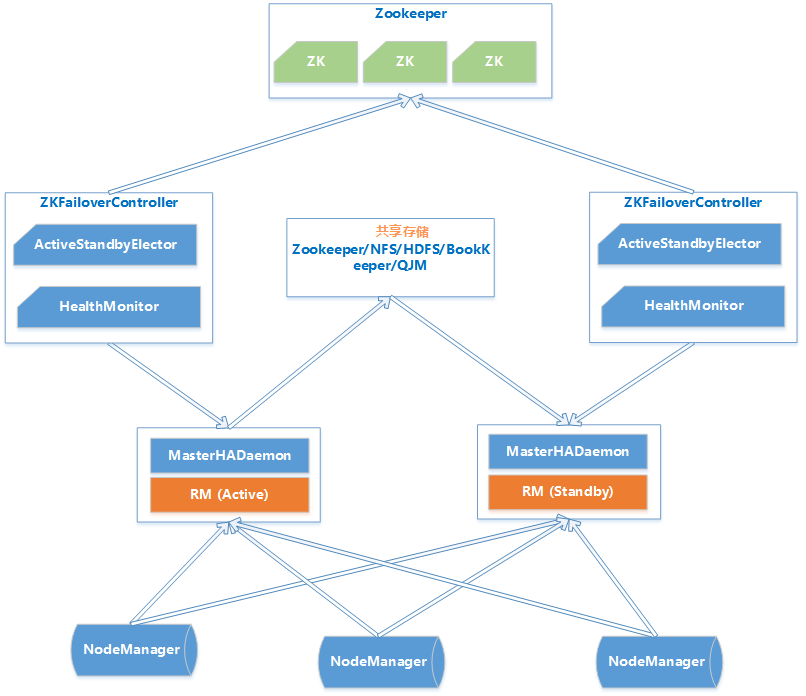
-
MasterHADaemon:控制RM的 Master的启动和停止,和RM运行在一个进程中,可以接收外部RPC命令。
-
共享存储:Active Master将信息写入共享存储,Standby Master读取共享存储信息以保持和Active Master同步。
-
ZKFailoverController:基于Zookeeper实现的切换控制器,由ActiveStandbyElector和HealthMonitor组成,ActiveStandbyElector负责与Zookeeper交互,判断所管理的Master是进入Active还是Standby;HealthMonitor负责监控Master的活动健康情况,是个监视器。
-
Zookeeper:核心功能是维护一把全局锁控制整个集群上只有一个Active的ResourceManager。
| master | slave1 | slave2 |
|---|---|---|
| NameNode | NameNode | |
| Zookeeper | Zookeeper | Zookeeper |
| DataNode | DataNode | DataNode |
| ResourceManage | ResourceManage | |
| NodeManager | NodeManager | NodeManager |
| journalnode | journalnode | journalnode |
2、配置yarn.site.xml
<configuration> <property> <name>yarn.resourcemanager.connect.retry-interval.ms</name> <value>2000</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> <description>启动Yran HA模式</description> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> <description>resourcemanager id</description> </property> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> <description>Zookeeper 队列</description> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> <description>开启 ResourceManager 故障自动切换</description> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master</value> <description>rm1 的hostname</description> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>slave1</value> <description>rm2 的hostname</description> </property> <property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> <description>本机的rmid</description> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.zk-state-store.address</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>LN-rslog</value> <description>集群ID</description> </property> <property> <name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name> <value>5000</value> </property> <description>以下开始对 rm1 进行配置,rm2 改成对应的值!!!</description> <property> <name>yarn.resourcemanager.address.rm1</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master:8088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm1</name> <value>master:23142</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>slave1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>slave1:8030</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>slave1:8088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>slave1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>slave1:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm2</name> <value>slave1:23142</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/home/hadoop/xinjian/hadoop-2.9.0/data/nm</value> </property> <property> <!-- yarn node 运行时日志存放地址,记录container日志,并非nodemanager日志存放地址 --> <name>yarn.nodemanager.log-dirs</name> <value>/home/hadoop/xinjian/hadoop-2.9.0/log/yarn</value> </property> <property> <name>mapreduce.shuffle.port</name> <value>23080</value> </property> <property> <name>yarn.client.failover-proxy-provider</name> <value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name> <value>/yarn-leader-election</value> </property> <property> <name>yarn.nodemanager.vcores-pcores-ratio</name> <value>1</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>5.2</value> </property> <!--
配置解释:
(1)yarn.nodemanager.vmem-pmem-ratio
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1
(2) yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(3) yarn.nodemanager.vmem-check-enabled
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<!-- 表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数 -->
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<!-- 表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节>点的物理内存总量。 -->
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<!-- 单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数 -->
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<!-- 单个任务可申请的最多物理内存量,默认是8192(MB)。
默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于Cgroups对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报OOM),而Java进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此YARN未提供Cgroups内存隔离机制 -->
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
</property>
</configuration>
3、分发配置
同样,配置完成以后,分发到其他机器
[hadoop@master hadoop-2.9.0]$ scp -r etc/hadoop/yarn-site.xml hadoop@slave1:~/xinjian/hadoop-2.9.0/etc/hadoop/
[hadoop@master hadoop-2.9.0]$ scp -r etc/hadoop/yarn-site.xml hadoop@slave2:~/xinjian/hadoop-2.9.0/etc/hadoop/
4、启动yarn
在master启动yarn
[hadoop@master hadoop-2.9.0]$start-yarn.sh
在slave1启动resourcemanager
[hadoop@slave1 hadoop-2.9.0]$ yarn-daemon.sh start resourcemanager
启动以后,各个节点进程
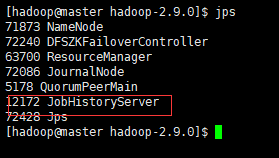
红框里面的这个进程是由于我开启了历史服务。如果你没开启,那就没这个进程,我上面配置文件已经配置了该参数。
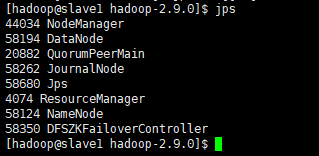
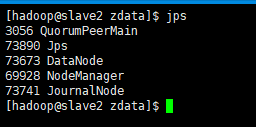
Web客户端访问master机器上的resourcemanager正常,它是active状态的。
访问另外一个resourcemanager,因为他是standby,会自动跳转到active的resourcemanager。
5、测试yarn ha
在master运行一个mapreduce job
[hadoop@master hadoop-2.9.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount /wc.input /wc.output
在job运行过程中,将Active状态的resourcemanager进程杀掉。
[hadoop@master hadoop-2.9.0]$ kill -9 63700观察另外一个resourcemanager(slave1)是否可以自动接替。
master的resourcemanage Web客户端已经不能访问,slave1的resourcemanage已经自动变为active状态。
观察job是否可以顺利完成。
而mapreduce job 也能顺利完成,没有因为resourcemanager的意外故障而影响运行。
经过以上测试,已经验证YARN HA 已经搭建成功。
6、资源调度
以下配置仅供参考:
[hadoop@master hadoop]$ pwd
/home/hadoop/xinjian/hadoop-2.9.0/etc/hadoop
[hadoop@master hadoop]$ cat capacity-scheduler.xml # yarn容量调度配置文件
<!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,hadoop,orc</value> </property> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>0</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.capacity</name> <value>65</value> </property> <property> <name>yarn.scheduler.capacity.root.orc.capacity</name> <value>35</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.user-limit-factor</name> <value>1</value> <description> Default queue user limit a percentage from 0.0 to 1.0. </description> </property> <property> <name>yarn.scheduler.capacity.root.orc.user-limit-factor</name> <value>1</value> <description> Default queue user limit a percentage from 0.0 to 1.0. </description> </property> <property> <name>yarn.scheduler.capacity.root.orc.maximum-capacity</name> <value>100</value> <description> The maximum capacity of the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.maximum-capacity</name> <value>100</value> <description> The maximum capacity of the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_submit_applications</name> <value>default</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.acl_submit_applications</name> <value>hadoop</value> </property> <property> <name>yarn.scheduler.capacity.root.hadoop.acl_administer_queue</name> <value>hadoop</value> </property> </configuration>
借鉴:
https://blog.csdn.net/hliq5399/article/details/78193113
写的很不错,建议看一下