原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了?
浏览器请求数据方式:浏览器向服务器的api(例如这样的字符串:http://api.qingyunke.com/api.php?key=free&appid=0&msg=关键词)发送请求,服务器返回json,然后解析该json,就得到请求数据了
同理:用Python向api发送请求,获得json,解析json,得到数据
即关键在于得到api
api获取:
1.用浏览器打开目标网页eg:https://www.zhihu.com/topic/19561718/top-answers
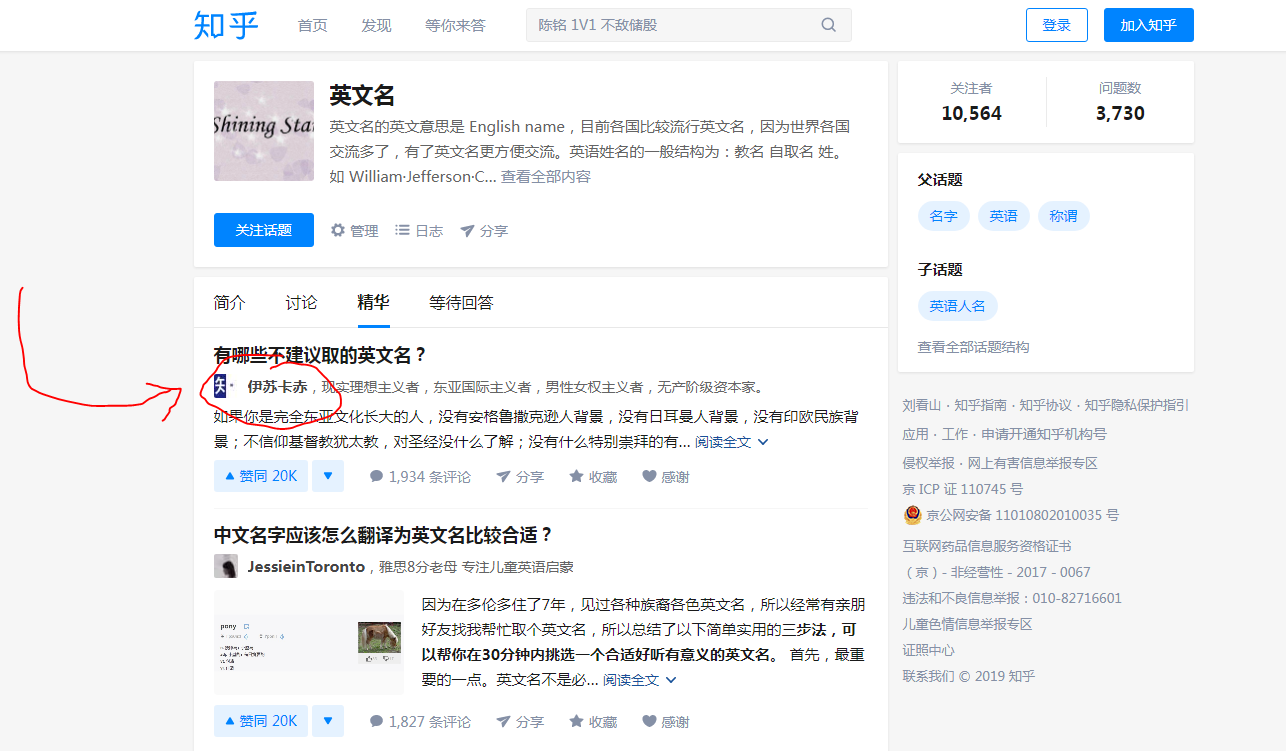
将鼠标放在上图图示位置,将显示该用户的一些信息,这些信息就是动态加载出来的。当鼠标放在该位置时,浏览器向服务器api发出请求,得到json,再解析便得到下图所示数据

在该网页反键选择检查源代码,按图示点开选项:
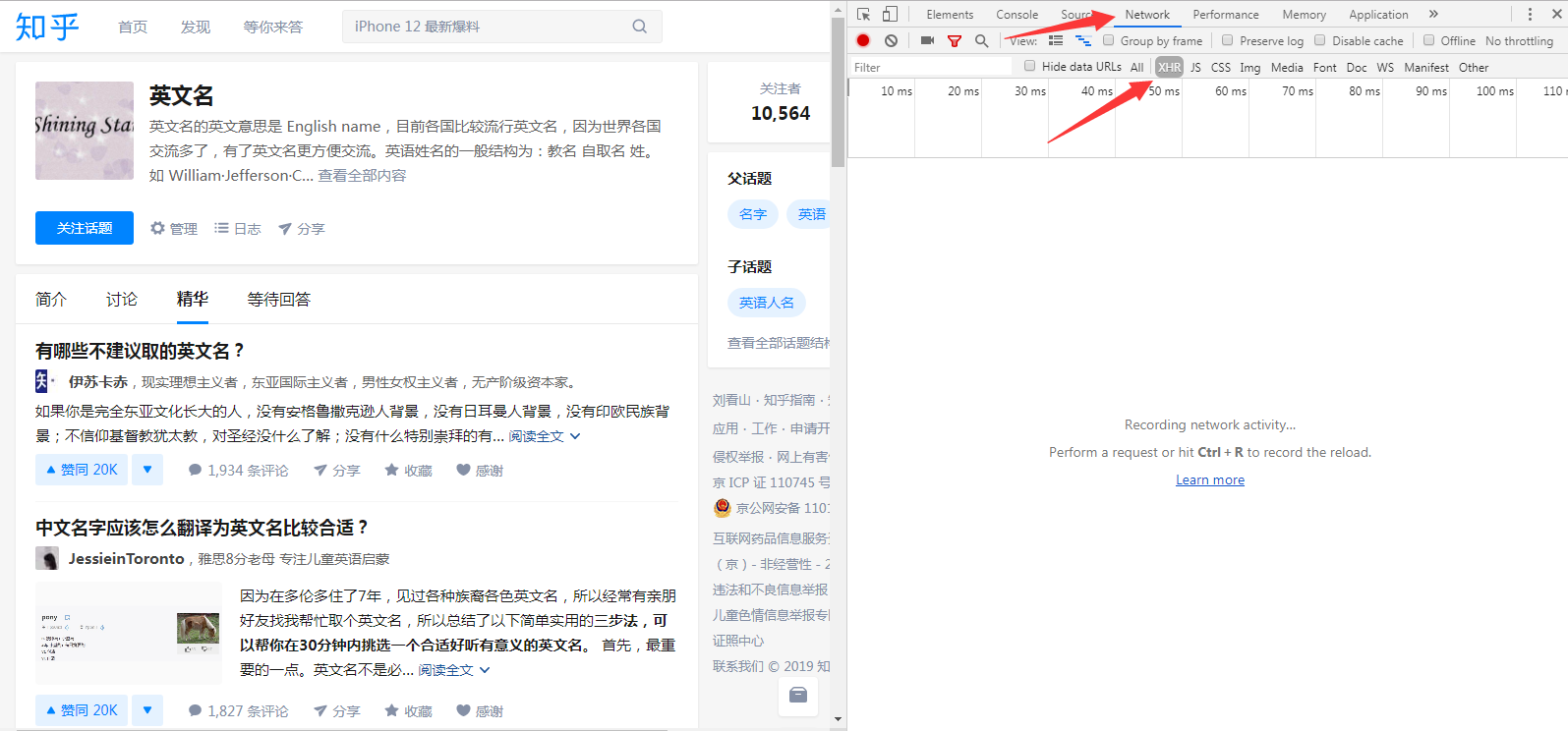
然后将鼠标移动到网页界面用户上(箭头位置),会发现右边多出两个请求信息,如图:
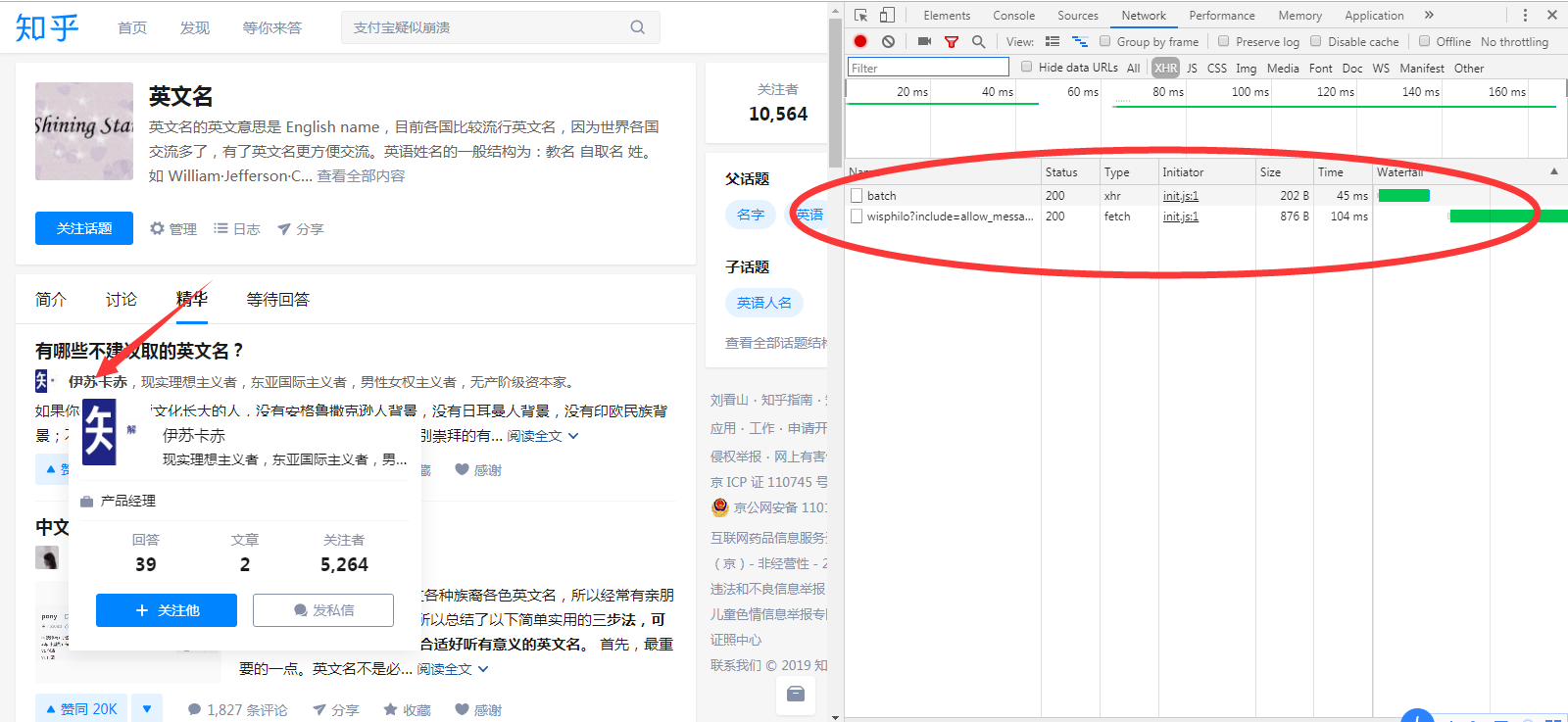
点击下面一个,红色方框内的链接,就是要找的api接口
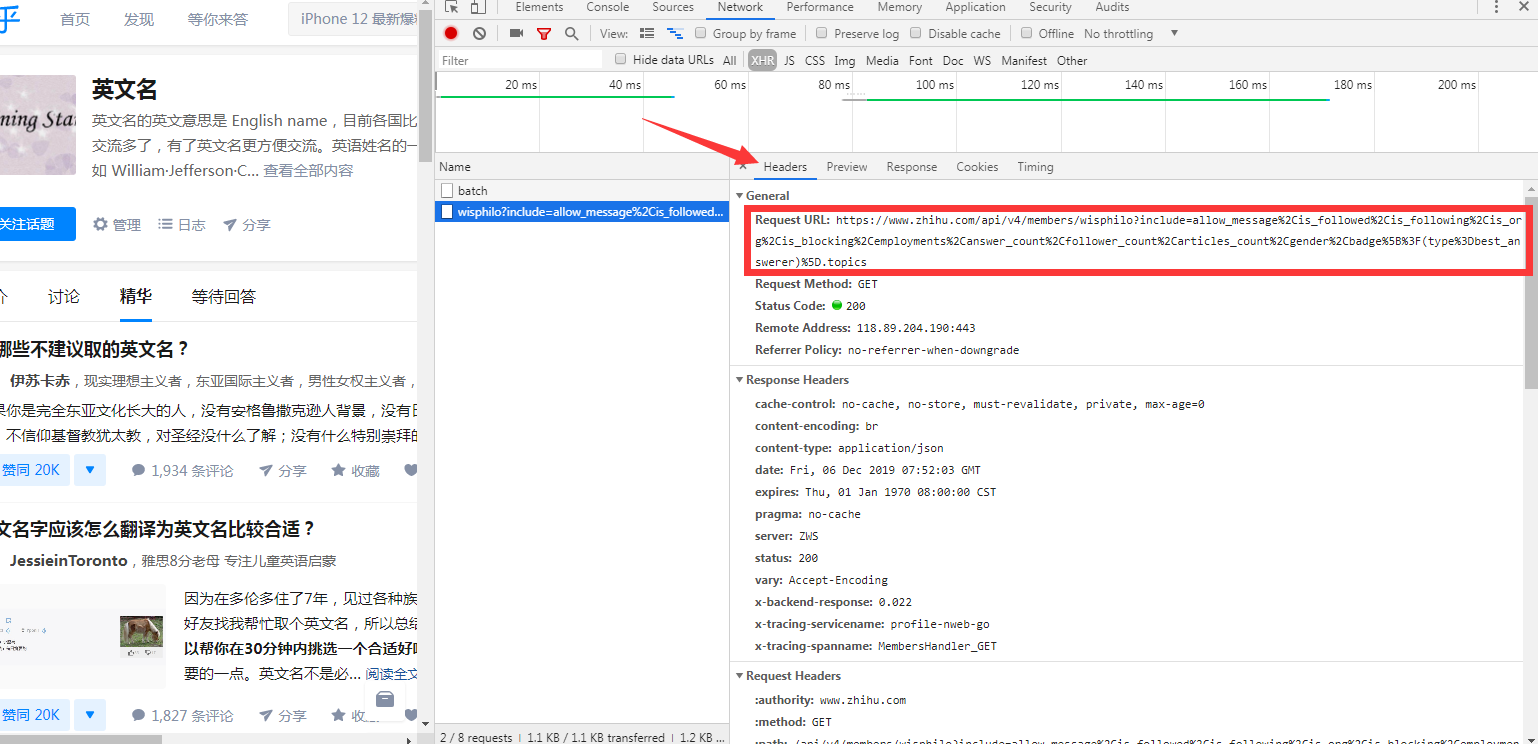
直接用浏览器打开该api即可看到json,如下图
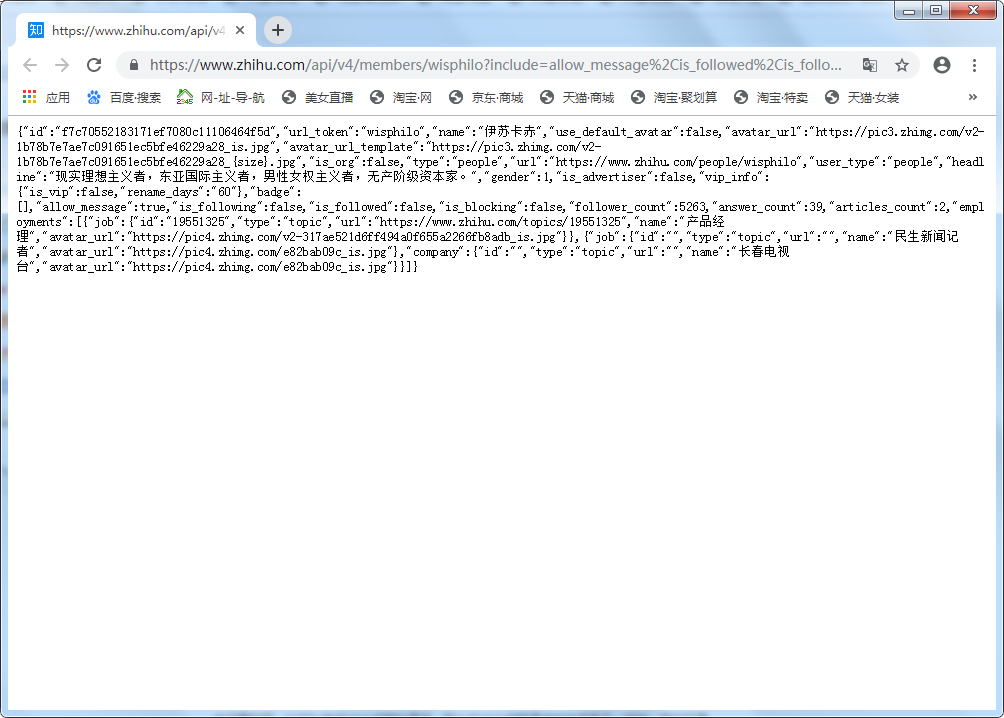
下面用python代码请求该api并解析
import requests
import json
#api
url='https://www.zhihu.com/api/v4/members/wisphilo?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics'
#header的目的是模拟请求,因为该api设置了反爬取
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
doc=requests.get(url,headers=header)#发起请求
doc.encoding='utf-8'#设置编码为utf-8
data=json.loads(doc.text)#将json字符串转为json
#根据位置查找数据
print('用户名:',data.get('name'))
print('个人描述:',data.get('headline'))
print('职务:'+data.get('employments')[0].get('job').get('name'))
print('回答:',data.get('answer_count'))
print('文章:',data.get('articles_count'))
print('关注者:',data.get('follower_count'))
另外查找数据最好用在线json格式化再查找,不然很难看出自己要的数据在哪eg:

一般网页的api都有规律可寻,用for循环控制变换字符即可实现自动爬取
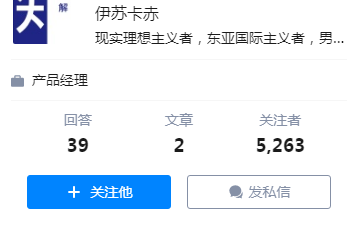
上述代码运行结果:

和该界面对照
以上