目的:给我们项目的微服务应用都加上监控告警。在这之前你需要将 Spring Boot Actuator引入
本章主要介绍
- 如何集成监控告警系统Prometheus 和图形化界面Grafana
- 如何自定义监控指标
- Prometheus 如何集成 Alertmanager 进行告警
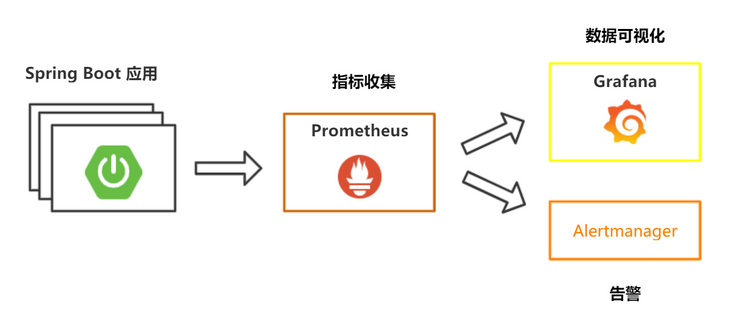
基本概念
Prometheus
Prometheus 中文名称为普罗米修斯,受启发于Google 的Brogmon 监控系统,从2012年开始由前Google工程师在Soundcloud 以开源软件的形式进行研发,2016年6月发布1.0版本。Prometheus 可以看作是 Google 内部监控系统Borgmon 的一个实现。
下图说明了Prometheus 的体系结构及其部分生态系统组件。其中 Alertmanager 用于告警,Grafana 用于监控数据可视化,会在文章后面继续提到。
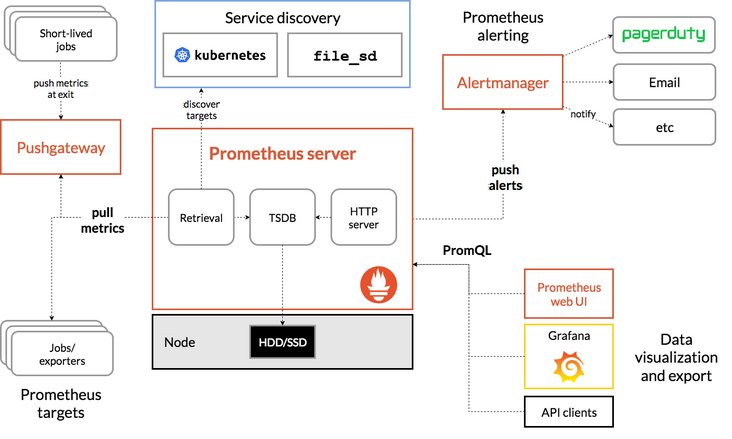
在这里我们了解到Prometheus 这几个特征即可:
- 数据收集器,它以配置的时间间隔定期通过HTTP提取指标数据。
- 一个时间序列数据库,用于存储所有指标数据。
- 一个简单的用户界面,您可以在其中可视化,查询和监视所有指标。
详细了解请阅读Prometheus 官方文档
Grafana
Grafana 是一款采用 go 语言编写的开源应用,允许您从Elasticsearch,Prometheus,Graphite,InfluxDB等各种数据源中获取数据,并通过精美的图形将其可视化。
除了Prometheus的AlertManager 可以发送报警,Grafana 同时也支持告警。Grafana 可以无缝定义告警在数据中的位置,可视化的定义阈值,并可以通过钉钉、email等平台获取告警通知。最重要的是可直观的定义告警规则,不断的评估并发送通知。
由于Grafana alert告警比较弱,大部分告警都是通过Prometheus Alertmanager进行告警.
请注意Prometheus仪表板也具有简单的图形。 但是Grafana的图形化要好得多。
延伸阅读:
Alertmananger
Prometheus 监控平台中除了负责采集数据和存储,还能定制事件规则,但是这些事件规则要实现告警通知的话需要配合Alertmanager 组件来完成。
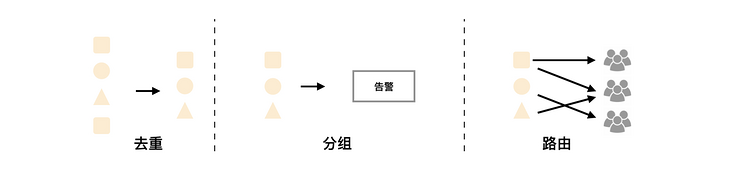
AlertManager 支持告警分组(将多个告警合并一起发送)、告警抑制以及告警静默(同一个时间段内不发出重复的告警)功能。
延伸阅读:官网对Alertmanager的介绍
监控Java 应用
监控模式
目前,监控系统采集指标有两种方式,一种是『推』,另一种就是『拉』:
推的代表有 ElasticSearch,InfluxDB,OpenTSDB 等,需要你从程序中将指标使用 TCP,UDP 等方式推送至相关监控应用,只是使用 TCP 的话,一旦监控应用挂掉或存在瓶颈,容易对应用本身产生影响,而使用 UDP 的话,虽然不用担心监控应用,但是容易丢数据。
拉的代表,主要代表就是 Prometheus,让我们不用担心监控应用本身的状态。而且可以利用 DNS-SRV 或者 Consul 等服务发现功能就可以自动添加监控。
如何监控
Prometheus 监控应用的方式非常简单,只需要进程暴露了一个用于获取当前监控样本数据的 HTTP 访问地址。这样的一个程序称为Exporter,Exporter 的实例称为一个 Target 。Prometheus 通过轮训的方式定时从这些 Target 中获取监控数据样本,对于应用来讲,只需要暴露一个包含监控数据的 HTTP 访问地址即可,当然提供的数据需要满足一定的格式,这个格式就是 Metrics 格式.
metric name>{<label name>=<label value>, ...}主要分为三个部分
各个部分需符合相关的正则表达式
- metric name:指标的名称,主要反映被监控样本的含义
a-zA-Z_:*_ - label name: 标签 反映了当前样本的特征维度
[a-zA-Z0-9_]* - label value: 各个标签的值,不限制格式
需要注意的是,label value 最好使用枚举值,而不要使用无限制的值,比如用户 ID,Email 等,不然会消耗大量内存,也不符合指标采集的意义。
前面简述了Prometheus 监控的原理。那么我们的Spring Boot 应用怎么提供这样一个 HTTP 访问地址,提供的数据还得符合上述的 Metrics 格式 ?
Spring Boot 提供了所谓的 endpoints (下文翻译为端点)给外部来与应用程序进行访问和交互。
打比方来说,/health 端点 提供了关于应用健康情况的一些基础信息。metrics 端点提供了一些有用的应用程序指标(JVM 内存使用、系统CPU使用等)。
这些 Actuator 模块本来就有的端点我们称之为原生端点。根据端点的作用的话,我们大概可以分为三大类:
- 应用配置类:获取应用程序中加载的应用配置、环境变量、自动化配置报告等与Spring Boot应用密切相关的配置类信息。
- 度量指标类:获取应用程序运行过程中用于监控的度量指标,比如:内存信息、线程池信息、HTTP请求统计等。
- 操作控制类:提供了对应用的关闭等操作类功能。
详细的原生端点介绍,请以官网为准,这里就不赘述徒增篇幅。
需要注意的就是:
- 每一个端点都可以通过配置来单独禁用或者启动
- 不同于Actuator 1.x,Actuator 2.x 的大多数端点默认被禁掉。 Actuator 2.x 中的默认端点增加了
/actuator前缀。默认暴露的两个端点为/actuator/health和/actuator/info
端点暴露配置
我们可以通过以下配置,来配置通过JMX 和 HTTP 暴露的端点。
| Property | Default |
|---|---|
management.endpoints.jmx.exposure.exclude |
|
management.endpoints.jmx.exposure.include |
* |
management.endpoints.web.exposure.exclude |
|
management.endpoints.web.exposure.include |
info, healt |
可以打开所有的监控点
management.endpoints.web.exposure.include=*
也可以选择打开部分,"*" 代表暴露所有的端点,如果指定多个端点,用","分开
management.endpoints.web.exposure.exclude=beans,trace
Actuator 默认所有的监控点路径都在/actuator/*,当然如果有需要这个路径也支持定制。
management.endpoints.web.base-path=/minitor
设置完重启后,再次访问地址就会变成/minitor/*。
现在我们按照如下配置:
| # "*" 代表暴露所有的端点 如果指定多个端点,用","分开 | |
| # 赋值规则同上 | |
启动DEMO程序,访问http://localhost:8080/actuator,查看暴露出来的端点:

搭建部分
基础环境Centos7 docker搭建
离线安装,下载如下4个 rpm 包
[root@jws-ftp docker]# ll 总用量 104280 -rw-r--r--. 1 root root 34677436 2月 19 11:41 containerd.io-1.4.3-3.1.el7.x86_64.rpm -rw-r--r--. 1 root root 27887312 2月 19 11:41 docker-ce-20.10.3-3.el7.x86_64.rpm -rw-r--r--. 1 root root 34721064 2月 19 11:41 docker-ce-cli-20.10.3-3.el7.x86_64.rpm -rw-r--r--. 1 root root 9486464 2月 19 11:41 docker-ce-rootless-extras-20.10.3-3.el7.x86_64.rpm [root@jws-ftp docker]#
#本地安装 [root@jws-ftp docker]# yum localinstall -y *.rpm 注:确保本地有可用的yum源,因为安装docker时有一些依赖需要通过yum源安装
启动docker并设置开机自启动
[root@jws-ftp docker]# systemctl start docker [root@jws-ftp docker]# systemctl enable docker
查找远端是否有 prometheus 镜像
[root@jws-ftp docker]# docker search prometheus
注:如果别的环境有下载过docker镜像,可以直接导出镜像拷贝至新环境后,然后导入
示例: 导出 [root@monitor consul]# docker save -o nginx.tar nginx:latest 导入 [root@monitor consul]# docker load -i nginx.tar
由于本人是内网环境,所以需要配置代理(可直接联网的忽略此操作),代理使用CCproxy,(CCproxy配置指导)
#yum配置代理 [root@jws-ftp docker.service.d]# echo 'proxy=http://10.153.49.7:8888' >> /etc/yum.conf #查看docker环境 [root@jws-ftp docker.service.d]# systemctl show --property=Environment docker #配置docker代理 [root@jws-ftp docker.service.d]# mkdir -p /etc/systemd/system/docker.service.d [root@jws-ftp docker.service.d]# cat /etc/systemd/system/docker.service.d/http-proxy.conf [Service] Environment="HTTP_PROXY=http://10.153.49.7:8888/" [root@jws-ftp docker.service.d]# [root@jws-ftp docker.service.d]# systemctl daemon-reload [root@jws-ftp docker.service.d]# systemctl restart docker #确认docker环境配置 [root@jws-ftp docker.service.d]# systemctl show --property=Environment docker
一、Prometheus 安装与配置
代理配置完成后,拉取prometheus镜像
#拉取prometheus镜像 [root@jws-ftp docker.service.d]# docker pull prom/prometheus #查看镜像 [root@jws-ftp docker.service.d]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE prom/prometheus latest a618f5685492 4 weeks ago 175MB [root@jws-ftp docker.service.d]# #拉取grafana镜像 [root@jws-ftp docker.service.d]# docker pull grafana/grafana #查看镜像 [root@jws-ftp docker.service.d]# [root@jws-ftp docker.service.d]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE prom/prometheus latest a618f5685492 4 weeks ago 175MB grafana/grafana latest db33d19bd973 4 weeks ago 198MB [root@jws-ftp docker.service.d]#
配置prometheus.yml,创建docker容器时将配置文件挂载至容器目录
[root@jws-ftp prometheus]# cat /jws/prometheus/prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: 'springboot-actuator-prometheus-test' # job name
metrics_path: '/actuator/prometheus' # 指标获取路径
scrape_interval: 5s # 间隔
static_configs:
- targets: ['10.153.49.7:8080'] # 实例的地址,默认的协议是http
labels:
instance: springboot-actuator-prometheus-test
[root@jws-ftp prometheus]#
重点请关注这里的配置:
- job_name: 'springboot-actuator-prometheus-test' # job name
metrics_path: '/actuator/prometheus' # 指标获取路径
scrape_interval: 5s # 间隔
static_configs:
- targets: ['10.153.49.7:8080'] # 实例的地址,默认的协议是http
labels:
instance: springboot-actuator-prometheus-test
测试
配置完成之后,我们启动Prometheus 测试一下,如果你是docker 方式的话,在prometheus.yml 文件所在目录执行如下命令,即可启动Prometheus:
[root@jws-ftp prometheus]# docker run -d -p 9090:9090 --name prometheus -v /jws/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
- 访问
http://ip:9090,可看到如下界面:

- 点击
Insert metric at cursor,即可选择监控指标;点击Graph,即可让指标以图表方式展示;点击Execute按钮,即可看到类似下图的结果
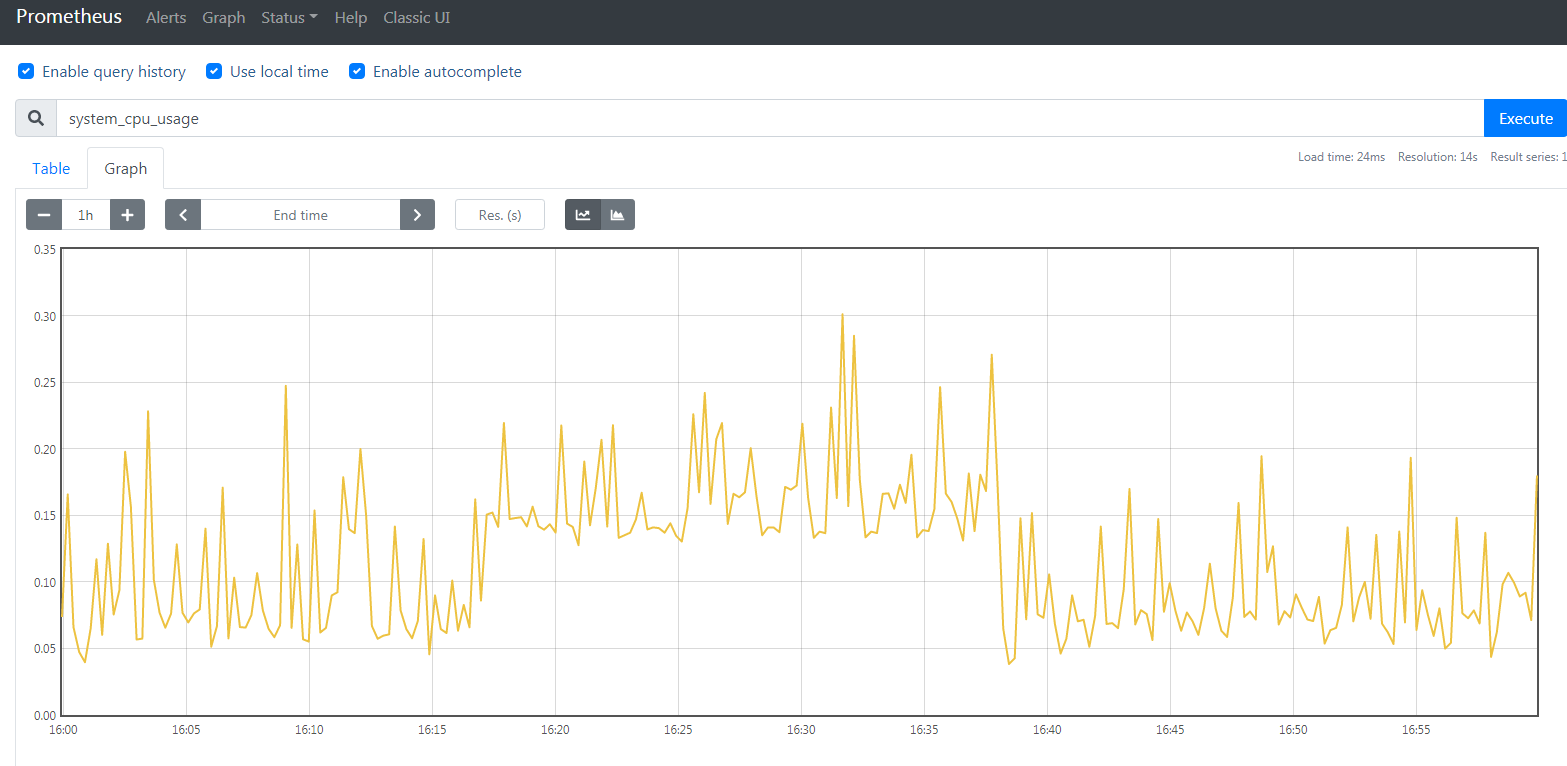
你也可以在输入框中输入PromQL来进行更高级的查询。
PromQL是Prometheus 的自定义查询语言,通过PromQL用户可以非常方便地对监控样本数据进行统计分析。
- 配置热加载
curl -X POST http://ip:9090/-/reload二、Grafana安装和配置
可以看到,Prometheus 自带的监控面板非常“简陋”。所以引入Grafana 来实现更友好、更贴近生产的监控可视化。
1. 启动
[root@jws-ftp prometheus]# mkdir /jws/grafana-storage #创建收集信息的目录 [root@jws-ftp prometheus]#chmod 777 /jws/grafana-storage #给予777权限 [root@jws-ftp prometheus]# docker run -d -p 3000:3000 --name=grafana -v /jws/grafana-storage:/var/lib/grafana grafana/grafana #因为镜像在之前步骤中已经pull下来,所以直接启动容器
2. 登录
访问 http://ip:3000/login ,初始账号/密码为:admin/admin ,第一次登录会让你修改密码。
3. 配置数据源
- 点击
Configuration中Add Data Source,会看到如下界面:
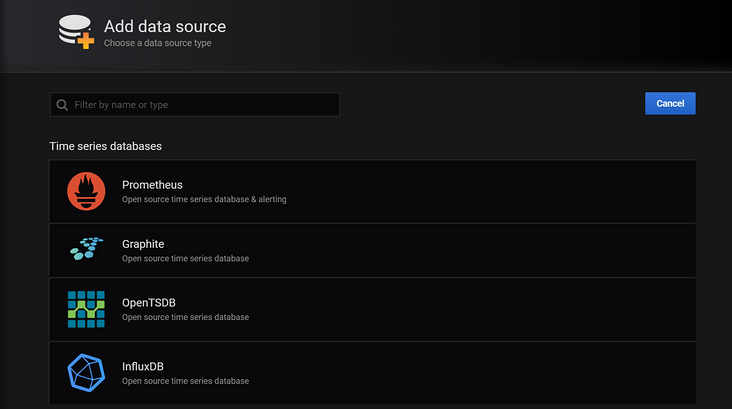
- 这里我们选择Prometheus 当做数据源,这里我们就配置一下Prometheus 的访问地址,点击
Save & Test:

4. 创建监控Dashboard
- 点击导航栏上的
+按钮,并点击Dashboard,将会看到类似如下的界面:
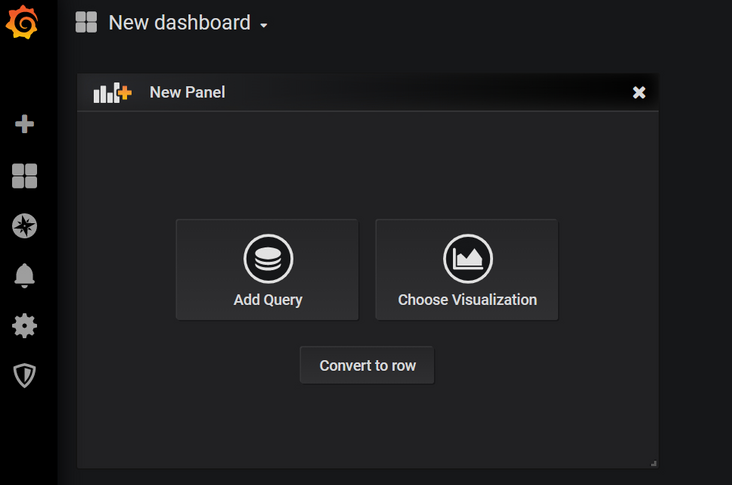
- 点击
Add Query,即可看到类似如下的界面:
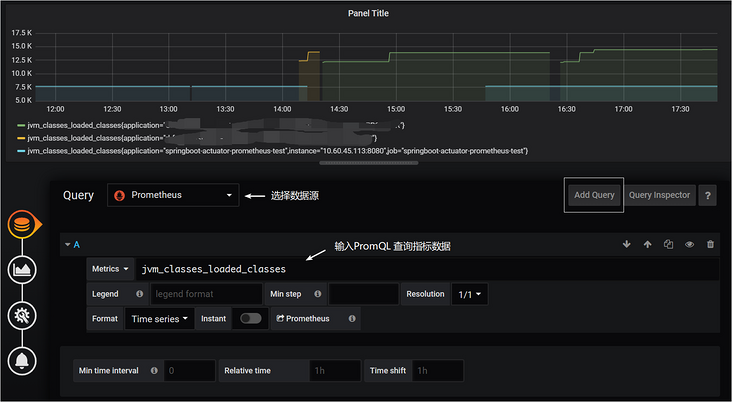
在Metrics处输入要查询的指标,指标的取值详见Spring Boot应用的 /actuator/prometheus 端点,例如jvm_memory_used_bytes 、jvm_threads_states_threads 、jvm_threads_live_threads 等,Grafana会给你较好的提示,并且可以用PromQL实现较为复杂的计算,例如聚合、求和、平均等。如果想要绘制多个线条,可点击Add Query 按钮,
- 再点击下面那个
Visualization,可以选择可视化的类型和一些相关的配置。这里就不多赘述,留给读者自己探索。
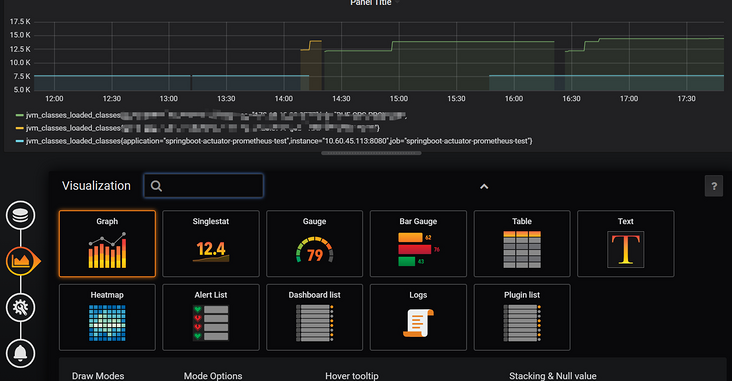
- 再点击下一步
General进行基础配置,不赘述:
5. Dashboard 市场
到这里,我想聪明的读者们应该已经学会如何去可视化一个指标数据了。但是应该很多人都会觉得,如果有好多指标的话,配置起来实际上是蛮繁琐的。
是否有开箱即用、通用型的DashBoard模板呢?
前往 Grafana Lab - Dashboards ,输入关键词即可搜索指定Dashboard。你就可以获得你想要的。
另外,这些已有的dashboard也可以让我们更快掌握一些panel的配置和dashboard的使用。

6. 引入dashboard
这里直接给出两款我觉得比较好用的dashboard:
- JVM (Micrometer)
- Spring Boot Statistics
这一款我需要提一下,刚开始我引入的时候是无效的,不知道读者会不会遇到和我一样的问题,如果遇到了,请到dashboard的设置里面,修改 variables 中
$application和$instance两个变量的Definition。
还有我个人是推荐,在这两款dashboard上面做一些定制化操作,或者说把两者的panel结合起来。
- 引入的操作很简单,首选你要在 Grafana Lab - Dashboards中选好你心仪的dashboard,然后记下它的ID
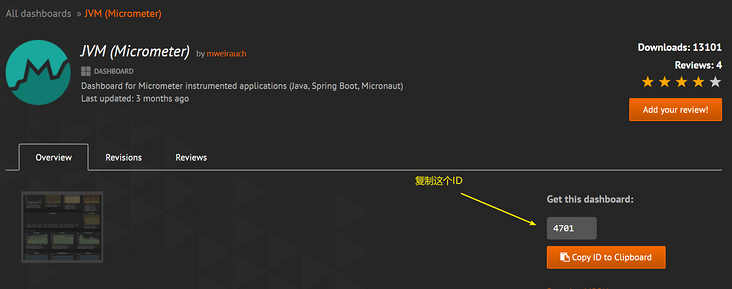
- 就是点击
Import按钮:
- 输入ID 之后,完成配置,点击
Import按钮:
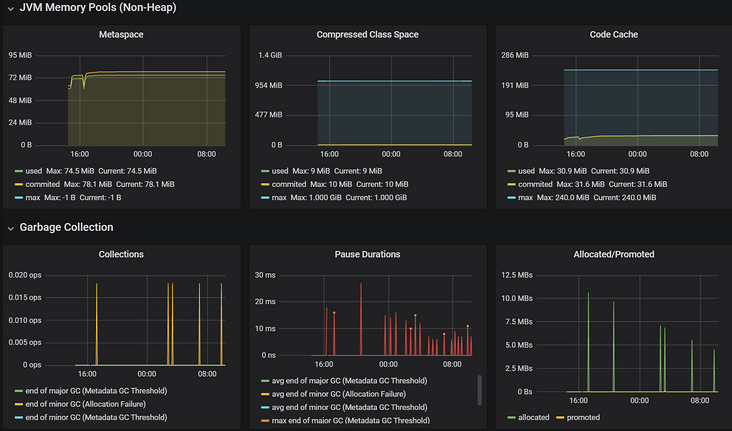
- 效果如下:
三、添加Alertmanager监控告警
AlertManager:用来接收prometheus发送来的报警信息,并且执行设置好的报警方式、报警内容。
下载镜像
[root@pro-gra-alt jws]# docker pull alertmanager #下载alertmanager镜像
基于alertmanager运行一台容器
[root@pro-gra-alt jws]# docker run -d --name alertmanager -p 9093:9093 prom/alertmanager:latest
配置路由转发
[root@pro-gra-alt jws]# echo net.ipv4.ip_forward = 1 >> /etc/sysctl.conf [root@pro-gra-alt jws]# sysctl -p
在部署alertmanager之前,我们需要对它的配置文件进行修改,所以我们先运行一个容器,先将其配置文件拷贝出来。
[root@pro-gra-alt jws]# docker cp alertmanager:/etc/alertmanager/alertmanager.yml ./ #拷贝alertmanager的配置文件到本地
修改alertmanager的配置文件
配置文件简单介绍
AlertManager:用来接收Prometheus发送的报警信息,并且执行设置好的报警方式,报警内容。 AlertManager.yml配置文件: global:全局配置,包括报警解决后的超时时间、SMTP相关配置、各种渠道通知的API地址等消息。 route:用来设置报警的分发策略。 receivers:配置报警信息接收者信息。 inhibit_rules:抑制规则配置,当存在与另一个匹配的报警时,抑制规则将禁用用于有匹配的警报。
修改配置文件
[root@jws-ftp jws]# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:465' #使用的是哪个邮箱,比如163或者QQ+端口
smtp_from: '123456@qq.com' #自己邮箱地址
smtp_auth_username: '123456@qq.com.com'
smtp_auth_password: '123456' #邮箱密码
smtp_require_tls: false
smtp_hello: '163.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '{{ template "email.to" . }}'
html: '{{ template "email.to.html" . }}'
send_resolved: true
[root@jws-ftp jws]#
以上配置我反复试验后,发现不同的环境参数配置也不一样,调试期间出现了各种报错问题,将其中几个关键的配置说明一下:
1.smtp_smarthost: 这里为 QQ 邮箱 SMTP 服务地址,官方地址为 smtp.qq.com 端口为 465 或 587,同时要设置开启 POP3/SMTP 服务。 smtp_auth_password: 这里为第三方登录 QQ 邮箱的授权码,非 QQ 账户登录密码,否则会报错,获取方式在 QQ 邮箱服务端设置开启 POP3/SMTP 服务时会提示。 3.smtp_require_tls: 是否使用 tls,根据环境不同,来选择开启和关闭。如果提示报错 email.loginAuth failed: 530 Must issue a STARTTLS command first,那么就需要设置为 true。着重说明一下,如果开启了 tls,提示报错 starttls failed: x509: certificate signed by unknown authority,需要在 email_configs 下配置 insecure_skip_verify: true 来跳过 tls 验证。
重新运行 alertmanager 容器
[root@jws-ftp jws]# docker rm -f alertmanager #删除alertmanager容器 [root@jws-ftp jws]# docker run -d --name alertmanager -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml -p 9093:9093 prom/alertmanager:latest #运行一台新的alertmanager容器,记得挂载配置文件
Prometheus配置和alertmanager报警规则
创建存放规则的目录
[root@docker01 ~]# mkdir -p prometheus/rules #创建规则目录 [root@docker01 ~]# cd prometheus/rules/
编写规则
[root@jws-ftp rules]# cat node-up.rules
groups:
- name: springboot-actuator-prometheus-test
rules:
- alert: springboot-actuator-prometheus-test
expr: up{job="springboot-actuator-prometheus-test"} == 0 ##{job="springboot-actuator-prometheus-test"}中的springboot-actuator-prometheus-test需要和prometheus配置文件23行的相同
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s!"
[root@jws-ftp rules]#
说明:该 rules 目的是监测 node 是否存活,expr 为 PromQL 表达式验证特定节点 job="node-exporter" 是否活着,for 表示报警状态为 Pending 后等待 15s 变成 Firing 状态,一旦变成 Firing 状态则将报警发送到 AlertManager,labels 和 annotations 对该 alert 添加更多的标识说明信息,所有添加的标签注解信息,以及 prometheus.yml 中该 job 已添加 label 都会自动添加到邮件内容中,更多关于 rule 详细配置可以参考 这里。
修改 prometheus配置文件
[root@jws-ftp prometheus]# cat prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: 'springboot-actuator-prometheus-test'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['10.153.49.7:8080']
labels:
instance: springboot-actuator-prometheus-test
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.153.61.49:9093
rule_files:
- "/usr/local/prometheus/rules/*.rules" #添加(这个路径是prometheus容器内的路径)
[root@jws-ftp prometheus]#
注意: 这里 rulefiles 为容器内路径,需要将本地 node-up.rules 文件挂载到容器内指定路径,修改 Prometheus 启动命令如下,并重启服务。
重新运行prometheus 容器
[root@jws-ftp rules]# docker rm -f prometheus #删除prometheus容器 [root@jws-ftp rules]# docker run -d -p 9090:9090 --name prometheus --net=host -v /root/prometheus.yml:/etc/prometheus/prometheus.yml -v /root/prometheus/rules/node-up.rules:/usr/local/prometheus/rules/node-up.rules prom/prometheus #运行一台新的alertmanager容器,记得挂载规则文件
浏览器验证一下http://10.153.61.49:9090/rules
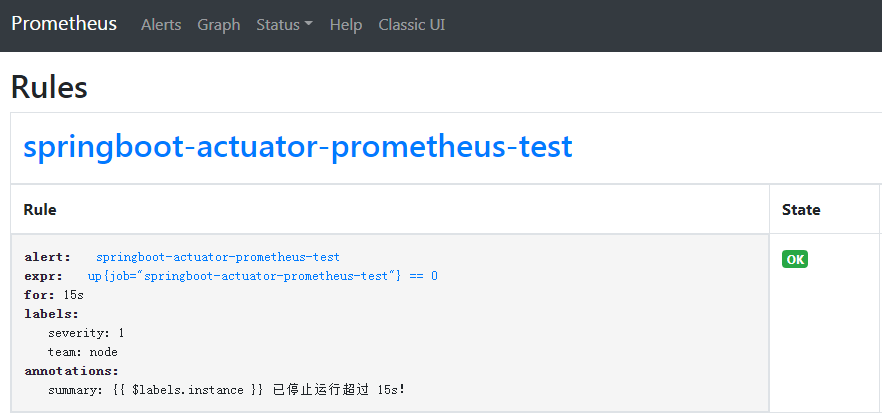
这里说明一下 Prometheus Alert 告警状态有三种状态:Inactive、Pending、Firing。
Inactive:非活动状态,表示正在监控,但是还未有任何警报触发。 Pending:表示这个警报必须被触发。由于警报可以被分组、压抑/抑制或静默/静音,所以等待验证,一旦所有的验证都通过,则将转到 Firing 状态。 Firing:将警报发送到 AlertManager,它将按照配置将警报的发送给所有接收者。一旦警报解除,则将状态转到 Inactive,如此循环。
停止微服务后,会收到告警邮件
这里有几个地方需要解释一下:
每次停止/恢复服务后,15s 之后才会发现 Alert 状态变化,是因为 prometheus.yml中 global -> scrape_interval: 15s 配置决定的,如果觉得等待 15s 时间太长,可以修改小一些,可以全局修改,也可以局部修改。例如局部修改 node-exporter 等待时间为 5s。 ... - job_name: 'node-exporter' scrape_interval: 5s file_sd_configs: - files: ['/usr/local/prometheus/groups/nodegroups/*.json'] Alert 状态变化时会等待 15s 才发生改变,是因为 node-up.rules 中配置了 for: 15s 状态变化等待时间。 报警触发后,每隔 5m 会自动发送报警邮件(服务未恢复正常期间),是因为 alertmanager.yml 中 route -> repeat_interval: 5m 配置决定的。
AlertManager自定义邮件模板
创建模板目录
[root@pro-gra-alt ~]# mkdir /jws/alertmanager/alertmanager-tmpl #创建AlertManager模板目录 [root@pro-gra-alt ~]# cd /jws/alertmanager/alertmanager-tmpl #进入模板目录
看到上边默认发送的邮件模板,虽然所有核心的信息已经包含了,但是邮件格式内容可以更优雅直观一些,那么,AlertManager 也是支持自定义邮件模板配置的,首先新建一个模板文件
编写模板规则
[root@pro-gra-alt alertmanager-tmpl]# cat email.tmpl
{{ define "email.from" }}123456@qq.com{{ end }}
{{ define "email.to" }}123456@qq.com, abc.163.com{{ end }} #多个收件人用逗号隔开
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
[root@pro-gra-alt alertmanager-tmpl]#
简单说明一下,上边模板文件配置了 email.from、email.to、email.to.html 三种模板变量,可以在 alertmanager.yml 文件中直接配置引用。这里 email.to.html 就是要发送的邮件内容,支持 Html 和 Text 格式,这里为了显示好看,采用 Html 格式简单显示信息。下边 {{ range .Alerts }} 是个循环语法,用于循环获取匹配的 Alerts 的信息,下边的告警信息跟上边默认邮件显示信息一样,只是提取了部分核心值来展示。
触发时间 ,配置文件解释
(.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" 这里定义的时间为go 语言的诞生时间!!!切记不能乱填,Add 28800e9 是增加8个小时,系统默认为UTC实际因此增加8小时变为CST时间
另外alertmanager 是由go 语言开发的,所以他要遵循这个时间。如果随意填写时间,出现的告警时间是错的
然后,需要增加 alertmanager.yml 文件 templates 配置如下:
修改alertmanager的配置文件
[root@pro-gra-alt alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '123456@qq.com'
smtp_auth_username: '123456@qq.com'
smtp_auth_password: '123456'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates: #添加模板
- '/etc/alertmanager-tmpl/email.tmpl' #添加路径
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '{{ template "email.to" . }}'
html: '{{ template "email.to.html" . }}'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
[root@pro-gra-alt alertmanager]#
重新运行 alertmanager 容器
[root@docker01 ~]# docker stop alertmanager && docker rm alertmanager #删除alertmanager容器 [root@docker01 ~]# docker run -d --name alertmanager -v /jws/alertmanager/alertmanager-tmpl/:/etc/alertmanager-tmpl/ -v /jws/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml -p 9093:9093 prom/alertmanager:latest #运行一台新的alertmanager容器,记得挂载配置文件
注:
prometheus和ELK关于spring boot需要添加修改的依赖和配置汇总:
1、需要的依赖包: ///Prometheus需要的依赖包 <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> ///logshash需要的依赖包 <dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>5.1</version> </dependency>
2、application.properties 配置修改 Prometheus的配置 management.endpoints.web.exposure.include=* logshash的配置 logging.config = classpath:logback-spring.xml 3、logshash在resource下添加logback-spring.xml,IP修改为logstash服务端IP地址 <?xml version="1.0" encoding="UTF-8"?> <configuration> <include resource="org/springframework/boot/logging/logback/base.xml" /> <appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <destination>10.10.10.10:9061</destination> <encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder" /> </appender> <root level="INFO"> <appender-ref ref="LOGSTASH" /> <appender-ref ref="CONSOLE" /> </root> </configuration>
可参考资料(侵删):
https://ricstudio.top/archives/spring_boot_actuator_learn
https://ricstudio.top/archives/monitorintegrateprometheusgrafana
https://www.cnblogs.com/zqj-blog/p/12205063.html
https://blog.51cto.com/u_14320361/2461666
prometheus触发alertmanger的webhook:https://blog.csdn.net/DY1316434466/article/details/107786068