磁盘:
当内核运行起来之后就会接管所有的硬件,任何程序都不得直接与硬件进行通信,都要通过内核才可以。那么内核是为什么可以接管所有的硬件?因为内核当中有各个硬件的驱动程序,这些程序集成在内核当中,其目的就是为了接管硬件,这些驱动都是市面上常见的,相对来讲比较老旧的。比如我们买了一个最新的硬盘,但是内核当中并没有此品牌类型的驱动程序的话,那么内核便不能使用此硬盘,所以当我们在一个硬盘装系统的时候发现内核并不能使用此硬盘的话,除去物理原因很有可能就是驱动原因,那么解决的办法就是先加载驱动到内核当中,然后内核再使用驱动来装入。
每一种的硬件因为其物理特性的不同,硬件在linux上有不同的数据标识,比如用2来标识硬件,用3来标识显卡等等,但是如果有多个同样的物理设备呢?所以就有了主次设备号,第一个硬件用2标识,那么第二个硬盘就有可能用2.2来标识,第一个2就是主设备号(major),那么第二个设备号就是次设备号(minor number)。
linux是一切皆文件,每一个硬件也是在linux上映射成一个文件,那么这个文件是关联到哪里去了呢?实际上这个文件是关联到了内核当中的对应着设备的驱动之上了,进而能够与硬件设备进行通信。
这里我们重点讲一下硬盘,盘片上有多个嵌套的圆,最外侧的圆就是0磁道(track),不断向内增加,靠外侧的磁道一般都分配给活动分区使用,因为在单位的时间内被磁头读取的数据最多,最流畅,;有的硬盘有多个盘片,而每个盘片上都有相同的磁道,不同的盘片上的相同的编号的磁道就是柱面(cylinder):第个磁道又有扇开的区域又叫做扇区(secotr),每一个扇区能存储512个位。当我们分区的时候其实就是对柱面进行分区的,每个柱面只能属于一个分区。
硬盘的工作效率受到多方面的影响,其主要的是还是其转速与接口的影响,第分钟可以转的圈数,主流的7200转,工作级别15000转/分钟。硬盘的接口主要是分为二种(除固态):并口与串口,串口是比较快,因为是为时间频率的,提到时钟频率又不得不提一下(同步与异步)。
0磁道的0扇区:
0磁道就是最外侧的磁道。0磁道的第一个扇区就是存放着主引导记录,正好占满512位。
这512个位存放的是主引导记录(master boot record),其中446位是存放引导加载器(boot loader),还有64位是存在分区表,第个分区表占用16位,所以只能记录4个主分区嘛!还有2位是标识此引导记录的有效性。
说白了分区就是在分区表中写入分区所对应的起始与结束柱面而已,并没有对磁盘做物理上的划分,如图:

磁盘为什么要分区?
- 有了分区重装系统之后只会重装系统所有的分区,其余分区的数据不丢失。
- 提高性能
一般分区是都是三个主分区+一个扩展分区,然后在扩展分区里面再划分多个逻辑分区,其实扩展分区也是一段空间,不过这段空间不能存在真正的数据,而是存放的是在其身上的分区的地址。写到这里,想起了之前学过的软链接,软链接文件里面存储也是路径地址。
分区格式化和swap意义?
格式化为了实现数据能够结构化管理。当我们把一个硬盘进行分区完之后就要在里面打格子了,打格子的过程就是格式化,所以格式化的目的并不是删除文件,而是给分区打格子。常见的打格子的方式有:ntfs、ext2、ext4、fat32,那么不同的类型打格子的方式意味着什么呢?意味着数据在分区上的排列方式不同。就像一张白纸可以打成方格、田字格、横线等类型。
swap是交换分区,当我们在安装系统的时候最好要进行分区的。它相当于内存的外延,当内存的压力过大时帮助内存分担压力的。那么swap到底要分多大呢?这是视情况而定的,对于要求内存的要求大的服务比如mysql、sqlserver这类数据要快速在内存进行交替反而swap应该要小一些,为什么呢?数据中的数据在内存当中是以页框存在的,当内存中的压力过大的时候,就需要把一些闲置应用的分页调用到swap分区,用的时候再调用到内存当中,但是swap是存在于硬盘上的,硬盘是机械的,它的速度远远跟不上内存,调用速度就会很慢,但是这类应用的要求的就是速度,所以要把交换分区划分的小一些2G足矣,大了性能反而会下降。但是如果主机上跑的就是批处理类的、不是关键类的、对内存性能要求低但是对于内存的量要求很大的,可以把交换分区调的大一些,甚至可以把大部分硬盘都划分给swap分区,像用于科学计算的批处理主机。总之一句话交换分区的大小视情况而定的,并不是越大越好。
文件系统:日志型与非日志型
总的来说,所有的文件系统分为日志型与非日志型。
什么是日志型与非日志型呢?它的作用是什么呢?非日志与日志型文件系统又有什么不同呢?想要搞清楚这件事我们要从一个例子来讲起:
有一天,我有迅雷下载一个将近2G的电影时,我刚把种子添加到迅雷的下载区域,点击下载之后立马报错“空间不足”,我去我的电脑看了一下我的分区的确是没有多少空间了,但是还有1G的空间。
那么我们从这个事情能体会到什么?当一个文件要计算机创建的时候首先计算空间判断这个文件能不能在你的磁盘上存下,也就是说当一个文件创建的时候要先创建其元数据信息,如果判断空间充足,才能继续下载。如果下载了一半的时候突然断电了,当重新开机时是要进行修复的,那么这个修复的过程是怎样的?其实这个修复就是内核去扫描磁盘上的元数据,根据元数据中记录的数据块地址,查看这些数据块是不是完整的,如果是完整的说明文件没有事,如果文件不是完整的,说明文件有损,能修好就修好,修不好拉倒,这就是非日志型文件系统的工作方式。
而日志型的文件系统比非日志的文件系统要高级,日志型的文件系统除了真正的数据部分、元数据部分还有一个区域这个区域被称为“日志区域”,当我们向磁盘写入一个文件的时候,首先在日志区域创建元数据,当这个文件完整顺利的写入到磁盘上之后再把日志上记录的元数据导入到真正的元数据区域。那么这样做有什么好处呢?当向磁盘写入一个文件的时候如果这个文件没有写完就断电了,当系统重新开机的时候就不去扫描真正的元数据区域而是去扫描日志区域,根据日志区域内记录的元数据记录的数据块地址检察数据是否完整,能恢复的就恢复,不能恢复就拉倒。直接扫描日志区域是可以加快系统修复的时候的,因为日志区域存储的元数据总是要比真正的元数据区域要少很多。
文件系统的位数:
其实不同的文件系统有不的位数,这个位数其实就是单个文件所能够寻找的磁盘块,位数越大单个文件的寻址能力就越强,单个文件的容量就越大,像最新的btrfs文件系统支持64位,其实就相当于无上限了(2的64次方,约等于无限),像早期的fat文件系统其实就是因为其位数小的原因所以单个文件最大不能超过2G。
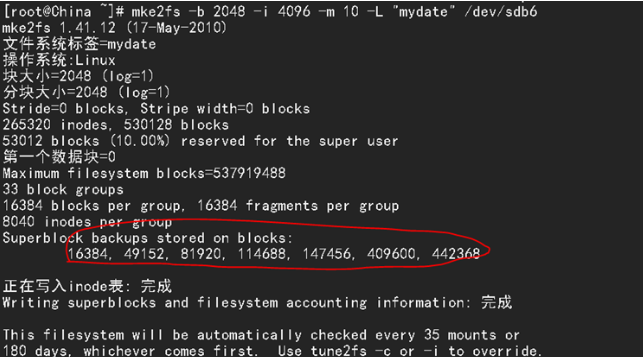
超级块:
当一个分区格式化成文件系统的时候,文件系统会评估此分区有多少个块,然后平均把所有的块分成一个又一个有块组,每个块组有同样多的块,这样做的目的是为了方便管理,而记录这个分区块组的信息(多少到多少块是一个组,组多大,占用和剩余空间)的块就叫做超级块,因为超级块里面存储的是整个分区的结构化信息,所以它不容有失,一个分区只有一个超级块正在使用,超级块有许多的备份,在我们格式化分区的时候为提醒我们超级块备份到了哪些块当中,如下图当中圈起来的块就是超级块所在的地址。
如果说一个分区相当于一个“连队”,那么超级块就是连队里面班长。