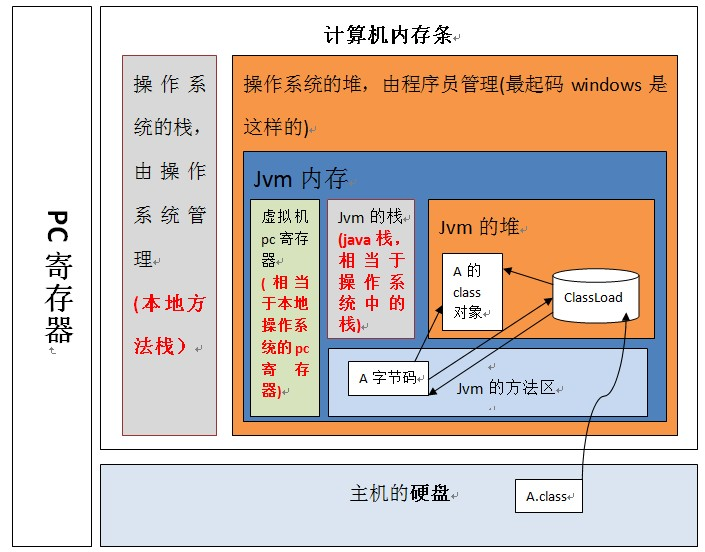
上图表明:jvm虚拟机位于操作系统的堆中,并且,程序员写好的类加载到虚拟机执行的过程是:当一个classLoder启动的时候,classLoader的生存地点在jvm中的堆,然后它会去主机硬盘上将A.class装载到jvm的方法区,方法区中的这个字节文件会被虚拟机拿来new A字节码(),然后在堆内存生成了一个A字节码的对象,然后A字节码这个内存文件有两个引用一个指向A的class对象,一个指向加载自己的classLoader
双亲委派机制:JVM在加载类时默认采用的是双亲委派机制。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
见下图:

例如:当jvm要加载Test.class的时候,
(1)首先会到自定义加载器中查找(其实是看运行时数据区的方法区有没有加载),看是否已经加载过,如果已经加载过,则返回字节码。
(2)如果自定义加载器没有加载过,则询问上一层加载器(即AppClassLoader)是否已经加载过Test.class。
(3)如果没有加载过,则询问上一层加载器(ExtClassLoader)是否已经加载过。
(4)如果没有加载过,则继续询问上一层加载(BoopStrap ClassLoader)是否已经加载过。
(5)如果BoopStrap ClassLoader依然没有加载过,则到自己指定类加载路径下("sun.boot.class.path")查看是否有Test.class字节码,有则返回,没有通
知下一层加载器ExtClassLoader到自己指定的类加载路径下(java.ext.dirs)查看。
(6)依次类推,最后到自定义类加载器指定的路径还没有找到Test.class字节码,则抛出异常ClassNotFoundException。
为什么要使用这种加载方式呢?这里要注意几点,1,类加载器代码本身也是java类,因此类加载器本身也是要被加载的,因此显然必须有第一个类加载器不是Java类,这就是bootStrap,是使用c++写的其他这是java了。2,虽说bootStrap、extclassLoader、appclassloader三个是父子类加载器关系,但是并没有使用继承,而是使用了组合关系。3,优点,具备了一种带优先级的层次关系,越是基础的类,越是被上层的类加载器进行加载,可以比较笼统的说像jdk自带的几个jar包肯定是位于最顶级的,再就是我们引用的包,最后是我们自己写的,保证了java程序的稳定性。
1.对象的创建过程:
1.new 类名
2.根据new的参数在常量池中定位一个类的符号的引用。
3.如果没找到这个符号的引用,说明类还没有被加载。则进行类的加载,解析和初始化
4.虚拟机为对象分配内存(位于堆中)。
5.将分配的内存初始化为零(不包括对象头),即抽象属性初始化为null,基本数据类型初始化为0.
、 6.调用对象的<init>方法
2.给对象分配内存的方式:
1.指针碰撞。这种方式前提是堆内存规整的并不是杂乱的,比如,将堆内存分为两块,一块是未使用的,一块是已经使用的。堆内存中未使用和已使用的交错存放则是不规整得 。
2.空闲列表。这种方式适用于堆内存不规整的。原理:虚拟机必须维护一张列表,这张列表记录堆中哪些内存块可用,哪些不可用。当分配内存中,就从这表中找出一块可用的内存
区域给新对象。再更新这张表。
内存的分配方式是有java中的堆是否规整来决定。而堆的规整是由垃圾回收策略来决定的。如果垃圾回收的过程中如果堆内存的 压缩整理,则应该使用指针碰撞
方式,反之则使用空闲列表。
3.在遇到高并发的情况下,给对象分配内存还会带来线程安全性问题。比如,一个线程进来给对象分配内存,在高并发的情况下,另外又有一个线程进来了,第一个线程还没来的及更新内存分配。而另外一个
线程刚好又申请了这块内存。这就导致了线程不安全问题。
解决方式:
1.线程同步。一个线程进来加一把锁,知道这个线程释放这把锁后,其他线程才能进来。这种方式也不失为一个解决办法。但是这种方式效率慢。
2.本地线程分配缓冲(TLAB)。做法就是为每一个线程分配一块单独的内存区域。这样就解决了线程不安全问题。而且效率大大提高。如果单独的内存区域满了后,我们还可以
继续利用线程同步再分配一块单独的内存区域给每一个线程。
对象的内存布局
3.对象的结构有:
1.Header(对象头),其组成主要有两部分:
1.自身运行时的数据(Mark Word),包括:
1.哈希值
2.GC分代年龄。
3.锁状态标志
4。线程所持有的锁
5.偏向线程ID
6.偏向时间戳
自身运行时的数据(Mark Word)说占多少多内存呢?其实是根据32位,64位的虚拟机而定的。但是它包含的数据远远超过其本身内存。
那它是如何做到将这些数据存储的 呢?先看下图:
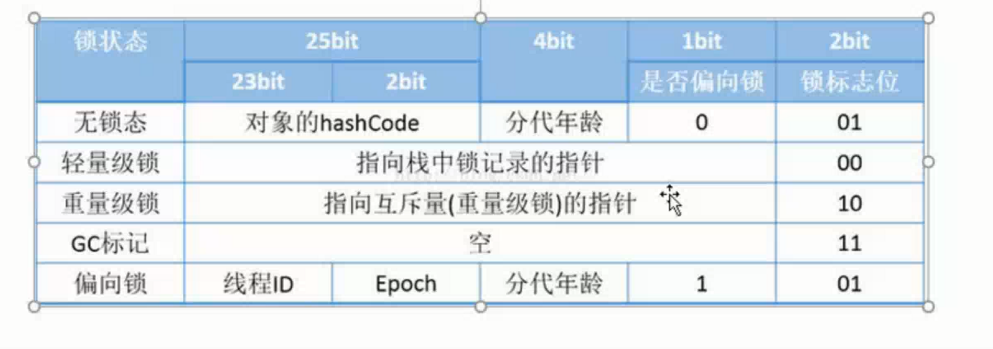
很明显它是通过内存复用来实现。
2.类型指针。就是对象指向它的类的元数据的指针。虚拟机通过这个指针来确定这个对象是哪个类的实例。注意并不是所有的虚拟机的实现都保留类型指针。
2.InstanceData(数据实例):这部分是真正存储对象的有效信息,也是我们接触到的,看到的最多的地方。不管是从父类继承下来的,还是子类定义的,都要记录下来。
这部分存储的顺序会收到虚拟机的分配策略和字段在java源码中的顺序的影响。HotSpot虚拟机所默认的 分配策略是相同宽度的字段被分配到一起。
3.Padding(填充):它仅仅相当于占位符。这部分并不是必然存在的,也没有特别的含义,它仅仅相当于占位符。那为什么需要占位符呢?主要是因为HotSpot虚拟机的自动内存管理系统要求
对象起始地址必须是8个字节的整数倍,也就是说对象的大小必须是八个字节的整数倍,而对象头部分刚好是8个字节的整数倍,而InstanceData如果没有八个字节的整数倍,则要通过填充来
使它达到。
4.指针与引用(指针的指针)
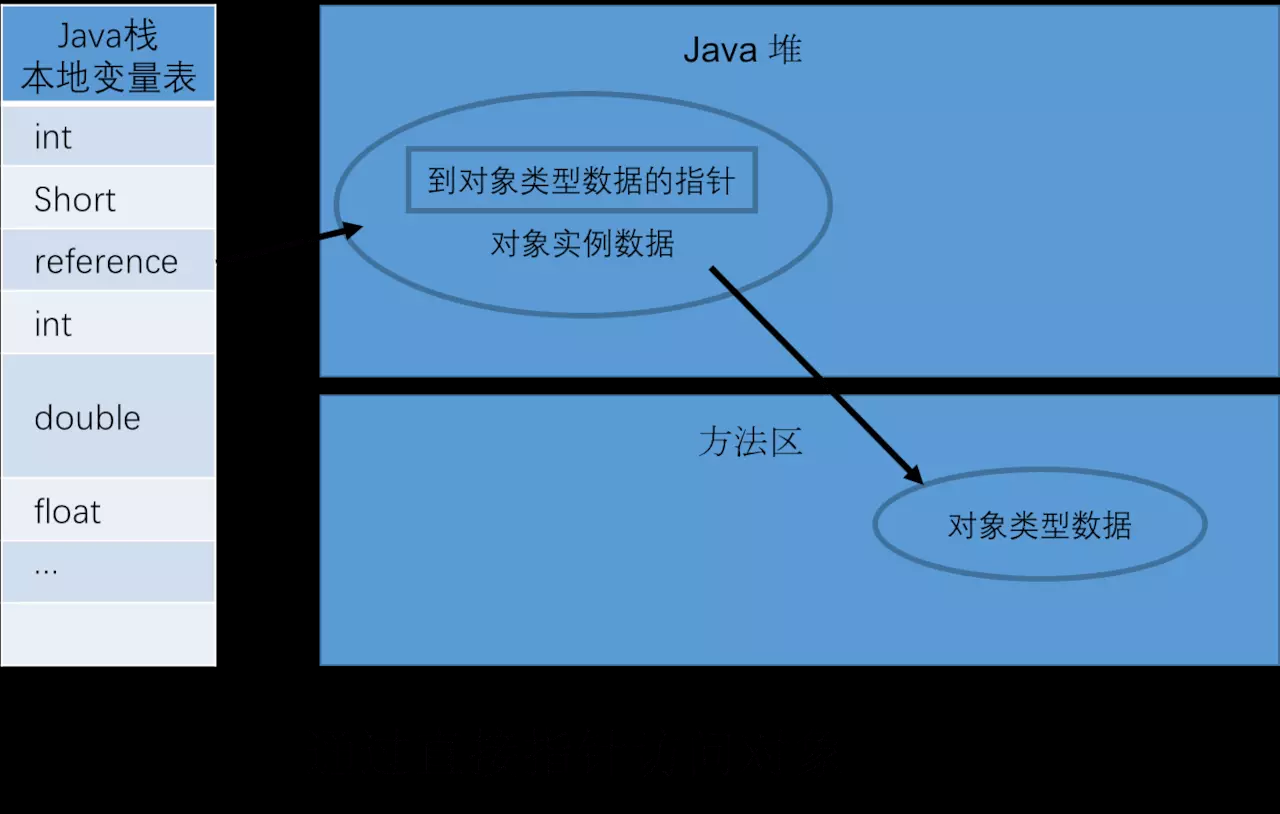
比较:使用句柄的最大好处是 reference 中存储的是稳定的句柄地址,在对象移动(GC)是只改变实例数据指针地址,reference 自身不需要修改。直接指针访问的最大好处是速度快,节省了一次指针定位的时间开销。如果是对象频繁 GC 那么句柄方法好,如果是对象频繁访问则直接指针访问好。
参考:https://blog.csdn.net/qq_41701956/article/details/81664921
参考 :https://blog.csdn.net/csdnliuxin123524/article/details/81303711