将开发的程序打包到正式环境中运行实战篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.编写spark的wordcount案例
1>.创建一个maven项目并导入依赖


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.yinzhengjie.bigdata</groupId> <artifactId>spark</artifactId> <version>1.0</version> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.1.1</version> </dependency> </dependencies> <build> <finalName>WordCount</finalName> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <!--打包插件--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <archive> <manifest> <mainClass>WordCount</mainClass> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
2>.编写WordCount案例
package com.yinzhengjie.bigdata.spark import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { /** * 命令行完成WordCount案例: * sc.textFile("/tmp/data/").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect * * 下面是使用开发工具完成Spark WordCount的开发(需要安装Scala环境) */ //创建SparkConf对象 val config:SparkConf = new SparkConf() config.setMaster("local[*]") config.setAppName("WordCount") //创建Spark上下文对象 val sc = new SparkContext(config) /** * 读取文件,将文件内容一行一行读取出来 * * 需要注意的是,路径查找位置默认从当前的部署环境中查找,如果需要从本地查找:"file:///tmp/data/" * */ val lines = sc.textFile(args(0)) //将每行数据按照空格(" ")切割成多个单词 val words:RDD[String] = lines.flatMap(_.split(" ")) //为了统计方便,将单词数据进行结构的转换 val wordToOne:RDD[(String,Int)] = words.map((_,1)) //将转换结构后的数据进行分组聚合 val wordToSum:RDD[(String,Int)] = wordToOne.reduceByKey(_+_) //将统计结果采集后打印到控制台 val result:Array[(String,Int)] = wordToSum.collect() result.foreach(println) //关闭连接 sc.stop() } }
二.使用idea工具将开发的程序打包
1>.使用idea工具开始打包

2>.打包完成会生成相应的jar包文件(建议选择有依赖的jar包上传到服务器)

三.将开发的程序打包到正式环境中运行实战案例
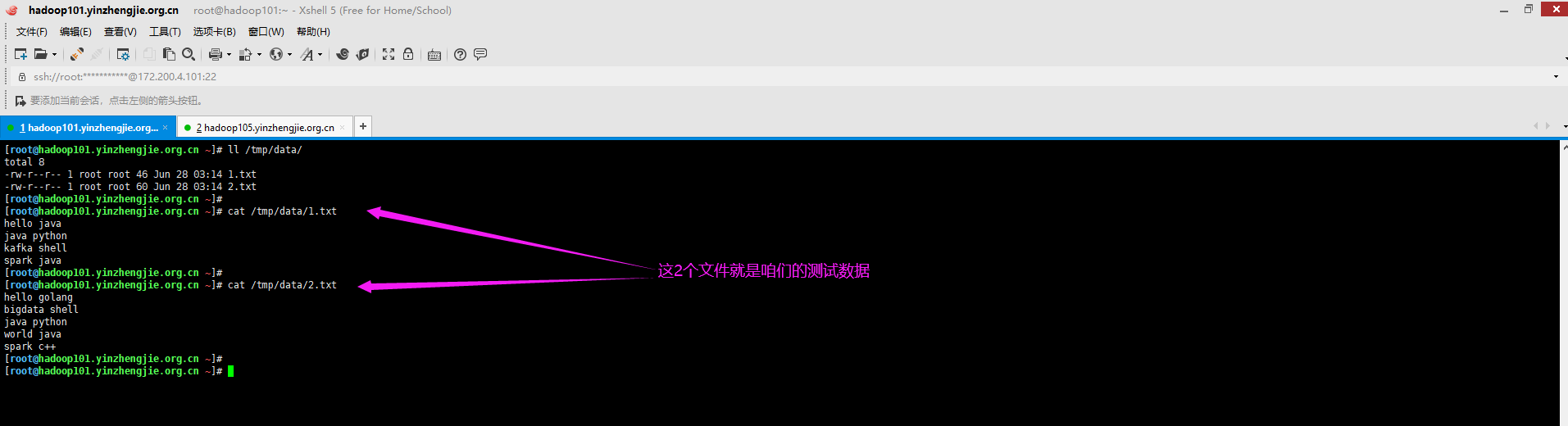
1>.准备数据源
[root@hadoop101.yinzhengjie.org.cn ~]# ll /tmp/data/ total 8 -rw-r--r-- 1 root root 46 Jun 28 03:14 1.txt -rw-r--r-- 1 root root 60 Jun 28 03:14 2.txt [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# cat /tmp/data/1.txt hello java java python kafka shell spark java [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# cat /tmp/data/2.txt hello golang bigdata shell java python world java spark c++ [root@hadoop101.yinzhengjie.org.cn ~]#
2>.启动zookeeper集群
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8239 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8745 Jps hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9677 Jps hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6486 Jps hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8208 Jps hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6730 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# zookeeper.sh start 启动服务 ========== zookeeper101.yinzhengjie.org.cn zkServer.sh start ================ /yinzhengjie/softwares/jdk1.8.0_201/bin/java ZooKeeper JMX enabled by default Using config: /yinzhengjie/softwares/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ========== zookeeper102.yinzhengjie.org.cn zkServer.sh start ================ /yinzhengjie/softwares/jdk1.8.0_201/bin/java ZooKeeper JMX enabled by default Using config: /yinzhengjie/softwares/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ========== zookeeper103.yinzhengjie.org.cn zkServer.sh start ================ /yinzhengjie/softwares/jdk1.8.0_201/bin/java ZooKeeper JMX enabled by default Using config: /yinzhengjie/softwares/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 10992 QuorumPeerMain 11133 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9063 Jps hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8630 QuorumPeerMain 8716 Jps hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8754 Jps 8661 QuorumPeerMain hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6918 Jps hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 7296 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
3>.启动hdfs集群
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 10992 QuorumPeerMain 11133 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9063 Jps hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8630 QuorumPeerMain 8716 Jps hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8754 Jps 8661 QuorumPeerMain hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6918 Jps hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 7296 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# start-dfs.sh Starting namenodes on [hadoop101.yinzhengjie.org.cn hadoop106.yinzhengjie.org.cn] hadoop106.yinzhengjie.org.cn: starting namenode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-namenode-hadoop106.yinzhengjie.org.cn.out hadoop101.yinzhengjie.org.cn: starting namenode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-namenode-hadoop101.yinzhengjie.org.cn.out hadoop102.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-datanode-hadoop102.yinzhengjie.org.cn.out hadoop104.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-datanode-hadoop104.yinzhengjie.org.cn.out hadoop105.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-datanode-hadoop105.yinzhengjie.org.cn.out hadoop106.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-datanode-hadoop106.yinzhengjie.org.cn.out hadoop101.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-datanode-hadoop101.yinzhengjie.org.cn.out hadoop103.yinzhengjie.org.cn: starting datanode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-datanode-hadoop103.yinzhengjie.org.cn.out Starting journal nodes [hadoop103.yinzhengjie.org.cn hadoop104.yinzhengjie.org.cn hadoop102.yinzhengjie.org.cn] hadoop103.yinzhengjie.org.cn: starting journalnode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-journalnode-hadoop103.yinzhengjie.org.cn.out hadoop104.yinzhengjie.org.cn: starting journalnode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-journalnode-hadoop104.yinzhengjie.org.cn.out hadoop102.yinzhengjie.org.cn: starting journalnode, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-journalnode-hadoop102.yinzhengjie.org.cn.out Starting ZK Failover Controllers on NN hosts [hadoop101.yinzhengjie.org.cn hadoop106.yinzhengjie.org.cn] hadoop101.yinzhengjie.org.cn: starting zkfc, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-zkfc-hadoop101.yinzhengjie.org.cn.out hadoop106.yinzhengjie.org.cn: starting zkfc, logging to /yinzhengjie/softwares/ha/logs/hadoop-root-zkfc-hadoop106.yinzhengjie.org.cn.out [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8630 QuorumPeerMain 8982 Jps 8760 DataNode 8861 JournalNode hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6962 DataNode 7063 JournalNode 7179 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9108 DataNode 9238 Jps hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8899 JournalNode 9011 Jps 8661 QuorumPeerMain 8798 DataNode hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 10992 QuorumPeerMain 11873 Jps 11273 NameNode 11390 DataNode 11710 DFSZKFailoverController hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 7568 DFSZKFailoverController 7685 Jps 7417 DataNode 7340 NameNode [root@hadoop101.yinzhengjie.org.cn ~]#
4>.启动yarn集群
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8630 QuorumPeerMain 8982 Jps 8760 DataNode 8861 JournalNode hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6962 DataNode 7063 JournalNode 7179 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9108 DataNode 9238 Jps hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8899 JournalNode 9011 Jps 8661 QuorumPeerMain 8798 DataNode hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 10992 QuorumPeerMain 11873 Jps 11273 NameNode 11390 DataNode 11710 DFSZKFailoverController hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 7568 DFSZKFailoverController 7685 Jps 7417 DataNode 7340 NameNode [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /yinzhengjie/softwares/ha/logs/yarn-root-resourcemanager-hadoop101.yinzhengjie.org.cn.out hadoop102.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/ha/logs/yarn-root-nodemanager-hadoop102.yinzhengjie.org.cn.out hadoop103.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/ha/logs/yarn-root-nodemanager-hadoop103.yinzhengjie.org.cn.out hadoop104.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/ha/logs/yarn-root-nodemanager-hadoop104.yinzhengjie.org.cn.out hadoop105.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/ha/logs/yarn-root-nodemanager-hadoop105.yinzhengjie.org.cn.out hadoop106.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/ha/logs/yarn-root-nodemanager-hadoop106.yinzhengjie.org.cn.out hadoop101.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/ha/logs/yarn-root-nodemanager-hadoop101.yinzhengjie.org.cn.out [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8899 JournalNode 9060 NodeManager 8661 QuorumPeerMain 9242 Jps 8798 DataNode hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8630 QuorumPeerMain 9031 NodeManager 8760 DataNode 9209 Jps 8861 JournalNode hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9108 DataNode 9286 NodeManager 9467 Jps hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6962 DataNode 7063 JournalNode 7228 NodeManager 7406 Jps hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 10992 QuorumPeerMain 12083 NodeManager 11959 ResourceManager 12519 Jps 11273 NameNode 11390 DataNode 11710 DFSZKFailoverController hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 7568 DFSZKFailoverController 7417 DataNode 7739 NodeManager 7340 NameNode 7917 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop105.yinzhengjie.org.cn ~]# jps 9108 DataNode 9286 NodeManager 9481 Jps [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /yinzhengjie/softwares/ha/logs/yarn-root-resourcemanager-hadoop105.yinzhengjie.org.cn.out [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# jps 9520 ResourceManager 9108 DataNode 9286 NodeManager 9582 Jps [root@hadoop105.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8899 JournalNode 9060 NodeManager 8661 QuorumPeerMain 9302 Jps 8798 DataNode hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9520 ResourceManager 9108 DataNode 9286 NodeManager 9647 Jps hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 10992 QuorumPeerMain 12083 NodeManager 11959 ResourceManager 11273 NameNode 12651 Jps 11390 DataNode 11710 DFSZKFailoverController hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6962 DataNode 7063 JournalNode 7465 Jps 7228 NodeManager hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9267 Jps 8630 QuorumPeerMain 9031 NodeManager 8760 DataNode 8861 JournalNode hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 7568 DFSZKFailoverController 7417 DataNode 7978 Jps 7739 NodeManager 7340 NameNode [root@hadoop101.yinzhengjie.org.cn ~]#
5>.将咱们打好的包上传到spark服务器
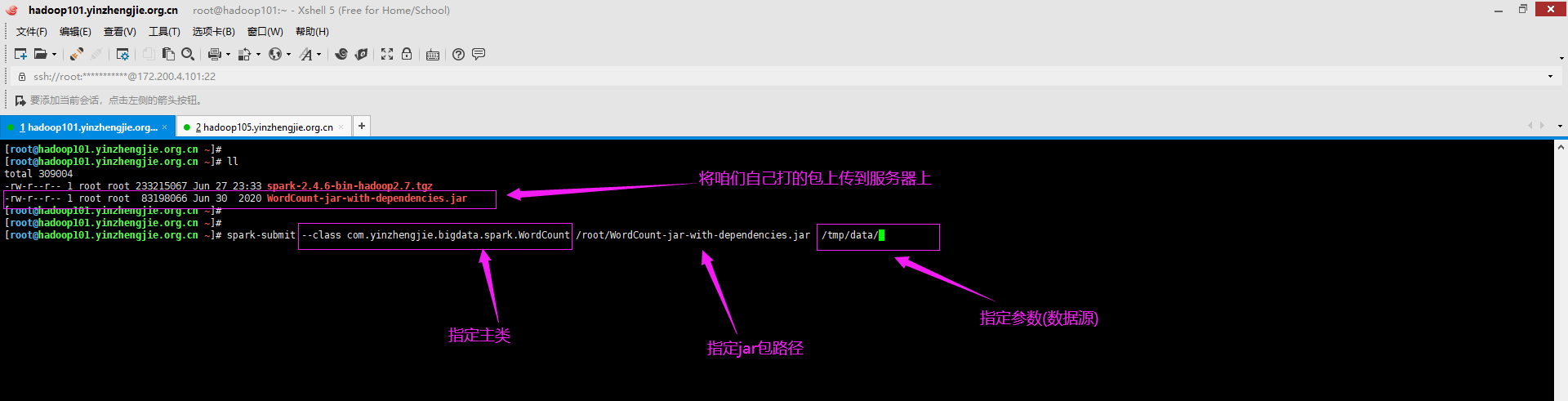
6>.将开发的程序打包到正式环境中运行
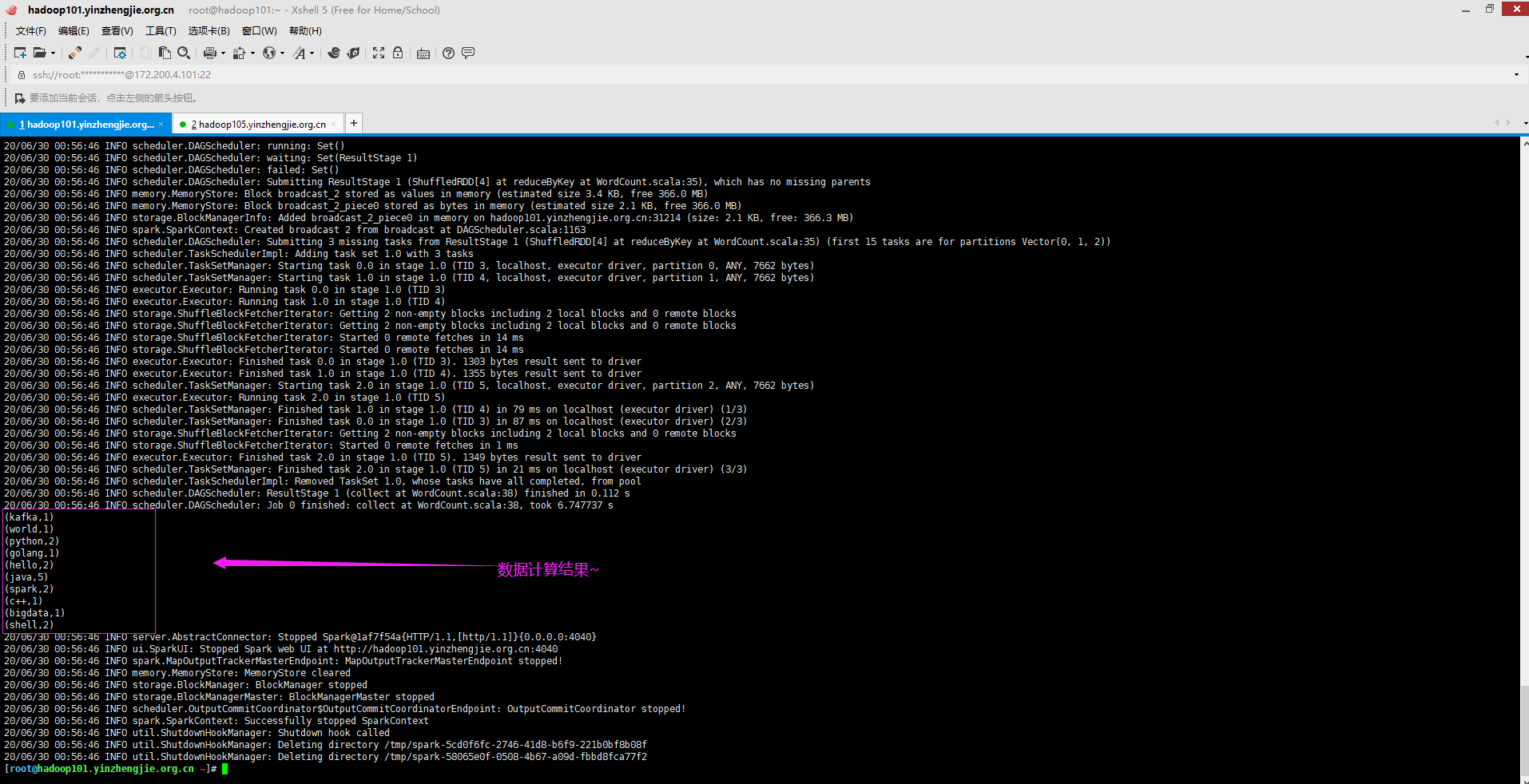
[root@hadoop101.yinzhengjie.org.cn ~]# spark-submit > --class com.yinzhengjie.bigdata.spark.WordCount > /root/WordCount-jar-with-dependencies.jar /tmp/data/ 20/06/30 00:56:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 20/06/30 00:56:31 INFO spark.SparkContext: Running Spark version 2.4.6 20/06/30 00:56:31 INFO spark.SparkContext: Submitted application: WordCount 20/06/30 00:56:31 INFO spark.SecurityManager: Changing view acls to: root 20/06/30 00:56:31 INFO spark.SecurityManager: Changing modify acls to: root 20/06/30 00:56:31 INFO spark.SecurityManager: Changing view acls groups to: 20/06/30 00:56:31 INFO spark.SecurityManager: Changing modify acls groups to: 20/06/30 00:56:31 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 20/06/30 00:56:33 INFO util.Utils: Successfully started service 'sparkDriver' on port 24176. 20/06/30 00:56:33 INFO spark.SparkEnv: Registering MapOutputTracker 20/06/30 00:56:33 INFO spark.SparkEnv: Registering BlockManagerMaster 20/06/30 00:56:33 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information 20/06/30 00:56:33 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up 20/06/30 00:56:33 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-45aae1f6-93c2-472a-8d9d-6090b0d784c7 20/06/30 00:56:33 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MB 20/06/30 00:56:33 INFO spark.SparkEnv: Registering OutputCommitCoordinator 20/06/30 00:56:33 INFO util.log: Logging initialized @8398ms 20/06/30 00:56:33 INFO server.Server: jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown 20/06/30 00:56:33 INFO server.Server: Started @8742ms 20/06/30 00:56:33 INFO server.AbstractConnector: Started ServerConnector@1af7f54a{HTTP/1.1,[http/1.1]}{0.0.0.0:4040} 20/06/30 00:56:33 INFO util.Utils: Successfully started service 'SparkUI' on port 4040. 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@12f3afb5{/jobs,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@79f227a9{/jobs/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6ca320ab{/jobs/job,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1e53135d{/jobs/job/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7674a051{/stages,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3a7704c{/stages/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6754ef00{/stages/stage,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@a23a01d{/stages/stage/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4acf72b6{/stages/pool,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7561db12{/stages/pool/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3301500b{/storage,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@24b52d3e{/storage/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@15deb1dc{/storage/rdd,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6e9c413e{/storage/rdd/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@57a4d5ee{/environment,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5af5def9{/environment/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3a45c42a{/executors,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@36dce7ed{/executors/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@47a64f7d{/executors/threadDump,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@33d05366{/executors/threadDump/json,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@27a0a5a2{/static,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1968a49c{/,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6a1ebcff{/api,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@13c612bd{/jobs/job/kill,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3ef41c66{/stages/stage/kill,null,AVAILABLE,@Spark} 20/06/30 00:56:33 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://hadoop101.yinzhengjie.org.cn:4040 20/06/30 00:56:33 INFO spark.SparkContext: Added JAR file:/root/WordCount-jar-with-dependencies.jar at spark://hadoop101.yinzhengjie.org.cn:24176/jars/WordCount-jar-with-dependencies.jar with timestamp 1593449793782 20/06/30 00:56:34 INFO executor.Executor: Starting executor ID driver on host localhost 20/06/30 00:56:34 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 31214. 20/06/30 00:56:34 INFO netty.NettyBlockTransferService: Server created on hadoop101.yinzhengjie.org.cn:31214 20/06/30 00:56:34 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 20/06/30 00:56:34 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, hadoop101.yinzhengjie.org.cn, 31214, None) 20/06/30 00:56:34 INFO storage.BlockManagerMasterEndpoint: Registering block manager hadoop101.yinzhengjie.org.cn:31214 with 366.3 MB RAM, BlockManagerId(driver, hadoop101.yinzhengjie.org.cn, 31214, None) 20/06/30 00:56:34 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, hadoop101.yinzhengjie.org.cn, 31214, None) 20/06/30 00:56:34 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, hadoop101.yinzhengjie.org.cn, 31214, None) 20/06/30 00:56:35 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2cfbeac4{/metrics/json,null,AVAILABLE,@Spark} 20/06/30 00:56:37 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 248.6 KB, free 366.1 MB) 20/06/30 00:56:37 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 24.1 KB, free 366.0 MB) 20/06/30 00:56:37 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop101.yinzhengjie.org.cn:31214 (size: 24.1 KB, free: 366.3 MB) 20/06/30 00:56:37 INFO spark.SparkContext: Created broadcast 0 from textFile at WordCount.scala:26 20/06/30 00:56:39 INFO mapred.FileInputFormat: Total input paths to process : 2 20/06/30 00:56:40 INFO spark.SparkContext: Starting job: collect at WordCount.scala:38 20/06/30 00:56:41 INFO scheduler.DAGScheduler: Registering RDD 3 (map at WordCount.scala:32) as input to shuffle 0 20/06/30 00:56:41 INFO scheduler.DAGScheduler: Got job 0 (collect at WordCount.scala:38) with 3 output partitions 20/06/30 00:56:41 INFO scheduler.DAGScheduler: Final stage: ResultStage 1 (collect at WordCount.scala:38) 20/06/30 00:56:41 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 0) 20/06/30 00:56:41 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 0) 20/06/30 00:56:41 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:32), which has no missing parents 20/06/30 00:56:41 INFO memory.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.1 KB, free 366.0 MB) 20/06/30 00:56:42 INFO memory.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 3.0 KB, free 366.0 MB) 20/06/30 00:56:42 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on hadoop101.yinzhengjie.org.cn:31214 (size: 3.0 KB, free: 366.3 MB) 20/06/30 00:56:42 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1163 20/06/30 00:56:42 INFO scheduler.DAGScheduler: Submitting 3 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:32) (first 15 tasks are for partitions Vector(0, 1, 2)) 20/06/30 00:56:42 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 3 tasks 20/06/30 00:56:42 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, ANY, 7890 bytes) 20/06/30 00:56:42 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, ANY, 7890 bytes) 20/06/30 00:56:42 INFO executor.Executor: Running task 1.0 in stage 0.0 (TID 1) 20/06/30 00:56:42 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0) 20/06/30 00:56:42 INFO executor.Executor: Fetching spark://hadoop101.yinzhengjie.org.cn:24176/jars/WordCount-jar-with-dependencies.jar with timestamp 1593449793782 20/06/30 00:56:42 INFO client.TransportClientFactory: Successfully created connection to hadoop101.yinzhengjie.org.cn/172.200.4.101:24176 after 262 ms (0 ms spent in bootstraps) 20/06/30 00:56:43 INFO util.Utils: Fetching spark://hadoop101.yinzhengjie.org.cn:24176/jars/WordCount-jar-with-dependencies.jar to /tmp/spark-5cd0f6fc-2746-41d8-b6f9-221b0bf8b08f/userFiles-c7c64040-87cf-485a-90ee-94ee5ade64c4/fetchFileTemp5481636741315186623.tmp 20/06/30 00:56:46 INFO executor.Executor: Adding file:/tmp/spark-5cd0f6fc-2746-41d8-b6f9-221b0bf8b08f/userFiles-c7c64040-87cf-485a-90ee-94ee5ade64c4/WordCount-jar-with-dependencies.jar to class loader 20/06/30 00:56:46 INFO rdd.HadoopRDD: Input split: hdfs://yinzhengjie-hdfs-ha/tmp/data/1.txt:0+46 20/06/30 00:56:46 INFO rdd.HadoopRDD: Input split: hdfs://yinzhengjie-hdfs-ha/tmp/data/2.txt:0+53 20/06/30 00:56:46 INFO executor.Executor: Finished task 1.0 in stage 0.0 (TID 1). 1214 bytes result sent to driver 20/06/30 00:56:46 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 1214 bytes result sent to driver 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, executor driver, partition 2, ANY, 7890 bytes) 20/06/30 00:56:46 INFO executor.Executor: Running task 2.0 in stage 0.0 (TID 2) 20/06/30 00:56:46 INFO rdd.HadoopRDD: Input split: hdfs://yinzhengjie-hdfs-ha/tmp/data/2.txt:53+7 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 4361 ms on localhost (executor driver) (1/3) 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 4429 ms on localhost (executor driver) (2/3) 20/06/30 00:56:46 INFO executor.Executor: Finished task 2.0 in stage 0.0 (TID 2). 999 bytes result sent to driver 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 48 ms on localhost (executor driver) (3/3) 20/06/30 00:56:46 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 20/06/30 00:56:46 INFO scheduler.DAGScheduler: ShuffleMapStage 0 (map at WordCount.scala:32) finished in 4.769 s 20/06/30 00:56:46 INFO scheduler.DAGScheduler: looking for newly runnable stages 20/06/30 00:56:46 INFO scheduler.DAGScheduler: running: Set() 20/06/30 00:56:46 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 1) 20/06/30 00:56:46 INFO scheduler.DAGScheduler: failed: Set() 20/06/30 00:56:46 INFO scheduler.DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:35), which has no missing parents 20/06/30 00:56:46 INFO memory.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 3.4 KB, free 366.0 MB) 20/06/30 00:56:46 INFO memory.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.1 KB, free 366.0 MB) 20/06/30 00:56:46 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on hadoop101.yinzhengjie.org.cn:31214 (size: 2.1 KB, free: 366.3 MB) 20/06/30 00:56:46 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1163 20/06/30 00:56:46 INFO scheduler.DAGScheduler: Submitting 3 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:35) (first 15 tasks are for partitions Vector(0, 1, 2)) 20/06/30 00:56:46 INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with 3 tasks 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 3, localhost, executor driver, partition 0, ANY, 7662 bytes) 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 1.0 (TID 4, localhost, executor driver, partition 1, ANY, 7662 bytes) 20/06/30 00:56:46 INFO executor.Executor: Running task 0.0 in stage 1.0 (TID 3) 20/06/30 00:56:46 INFO executor.Executor: Running task 1.0 in stage 1.0 (TID 4) 20/06/30 00:56:46 INFO storage.ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 2 local blocks and 0 remote blocks 20/06/30 00:56:46 INFO storage.ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 2 local blocks and 0 remote blocks 20/06/30 00:56:46 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 14 ms 20/06/30 00:56:46 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 14 ms 20/06/30 00:56:46 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 3). 1303 bytes result sent to driver 20/06/30 00:56:46 INFO executor.Executor: Finished task 1.0 in stage 1.0 (TID 4). 1355 bytes result sent to driver 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 1.0 (TID 5, localhost, executor driver, partition 2, ANY, 7662 bytes) 20/06/30 00:56:46 INFO executor.Executor: Running task 2.0 in stage 1.0 (TID 5) 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 1.0 (TID 4) in 79 ms on localhost (executor driver) (1/3) 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 3) in 87 ms on localhost (executor driver) (2/3) 20/06/30 00:56:46 INFO storage.ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 2 local blocks and 0 remote blocks 20/06/30 00:56:46 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 1 ms 20/06/30 00:56:46 INFO executor.Executor: Finished task 2.0 in stage 1.0 (TID 5). 1349 bytes result sent to driver 20/06/30 00:56:46 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 1.0 (TID 5) in 21 ms on localhost (executor driver) (3/3) 20/06/30 00:56:46 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 20/06/30 00:56:46 INFO scheduler.DAGScheduler: ResultStage 1 (collect at WordCount.scala:38) finished in 0.112 s 20/06/30 00:56:46 INFO scheduler.DAGScheduler: Job 0 finished: collect at WordCount.scala:38, took 6.747737 s (kafka,1) (world,1) (python,2) (golang,1) (hello,2) (java,5) (spark,2) (c++,1) (bigdata,1) (shell,2) 20/06/30 00:56:46 INFO server.AbstractConnector: Stopped Spark@1af7f54a{HTTP/1.1,[http/1.1]}{0.0.0.0:4040} 20/06/30 00:56:46 INFO ui.SparkUI: Stopped Spark web UI at http://hadoop101.yinzhengjie.org.cn:4040 20/06/30 00:56:46 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 20/06/30 00:56:46 INFO memory.MemoryStore: MemoryStore cleared 20/06/30 00:56:46 INFO storage.BlockManager: BlockManager stopped 20/06/30 00:56:46 INFO storage.BlockManagerMaster: BlockManagerMaster stopped 20/06/30 00:56:46 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 20/06/30 00:56:46 INFO spark.SparkContext: Successfully stopped SparkContext 20/06/30 00:56:46 INFO util.ShutdownHookManager: Shutdown hook called 20/06/30 00:56:46 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-5cd0f6fc-2746-41d8-b6f9-221b0bf8b08f 20/06/30 00:56:46 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-58065e0f-0508-4b67-a09d-fbbd8fca77f2 [root@hadoop101.yinzhengjie.org.cn ~]#