第一个MapReduce程序
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.使用Java代码实现一个MapReduce实战案例
1>.自定义Mapper
package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /* 用户自定义的Mapper要继承自己的父类。 接下来我们就要对"Mapper<LongWritable,Text,Text,IntWritable>"解释如下: 前两个参数表示定义输出的KV类型 LongWritable: 用于定义行首之间的偏移量,用于定义某一行的位置。 Text: 我们知道LongWritable可以定位某一行的偏移量,那Text自然是该行的内容。 后两个参数表示定义输出的KV类型: Text: 用于定义输出的Key类型 IntWritable: 用于定义输出的Value类型 */ public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> { //注意哈,我们这里仅创建了2个对象,即word和one。 private Text word = new Text(); private IntWritable one = new IntWritable(1); /* Mapper中的业务逻辑写在map()方法中; 接下来我们就要对"map(LongWritable key, Text value, Context context)"中个参数解释如下: key: 依旧是某一行的偏移量 value: 对应上述偏移量的行内容 context: 整个任务的上下文环境,我们写完Mapper或者Reducer都需要交给context框架去执行。 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿到行数据 String line = value.toString(); //将行数据按照逗号进行切分 String[] words = line.split(","); //遍历数组,把单词变成(word,1)的形式交给context框架 for (String word:words){ /* 我们将输出KV发送给context框架,框架所需要的KV类型正式我们定义在继承Mapper时指定的输出KV类型,即Text和IntWritable类型。 为什么不能写"context.write(new Text(word),new IntWritable(1));"? 上述写法并不会占用过多的内存,因为JVM有回收机制; 但是上述写法的确会大量生成对象,这回导致回收垃圾的时间占比越来越长,从而让程序变慢。 因此,生产环境中并不推荐大家这样写。 推荐大家参考apache hadoop mapreduce官方程序的写法,提前创建2个对象(即上面提到的word和one),然后利用这两个对象来传递数据。 */ this.word.set(word); context.write(this.word,this.one); } } }
2>.自定义Reducer
package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /* 用户自定义Reducer要继承自己的父类; 根据Hadoop MapReduce的运行原理,再写自定义的Reducer类时,估计你已经猜到了Reducer<Text,IntWritable,Text,IntWritable>的泛型。 前两个输入参数就是咱们自定义Mapper的输出泛型的类型,即: Text: 自定义Mapper输出的Key类型。 IntWritable: 自定义Mapper输出的Value类型 后两个参数表示定义输出的KV类型: Text: 用于定义输出的Key类型 IntWritable: 用于定义输出的Value类型 */ public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> { //定义一个私有的对象,避免下面创建多个对象 private IntWritable total = new IntWritable(); /* Reducer的业务逻辑在reduce()方法中; 接下来我们就要对"reduce(Text key, Iterable<IntWritable> values, Context context)"中个参数解释如下: key: 还记得咱们自定义写的"context.write(this.word,this.one);"吗? 这里的key指的是同一个单词(word),即相同的单词都被发送到同一个reduce函数进行处理啦。 values: 同理,这里的values指的是很多个数字1组成,每一个数字代表同一个key出现的次数。 context: 整个任务的上下文环境,我们写完Mapper或者Reducer都需要交给context框架去执行。 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //定义一个计数器 int sum = 0; //对同一个单词做累加操作,计算该单词出现的频率。 for (IntWritable value:values){ sum += value.get(); } //包装结果 total.set(sum); //将计算的结果交给context框架 context.write(key,total); } }
3>.自定义Driver
package cn.org.yinzhengjie.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置我们的当前Driver类路径(classpath) job.setJarByClass(WordCountDriver.class); //设置自定义的Mapper类路径(classpath) job.setMapperClass(WordCountMapper.class); //设置自定义的Reducer类路径(classpath) job.setReducerClass(WordCountReducer.class); //设置自定义的Mapper程序的输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置自定义的Reducer程序的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置输入数据 FileInputFormat.setInputPaths(job,new Path(args[0])); //设置输出数据 FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交我们的Job,返回结果是一个布尔值 boolean result = job.waitForCompletion(true); //如果程序运行成功就打印"Task executed successfully!!!" if(result){ System.out.println("Task executed successfully!!!"); }else { System.out.println("Task execution failed..."); } //如果程序是正常运行就返回0,否则就返回1 System.exit(result ? 0 : 1); } }
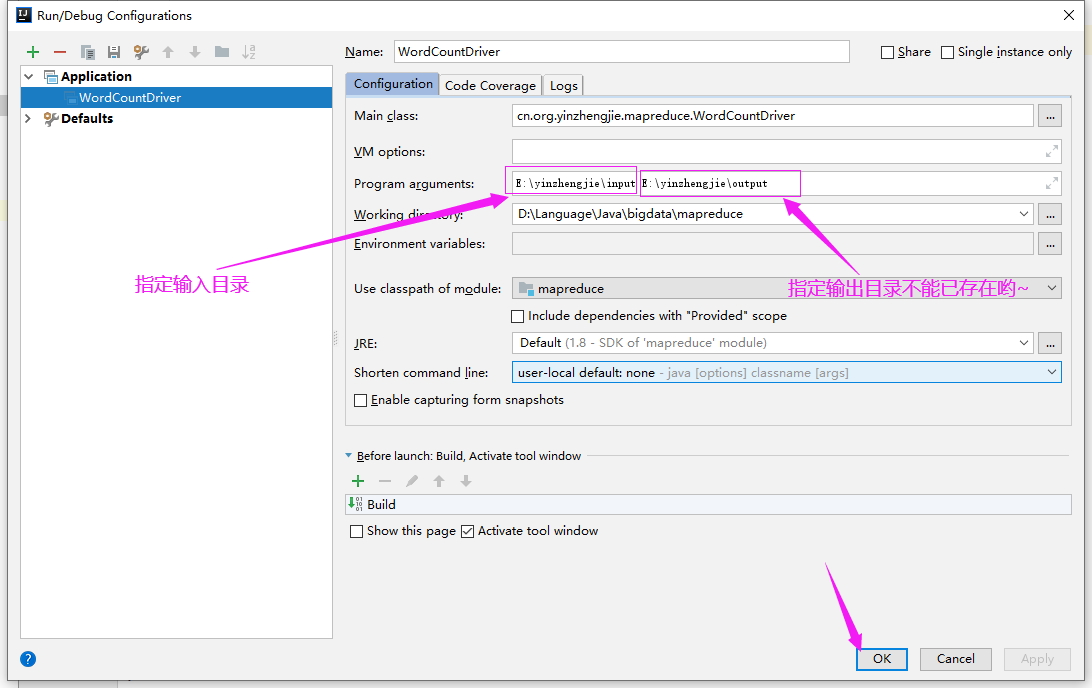
4>.配置Idea的参数


python,java,python,golang, yinzhengjie,php,php,shell, python,java,c++, yinzhengjie,c++,yinzhengjie,
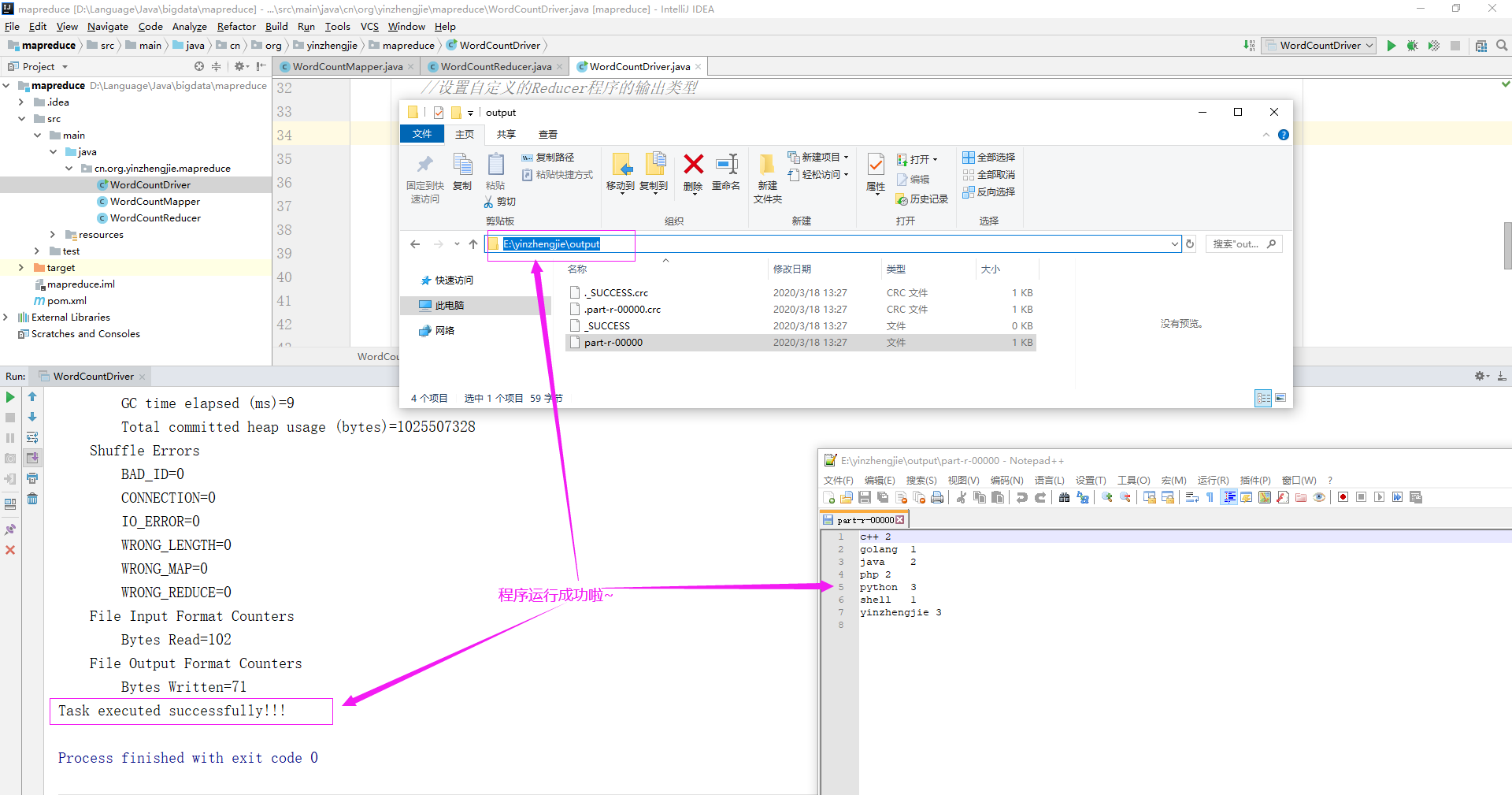
5>.运行程序成功
二.打包在集群上运行
1>.如下图所示,依次点击"View" ---> "Tool Windows" ---> "Maven Projects"
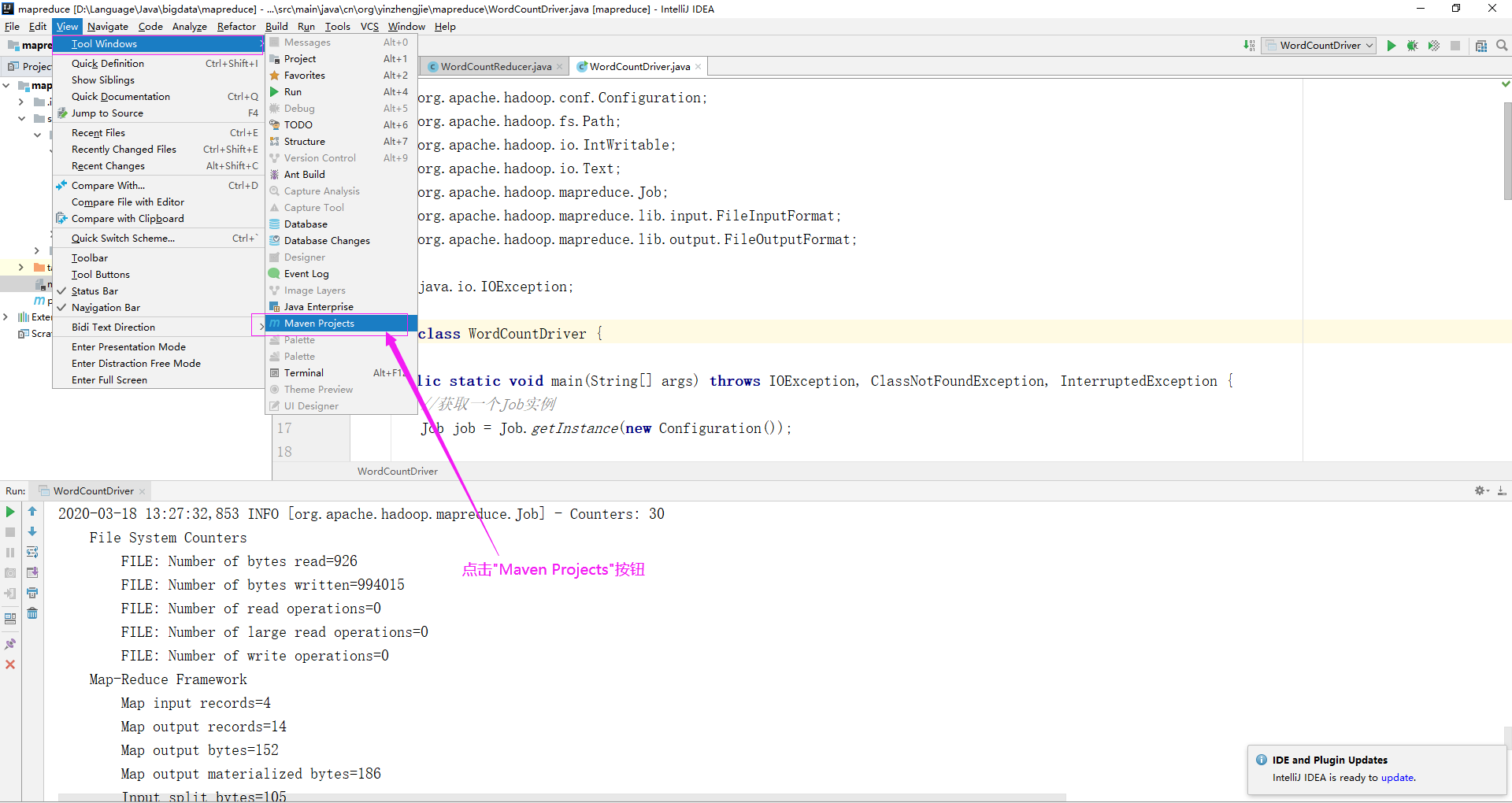
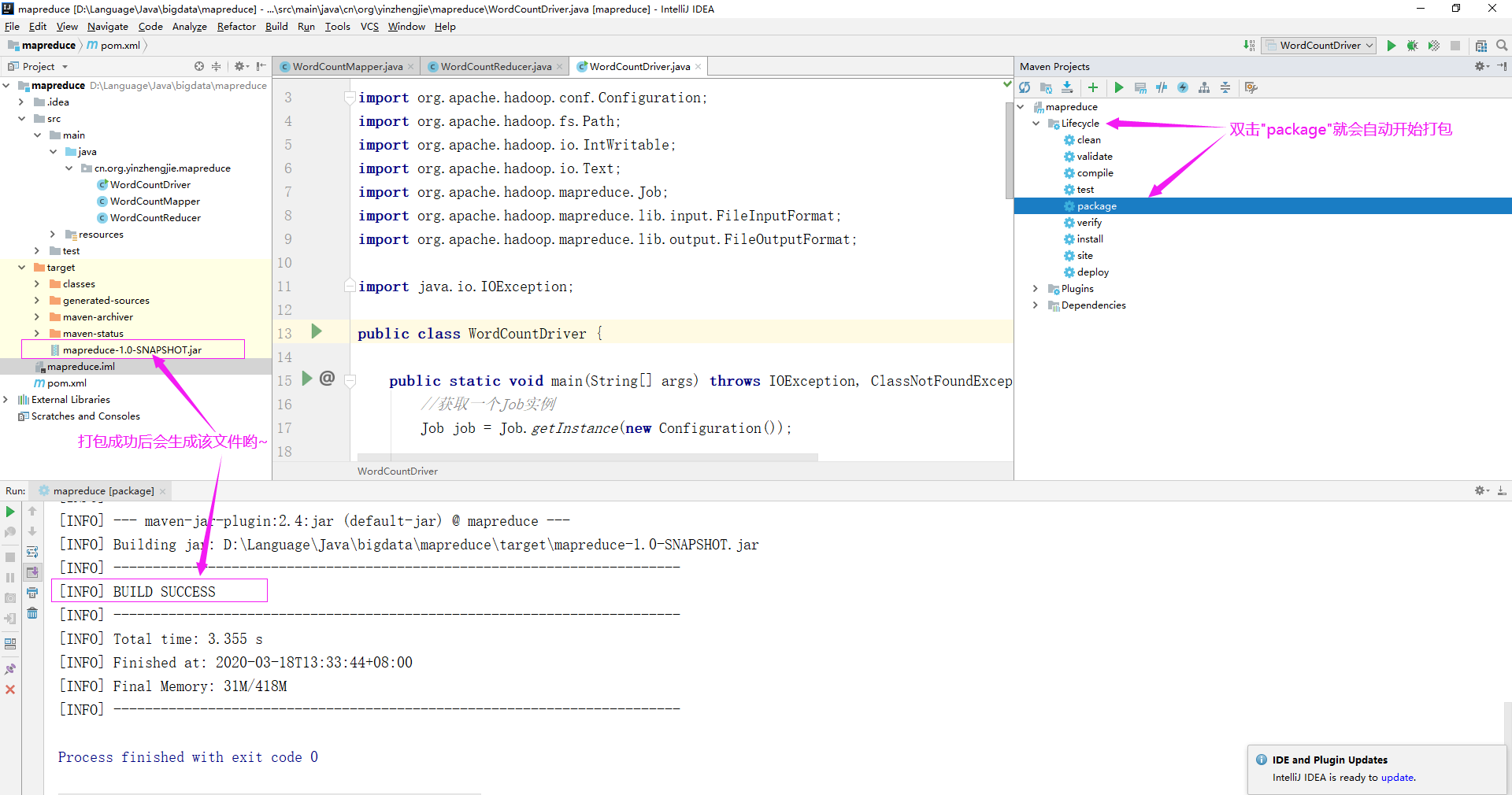
2>.如下图所示,依次点击"Lifecycle" ---> "package",等待打包完成
3>.运行咱们的jar包,指定输入和输出路径在hadoop集群(需要开启HDFS和YARN服务)
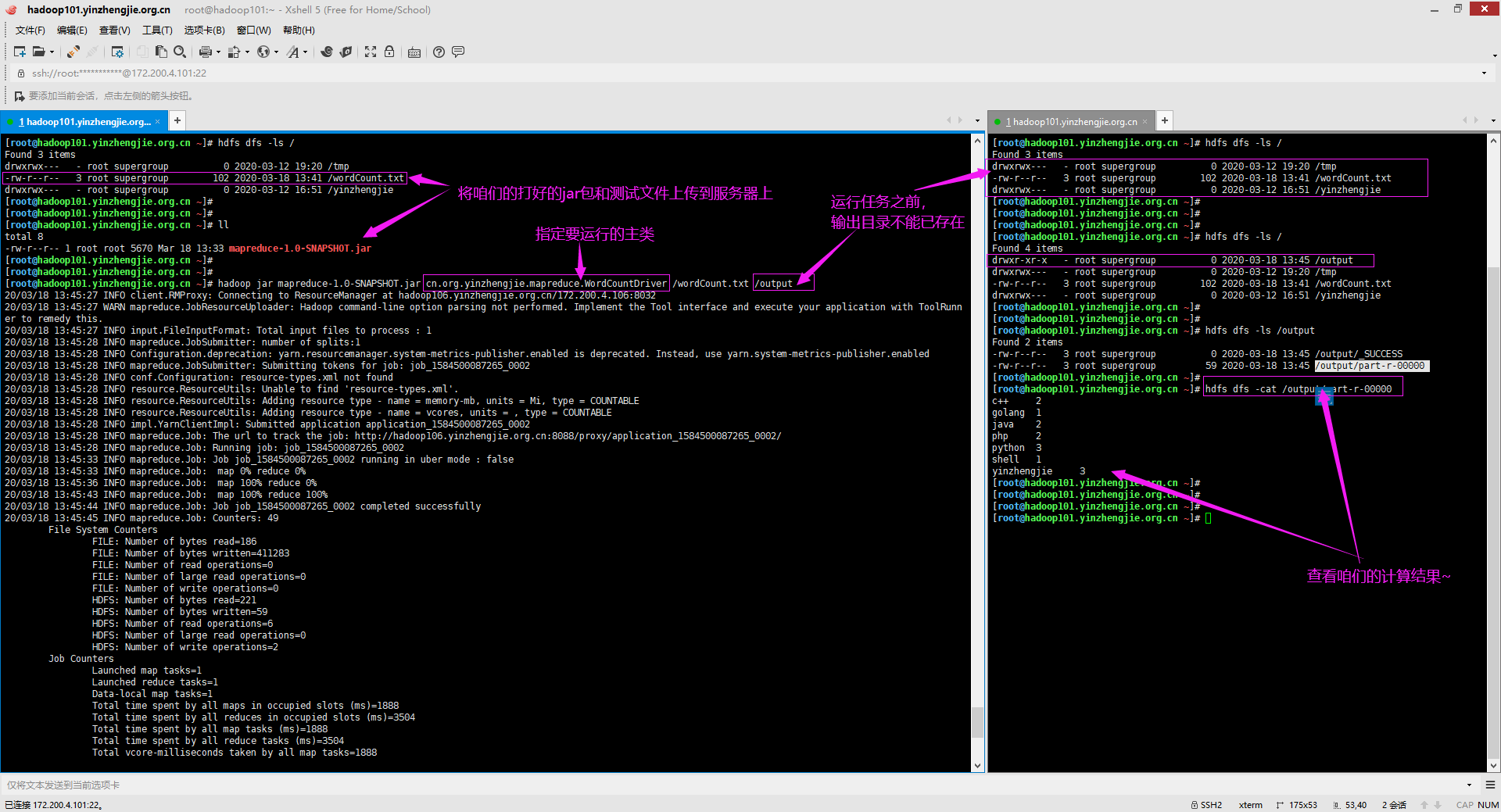
[root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls / Found 3 items drwxrwx--- - root supergroup 0 2020-03-12 19:20 /tmp -rw-r--r-- 3 root supergroup 102 2020-03-18 13:41 /wordCount.txt drwxrwx--- - root supergroup 0 2020-03-12 16:51 /yinzhengjie [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ll total 8 -rw-r--r-- 1 root root 5670 Mar 18 13:33 mapreduce-1.0-SNAPSHOT.jar [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hadoop jar mapreduce-1.0-SNAPSHOT.jar cn.org.yinzhengjie.mapreduce.WordCountDriver /wordCount.txt /output 20/03/18 13:45:27 INFO client.RMProxy: Connecting to ResourceManager at hadoop106.yinzhengjie.org.cn/172.200.4.106:8032 20/03/18 13:45:27 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunn er to remedy this.20/03/18 13:45:27 INFO input.FileInputFormat: Total input files to process : 1 20/03/18 13:45:28 INFO mapreduce.JobSubmitter: number of splits:1 20/03/18 13:45:28 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled 20/03/18 13:45:28 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1584500087265_0002 20/03/18 13:45:28 INFO conf.Configuration: resource-types.xml not found 20/03/18 13:45:28 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 20/03/18 13:45:28 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE 20/03/18 13:45:28 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE 20/03/18 13:45:28 INFO impl.YarnClientImpl: Submitted application application_1584500087265_0002 20/03/18 13:45:28 INFO mapreduce.Job: The url to track the job: http://hadoop106.yinzhengjie.org.cn:8088/proxy/application_1584500087265_0002/ 20/03/18 13:45:28 INFO mapreduce.Job: Running job: job_1584500087265_0002 20/03/18 13:45:33 INFO mapreduce.Job: Job job_1584500087265_0002 running in uber mode : false 20/03/18 13:45:33 INFO mapreduce.Job: map 0% reduce 0% 20/03/18 13:45:36 INFO mapreduce.Job: map 100% reduce 0% 20/03/18 13:45:43 INFO mapreduce.Job: map 100% reduce 100% 20/03/18 13:45:44 INFO mapreduce.Job: Job job_1584500087265_0002 completed successfully 20/03/18 13:45:45 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=186 FILE: Number of bytes written=411283 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=221 HDFS: Number of bytes written=59 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=1888 Total time spent by all reduces in occupied slots (ms)=3504 Total time spent by all map tasks (ms)=1888 Total time spent by all reduce tasks (ms)=3504 Total vcore-milliseconds taken by all map tasks=1888 Total vcore-milliseconds taken by all reduce tasks=3504 Total megabyte-milliseconds taken by all map tasks=1933312 Total megabyte-milliseconds taken by all reduce tasks=3588096 Map-Reduce Framework Map input records=4 Map output records=14 Map output bytes=152 Map output materialized bytes=186 Input split bytes=119 Combine input records=0 Combine output records=0 Reduce input groups=7 Reduce shuffle bytes=186 Reduce input records=14 Reduce output records=7 Spilled Records=28 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=234 CPU time spent (ms)=970 Physical memory (bytes) snapshot=450744320 Virtual memory (bytes) snapshot=4302458880 Total committed heap usage (bytes)=286785536 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=102 File Output Format Counters Bytes Written=59 Task executed successfully!!! [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls / Found 3 items drwxrwx--- - root supergroup 0 2020-03-12 19:20 /tmp -rw-r--r-- 3 root supergroup 102 2020-03-18 13:41 /wordCount.txt drwxrwx--- - root supergroup 0 2020-03-12 16:51 /yinzhengjie [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls / Found 4 items drwxr-xr-x - root supergroup 0 2020-03-18 13:45 /output drwxrwx--- - root supergroup 0 2020-03-12 19:20 /tmp -rw-r--r-- 3 root supergroup 102 2020-03-18 13:41 /wordCount.txt drwxrwx--- - root supergroup 0 2020-03-12 16:51 /yinzhengjie [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls /output Found 2 items -rw-r--r-- 3 root supergroup 0 2020-03-18 13:45 /output/_SUCCESS -rw-r--r-- 3 root supergroup 59 2020-03-18 13:45 /output/part-r-00000 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -cat /output/part-r-00000 c++ 2 golang 1 java 2 php 2 python 3 shell 1 yinzhengjie 3 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#