Scala进阶之路-为什么要学习Scala以及开发环境搭建
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
最近人工智能和大数据那是相当的火呀,人工智能带动了Python的流行,区块链带动了golang的流行,而大数据带动了Scala的流行。可能你会否定我,你可能会说大数据当然是带动Java的流行啊,因为Hadoop生态圈的大部分组件都是由Java语言编写的,不过换句话说,哪个大数据开发工程师不会java语言呢?而近几年流行的Spark技术哪个做大数据开发的或者大数据运维的不了解呢?而Spark是由Scala语言编写的,因此我们得系统的学习一下Scala语言。
我们可以在很多招聘网站,如智联招聘,猎聘网,拉勾网,boss直聘等网站对大数据开发工程师的要求是必须得会Scala语言,因此身为一个大数据开发工程师,Scala语言应该是信手拈来的东西。一个初级的Scala开发工程师可以熟练使用Scala编写Spark程序;
一个中级Scala开发工程师可以动手编写一个简易Spark通信框架;而一个高级Scala开发工程师可以达到阅读Spark内核源码的实力。那么问题来了?你的Scala已经达到何种境界了呢?如果你到现在还不知道Scala是什么东东的话,可以跟随我的脚步,一起来系统的学习一下Scala语言吧。
一.Scala语言的特点
1>.什么是Scala
答:Scala 是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特 性 。 Scala 运 行 于 Java 平 台 ( Java 虚 拟 机 ), 并 兼 容 现 有 的 Java 程 序 。
2>.为什么要学Scala
答:原因有三:优雅,速度快,能融合到Hadoop生态圈。
1.优雅: 这是框架设计师第一个要考虑的问题,框架的用户是应用开发程序员,API 是否优雅直接影响用户体验。 2.速度快: Scala 语言表达能力强,一行代码抵得上 Java 多行,开发速度快;Scala 是静态编译的,所以和 JRuby,Groovy 比起来速度会快很多。 3. 能融合到 Hadoop 生态圈: Hadoop 现在是大数据事实标准,Spark 并不是要取代 Hadoop,而是要完善 Hadoop 生态。JVM 语言大部分可能会想到 Java,但 Java 做出来的 API 太丑,或者想实现一个优雅的 API 太费劲。
在互联网上,有人拿Java程序员和Scala程序员进行对比,虽然有点夸张,但是确实能体现出大家对Scala的喜爱,如下图:

二.安装Scala SDK
1>.登录Scala官网(https://www.scala-lang.org/)
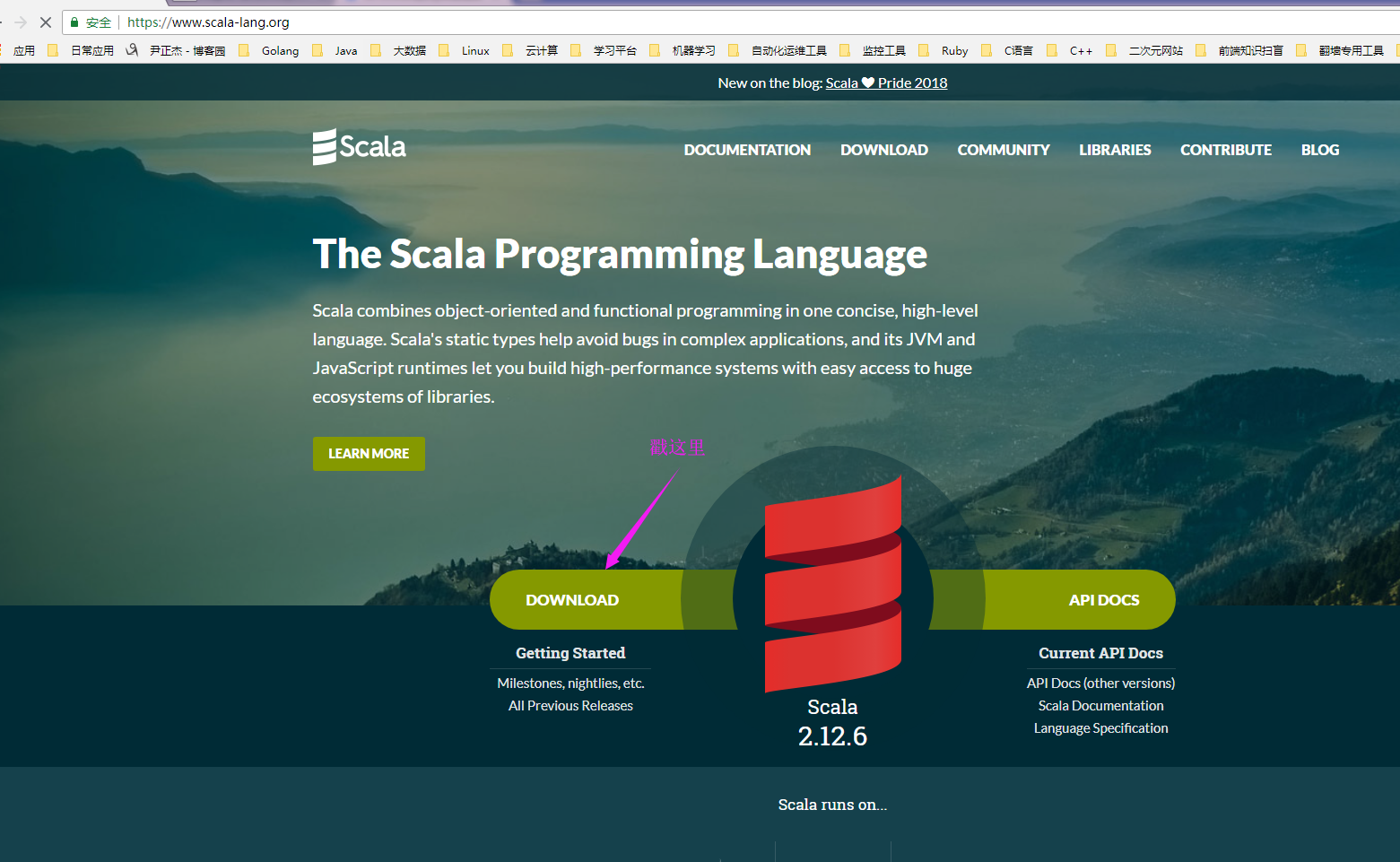
2>.不推荐直接使用最新版本的Scala

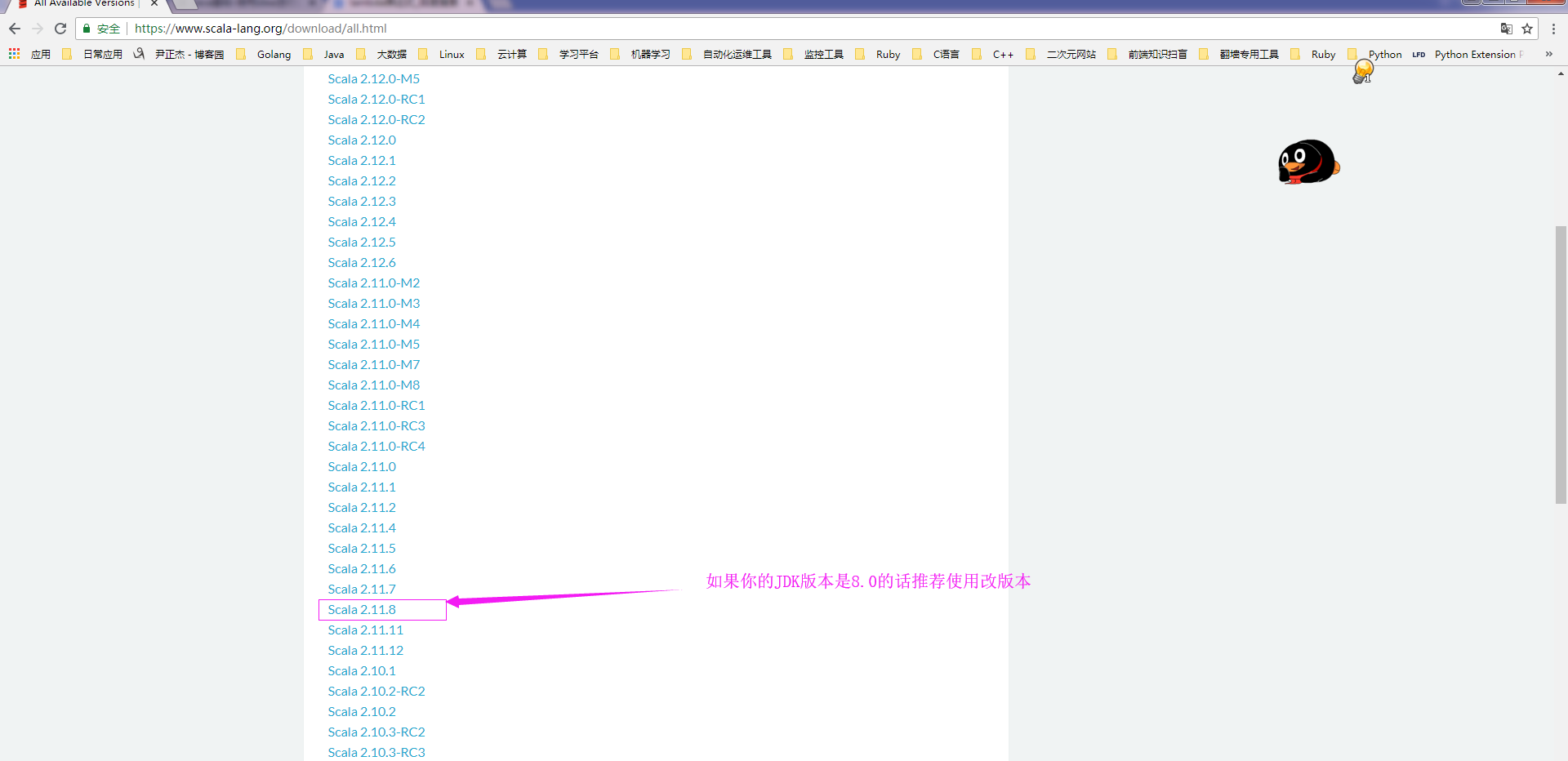
3>.查看所有的Scala官网之前发布的版本

4>.选择与JKD8.0版本的Scala
5>.确保使用的Java版本
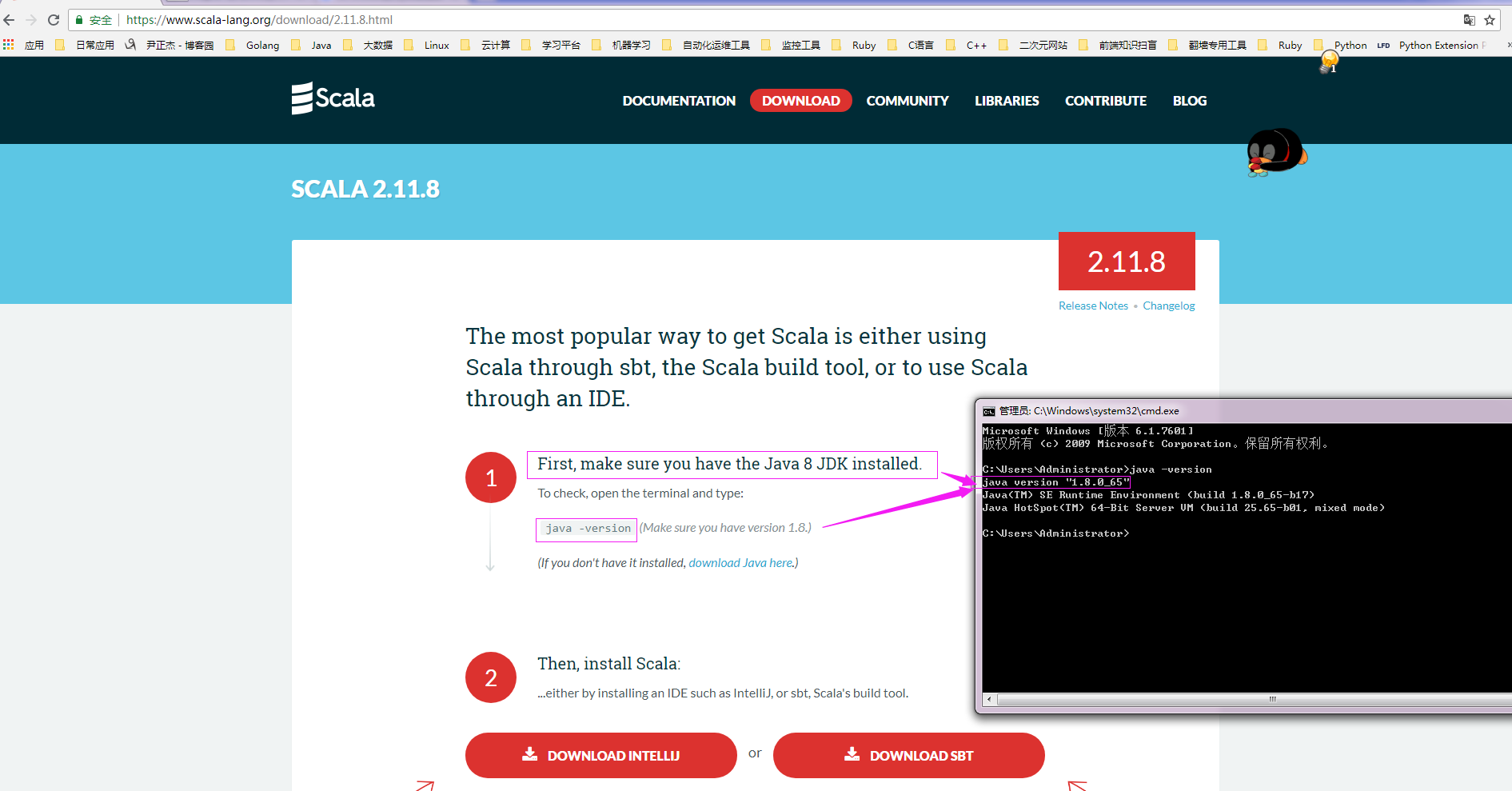
6>.选择操作系统对应的安装包

7>.Window下安装 Scala SDK
访问 Scala 官网 http://www.scala-lang.org/下载 Scala 编译器安装包,目前最新版本是 2.12.x,但是目前大多数的框架都是用 2.11.x 编写开发的,Spark2.x 使用的就是 2.11.x,所以这里推荐 2.11.x 版本,下载 scala-2.11.8.msi 后点击下一步就可以了.。安装目录如下:
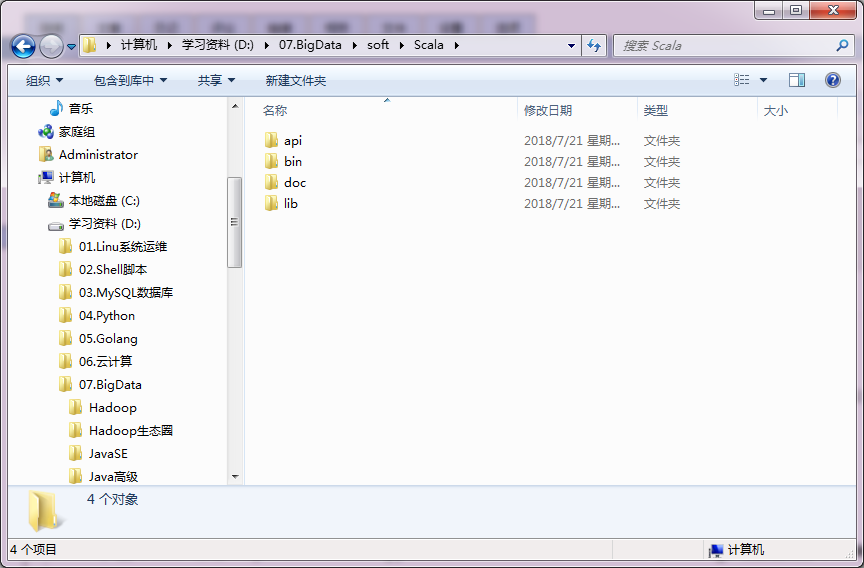
添加变量如下:
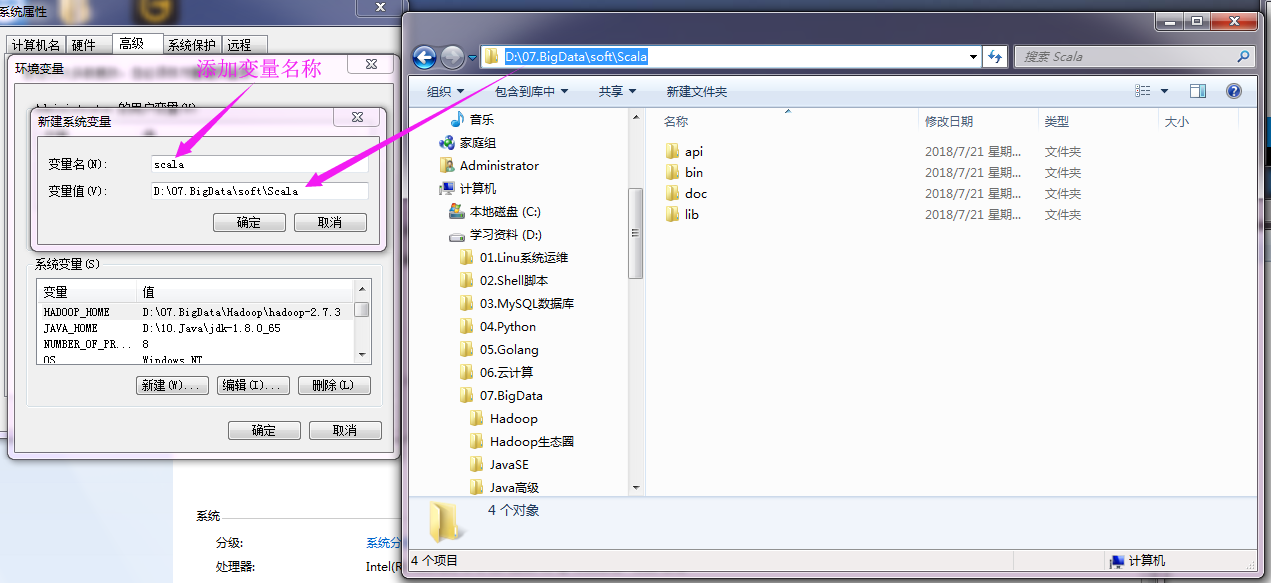
配置环境变量如下:

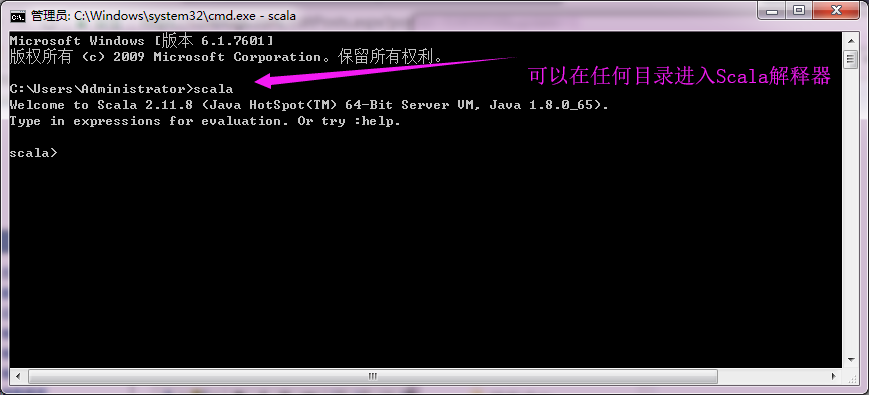
验证是否配置成功:
8>.Linux下安装 Scala SDK
下载 Scala 地址 http://downloads.typesafe.com/scala/2.11.8/scala-2.11.8.tgz 然后解压 Scala 到指定目录并配置环境变量,将 scala 加入到 PATH 中。具体操作如下:
[yinzhengjie@s101 ~]$ cd /home/yinzhengjie/download/ [yinzhengjie@s101 download]$ wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz [yinzhengjie@s101 download]$ ll total 28008 -rw-r--r--. 1 yinzhengjie yinzhengjie 28678231 Jul 20 21:18 scala-2.11.8.tgz [yinzhengjie@s101 download]$ [yinzhengjie@s101 download]$ tar -zxf scala-2.11.8.tgz -C /soft/ [yinzhengjie@s101 download]$ ln -s /soft/scala-2.11.8/ /soft/scala [yinzhengjie@s101 download]$ ll /soft/ | grep scala lrwxrwxrwx. 1 yinzhengjie yinzhengjie 19 Jul 20 21:29 scala -> /soft/scala-2.11.8/ drwxrwxr-x. 6 yinzhengjie yinzhengjie 46 Mar 4 2016 scala-2.11.8 [yinzhengjie@s101 download]$ [yinzhengjie@s101 download]$ tail -3 /etc/profile #ADD Scala PATH export Scala_HOME=/soft/scala PATH=$PATH:$Scala_HOME/bin [yinzhengjie@s101 download]$ source /etc/profile [yinzhengjie@s101 download]$ [yinzhengjie@s101 download]$ scala -version Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL [yinzhengjie@s101 download]$
三.Idea中创建一个Scala工程
1>.安装Idea
安装破解版方式可以参考:https://www.cnblogs.com/yinzhengjie/p/9080387.html。
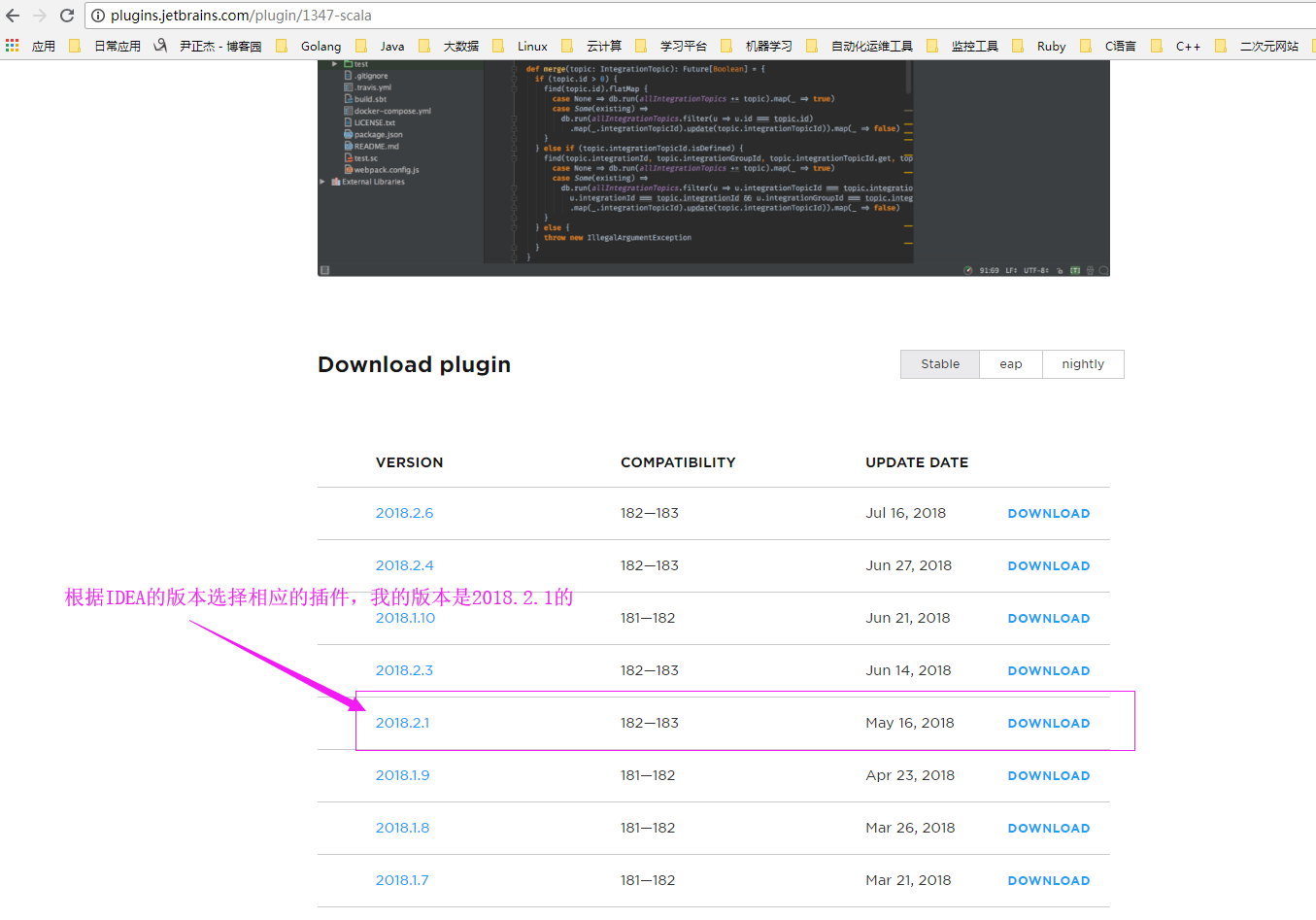
2>.下载 IEDA 的 scala 插件
下载地址:http://plugins.jetbrains.com/idea_ce
3>.IDEA Scala 插件的离线安装
点击设置:

点击插件:

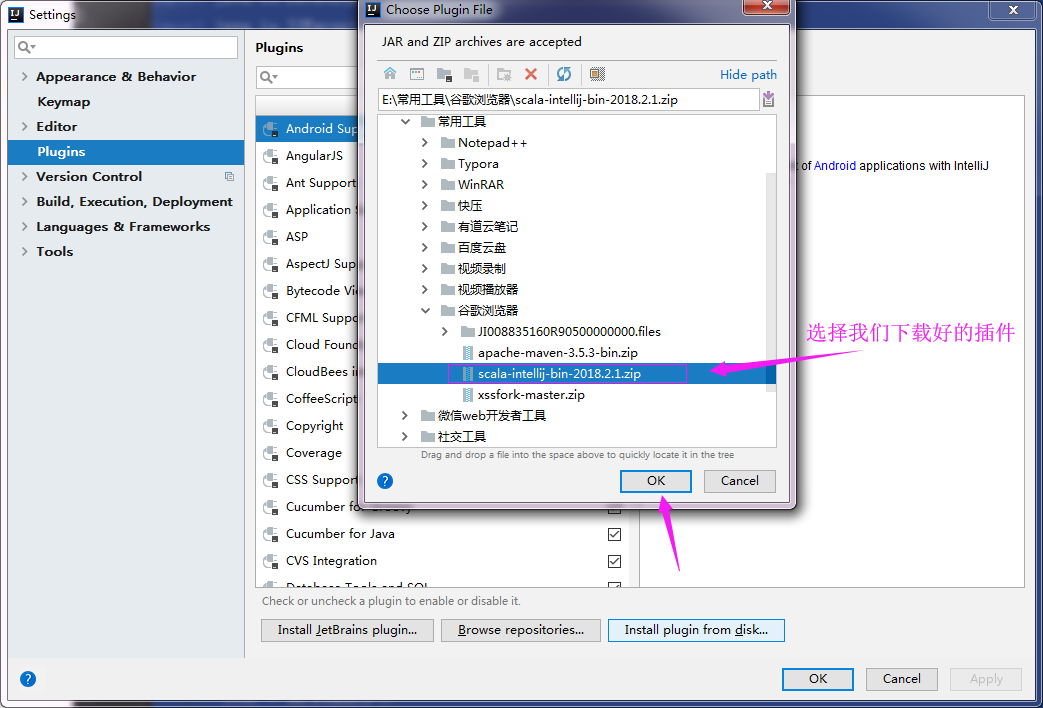
点击从磁盘中安装插件:
4>.IDEA Scala 插件的在线安装

等待安装完毕:
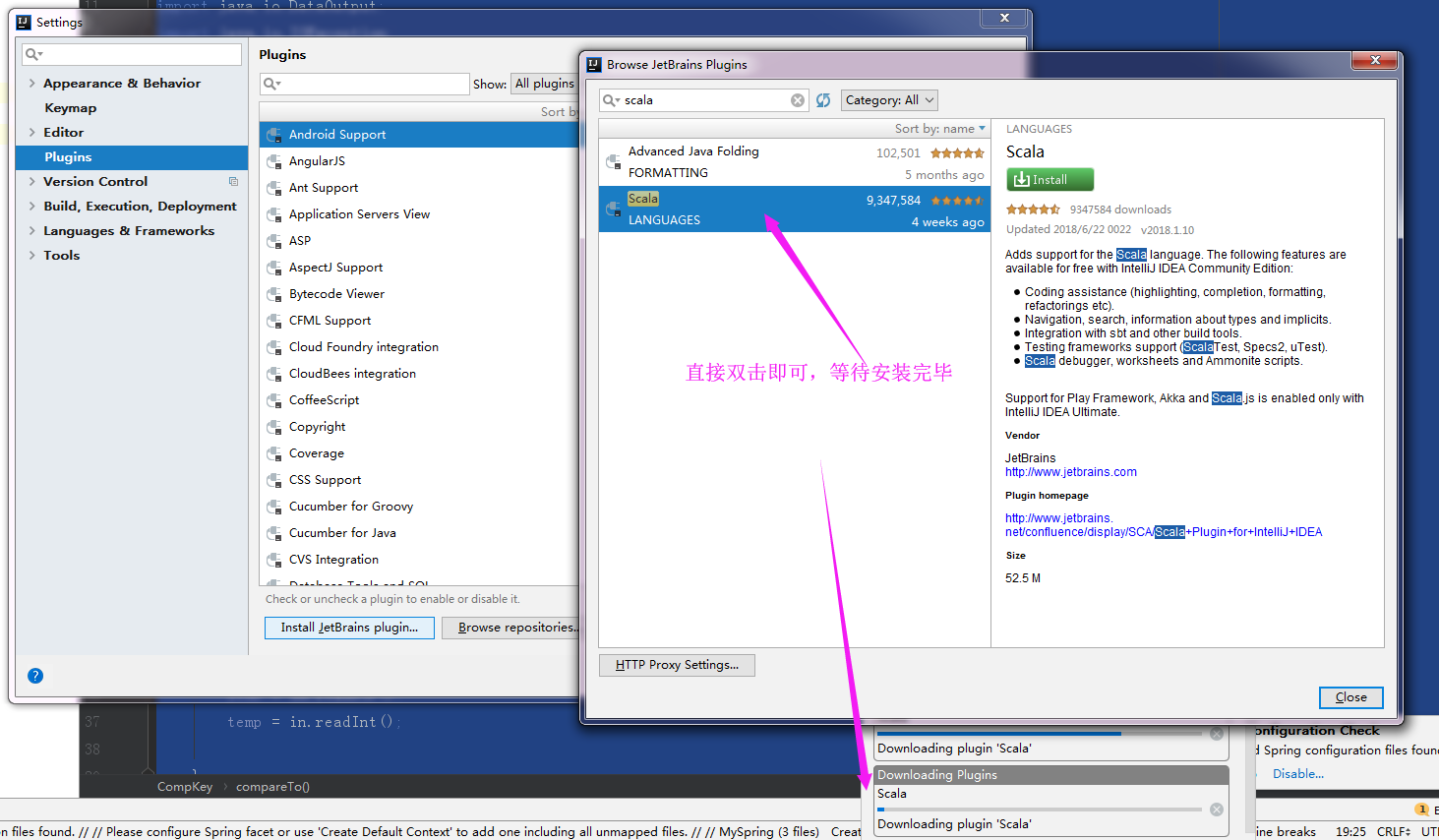
注意:不管是离线安装还是在线安装都需要重启Idea哟!
四.Idea中创建一个Scala工程
1>.创建一个新的模块

2>.选择Scala版本(导入Scala SDK)

3>.创建Scala文件
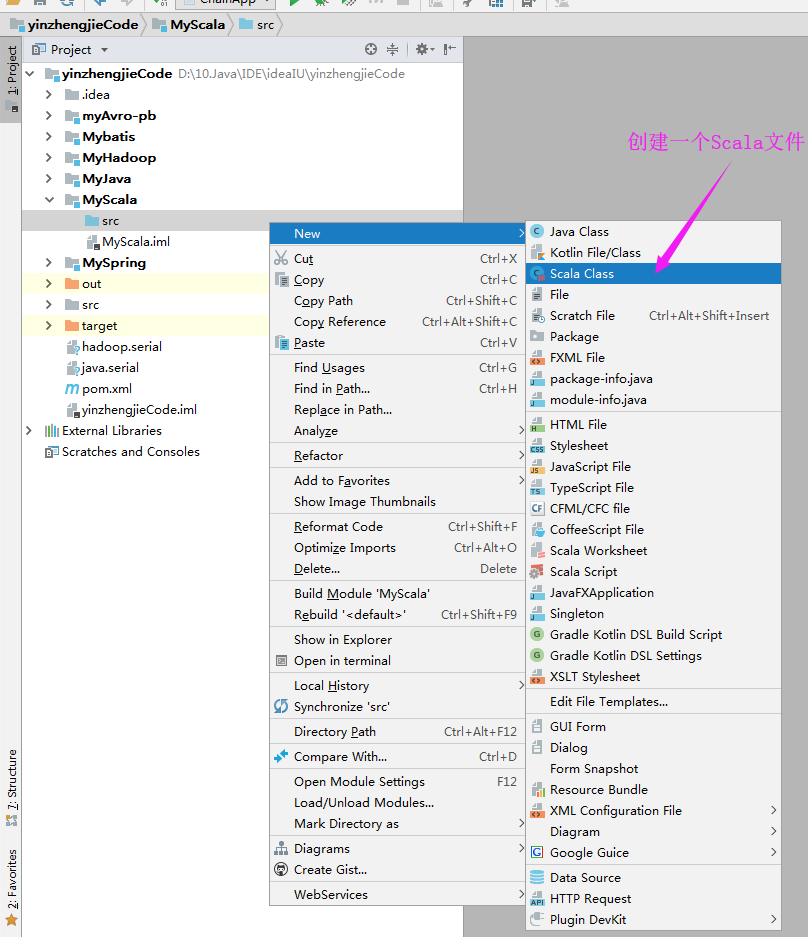
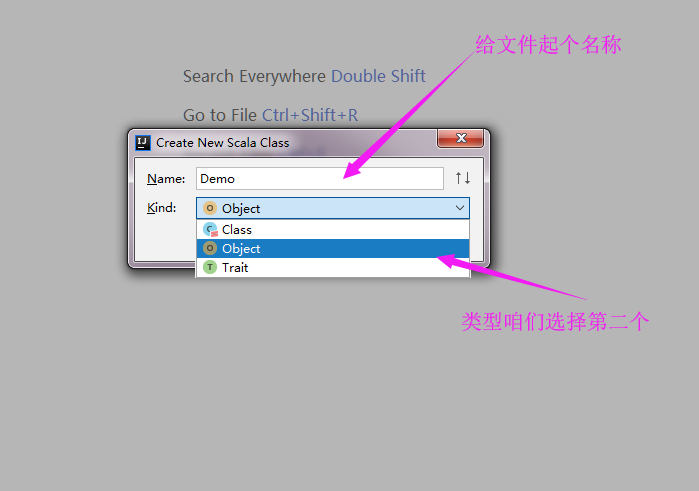
4>.选择Object类型
5>.编写Scala测试代码
/* @author :yinzhengjie Blog:http://www.cnblogs.com/yinzhengjie/tag/Scala%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ EMAIL:y1053419035@qq.com */ object Demo { /** * main 函数是程序的入口函数 */ def main(args: Array[String]): Unit = { print("Hello,Scala! I'm yinzhengjie!") } } /* 以上代码执行结果如下: Hello,Scala! I'm yinzhengjie! */