Hadoop基础-MapReduce的工作原理第二弹
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Split(切片)
1>.MapReduce处理的单位(切片)
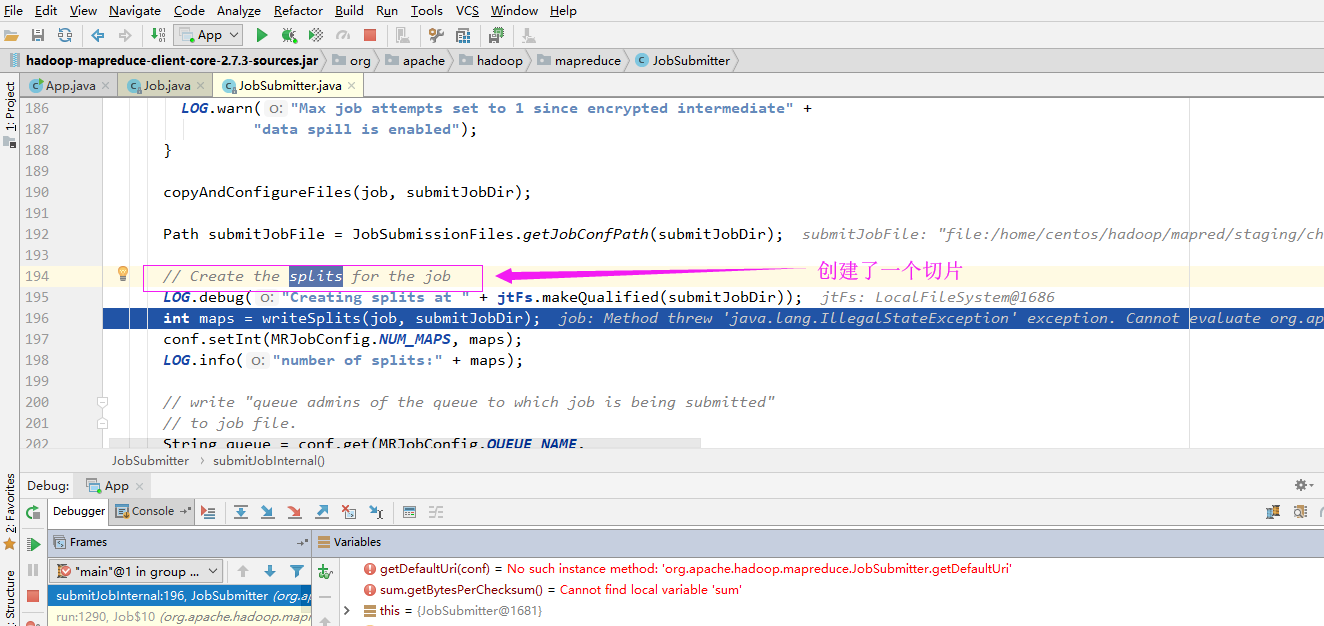
想必你在看MapReduce的源码的时候,是不是也在源码中看到了一行注释“//Create the splits for the job”(下图是我跟源码的部分截图),这个切片是MapReduce的最重要的概念,没有之一!因为MapReduce处理的单位就是切片。
2>.逻辑切割
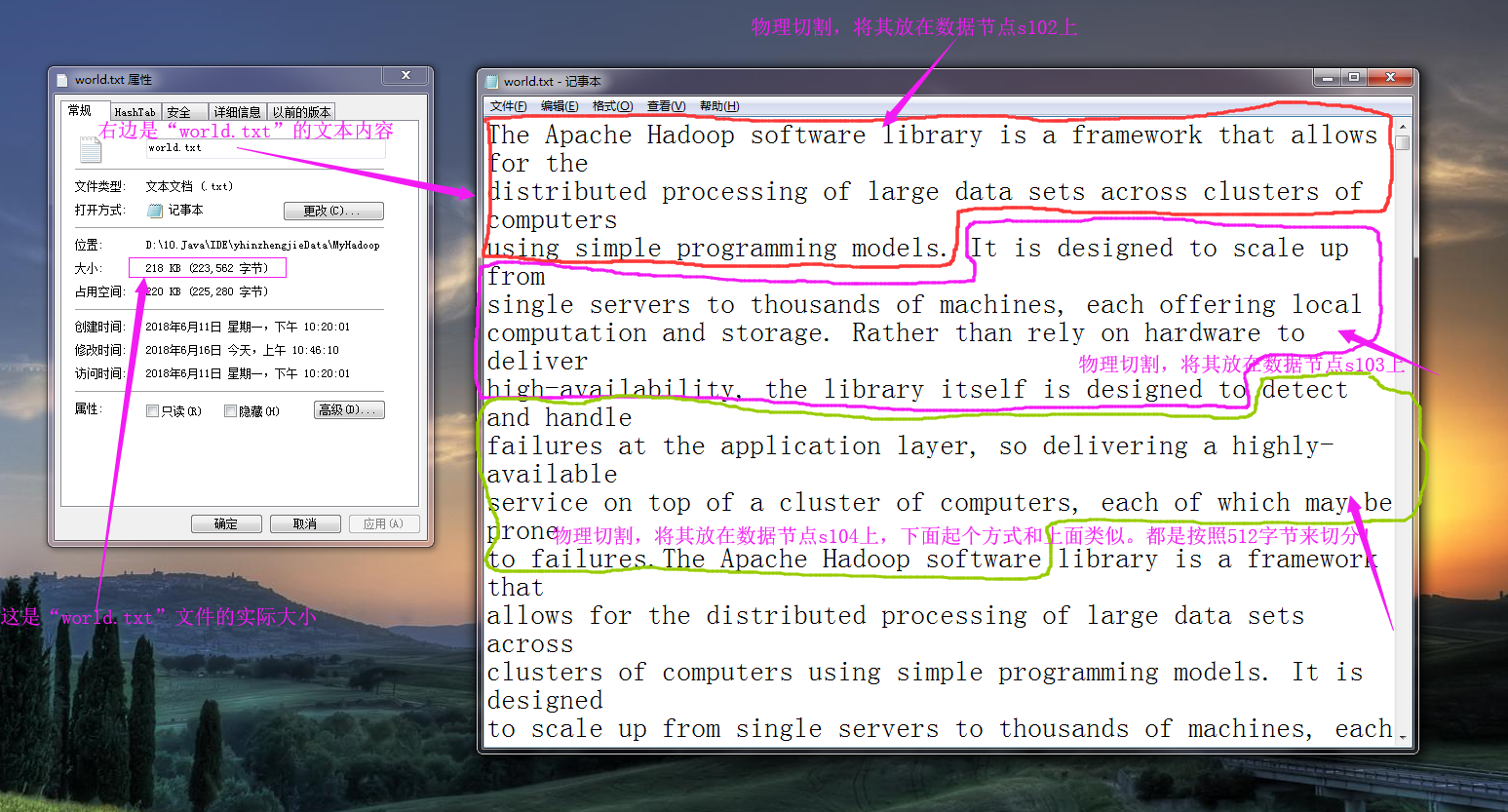
还记得hdfs存储的默认单位是什么吗?没错,默认版本是块(2.x版本的默认大小是128M),在MapReduce中默认处理的单位就是Split。其实切片本质上来说仍然是块,只不过和hdfs中的块是有所不同的。我们知道hdfs在存储一个大于1G的文件,会将文件按照hdfs默认的大小进行物理切割(将一个文件强行拆开,所有文件都是支持物理切割的!),放在不同的DataNode服务器上,而咱们的MapReduce的Split只是逻辑切割。
所谓的逻辑切割会判断切割处是否是行分隔符,换句话说,逻辑切割在切割文件的时候并不能像物理切割那样按照指定大小切割,而是按照程序员指定的规则进行切割(Split)。我们来举个例子,还记得我们之前写的一个单词统计的程序吗(https://www.cnblogs.com/yinzhengjie/p/9153256.html)?为了实验方便,我们可以把hdfs默认的128M改为512字节,那么我们在存储“world.txt”文件时,其物理切割大致用下图表示为:
而所谓的逻辑切割是程序员指定规则进行切割的,比如我们将“word.txt”按照空格进行切分,大致逻辑如下图所示:(逻辑切割很灵活的,它可以是按空格切割,也可以按行切割,还可以按照“ ”切割,在SequenceFile的话就直接是key和value的形式取值了,相对来说更正规,推荐使用这类的文件格式,我这里为了演示方便,就直接用文本类型格式进行切割操作。)
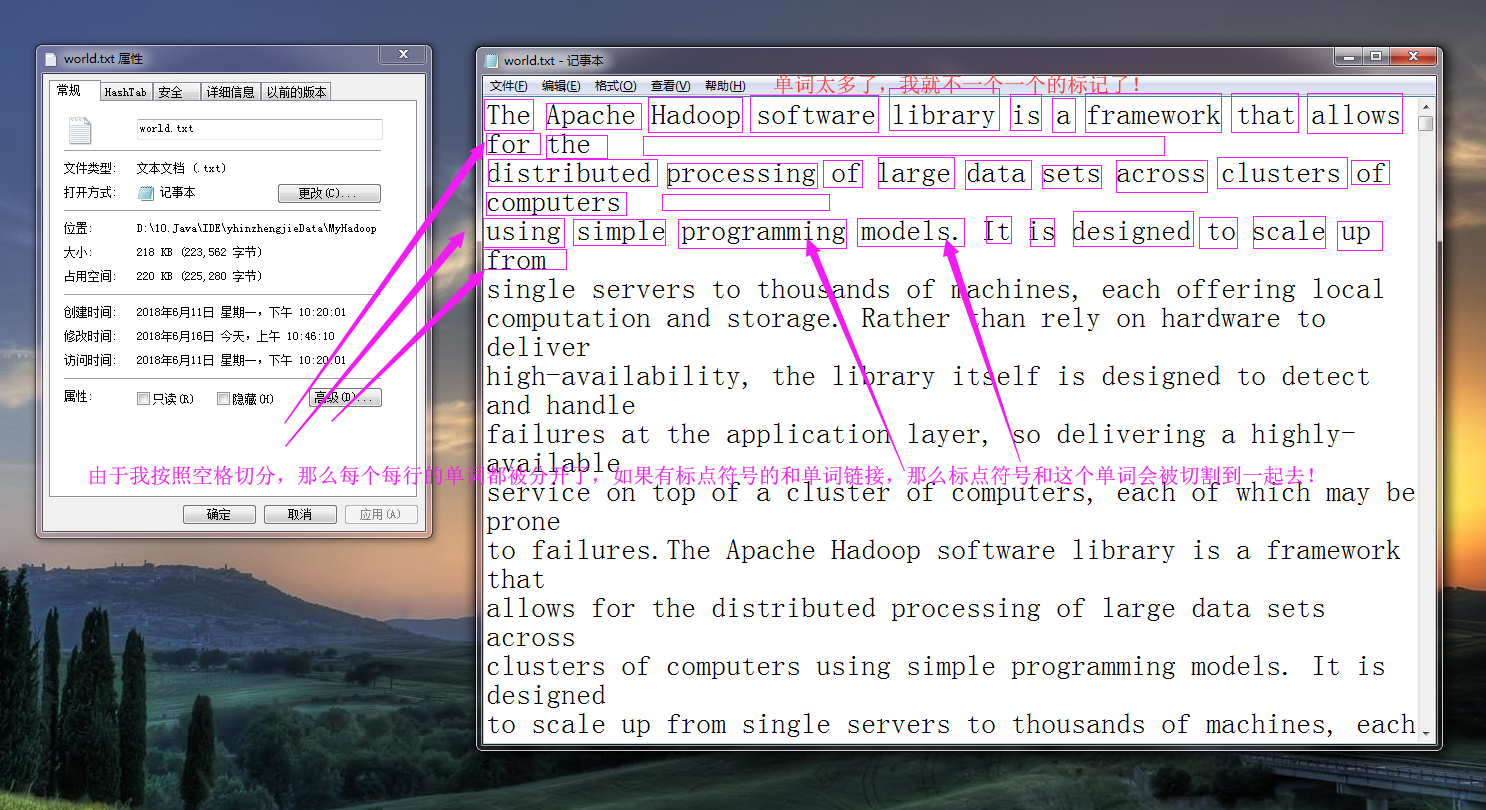
文本文件默认都是可以切割的(如上图所示),由于我们处理的是大数据,处理的数据可能不止是文本,还有视频,图片等等,比如淘宝公司的举行的双十一活动,一天光记录用户访问量就得需要“1PB”的数据量,如果这个时候我们还用文本文件去存储的话就不太合适了,实际上hadoop提供了一种SequenceFile容器文件,它不仅仅可以按照特定的格式存储文本信息,还支持Deflate,Gzip,Bzip2,Lz4,Snappy等压缩算法,其中Bzip2是极致压缩比例,而Lz4,Lzo和Snappy则是优化压缩速度,在生产环境下根据算法相关特性进行技术选型(当然除了hadoop序列化,还有Avro,Protocol Buffers等序列化技术都是可以供你选择的)。
这些算法都是支持物理切割的,注意:Lzo(with index)和Bzip2是可逻辑切割的算法,适合在MR中使用。如果你的SequenceFile不是使用Lzo或是BZip进行压缩的,那就麻烦了,因为他们不支持逻辑切割,就会出现以下的情况。
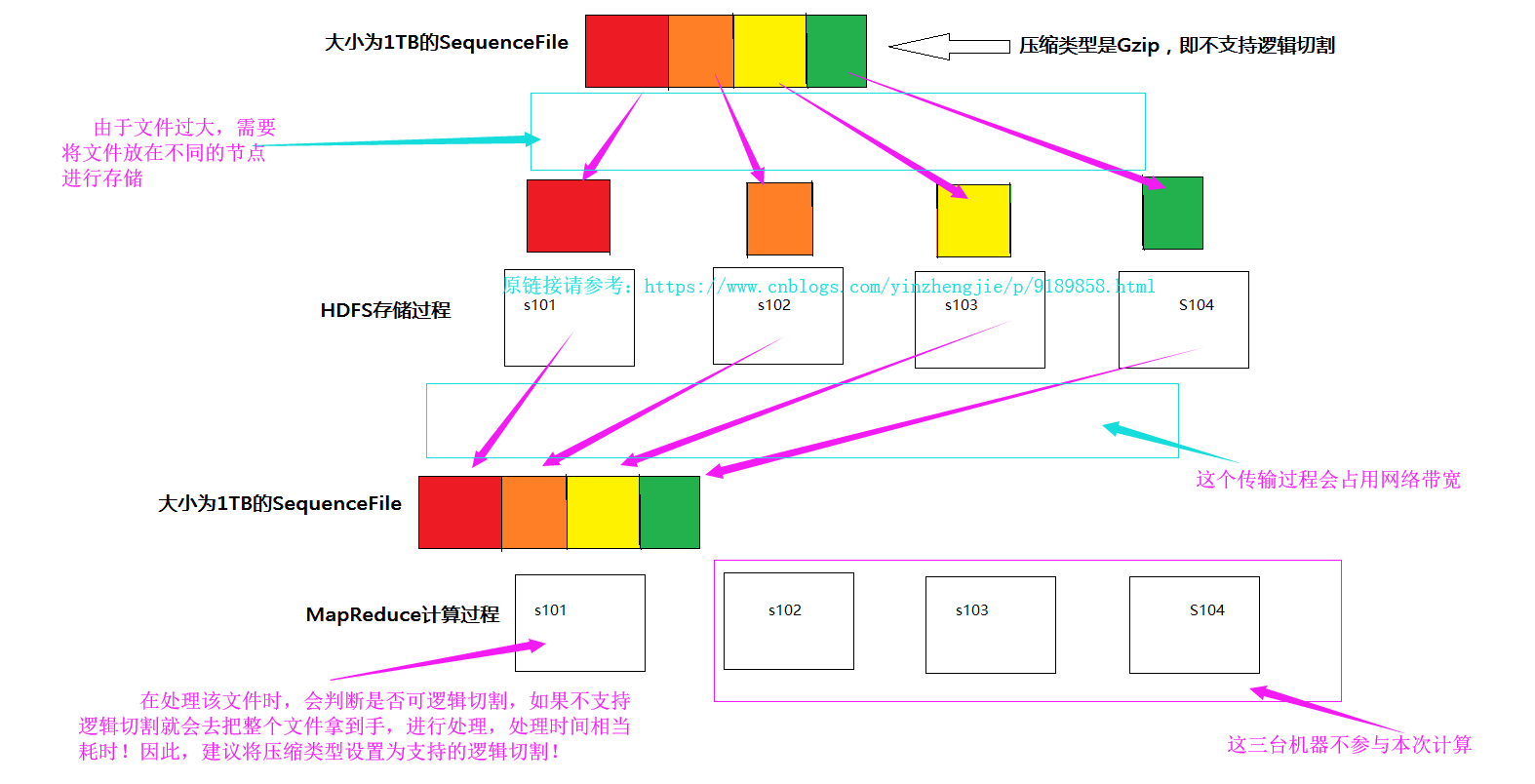
3>.计算切片数量
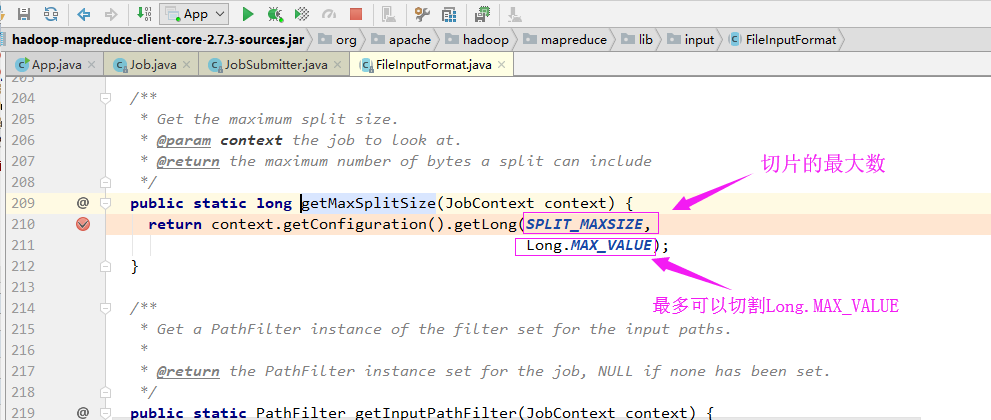
从源代码中可以看出,有一个变量为"MinSize",其值为“1”

从源代码中可以看出,有一个变量为"MaxSize",其值为“long.Max_Value”
实际切片大小从代码调试的大小(长度)如下:
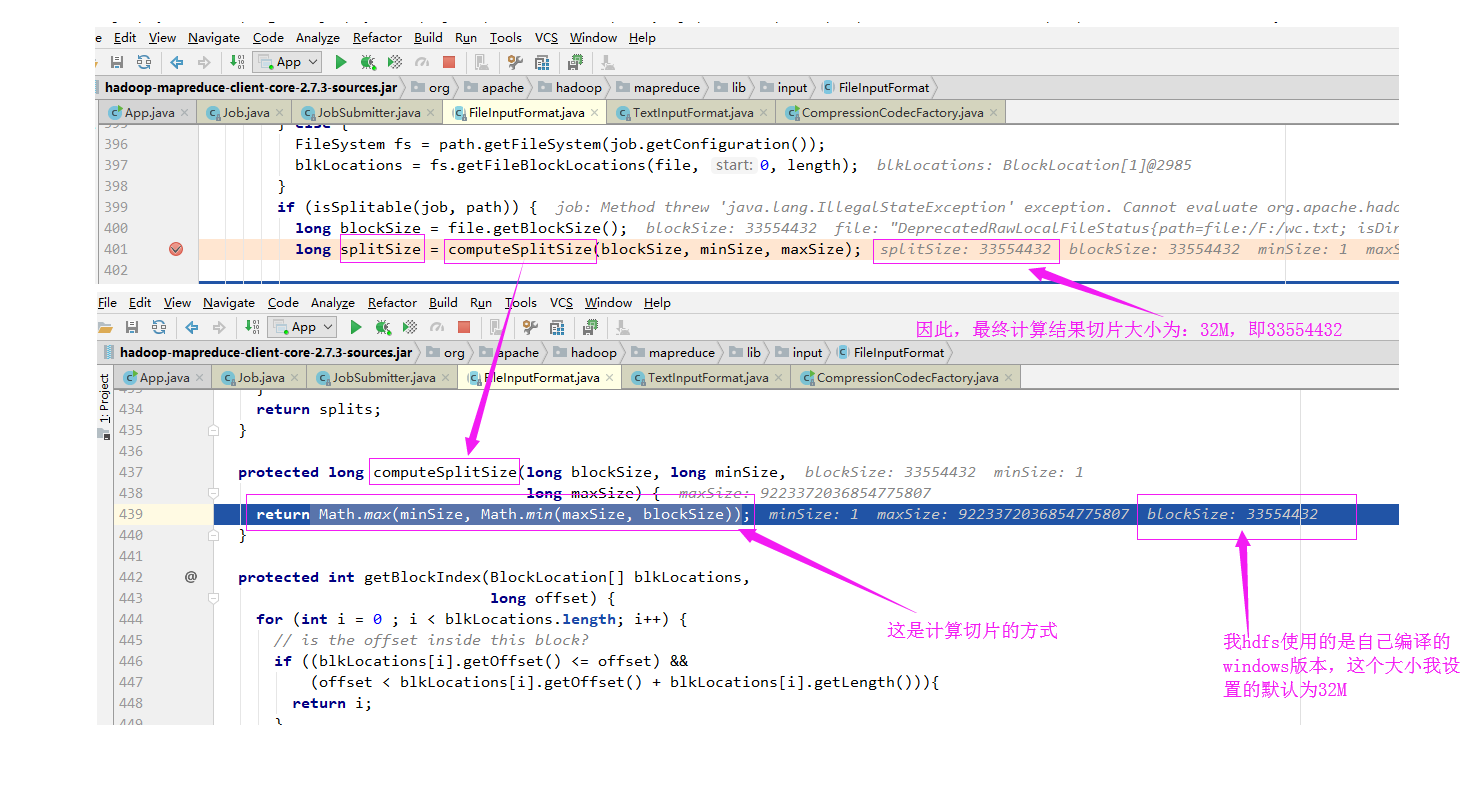
确认切片的偏移量:

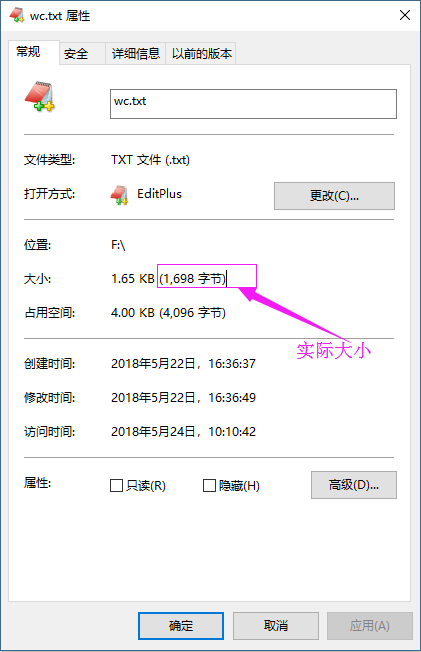
偏移量“0+1698”指的是文件的偏移量,如果文件较大,可能会被切割成多个切片进行处理,由于我测试的文件比较小,因此就被MapReduce切割成一个了,这个1698其实是文件的实际大小,如下:
4>.创建切片列表
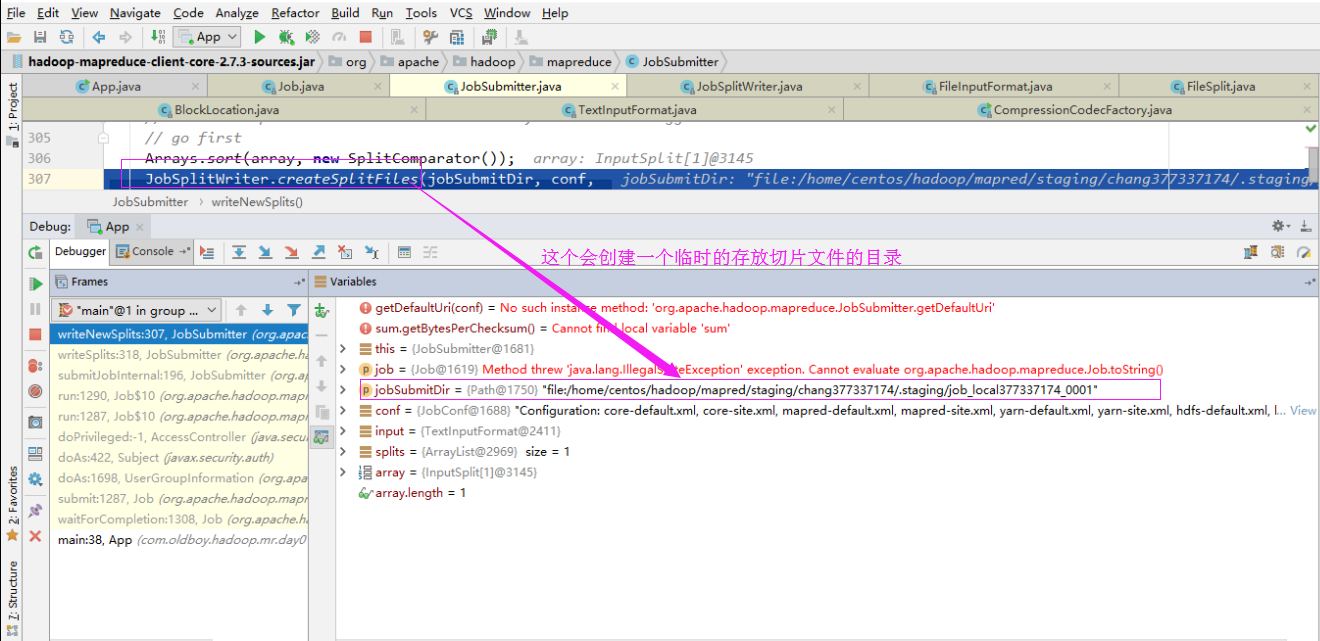
我们可以去这个切片目录中看看,如下:

5>..编写作业
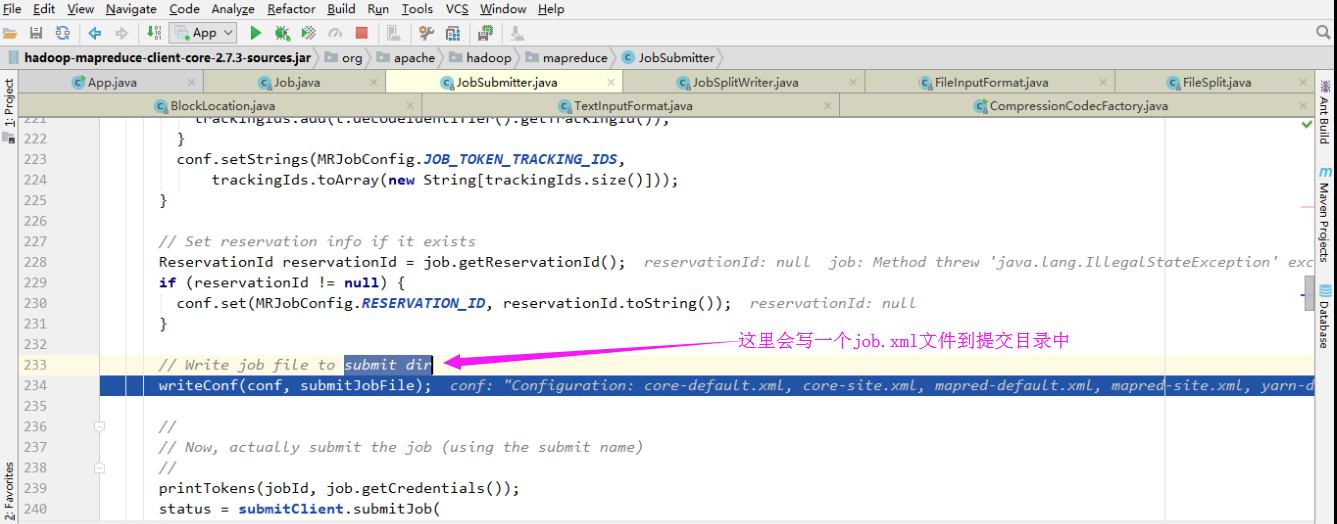
这个job文件和切片存放在同一个目录中:
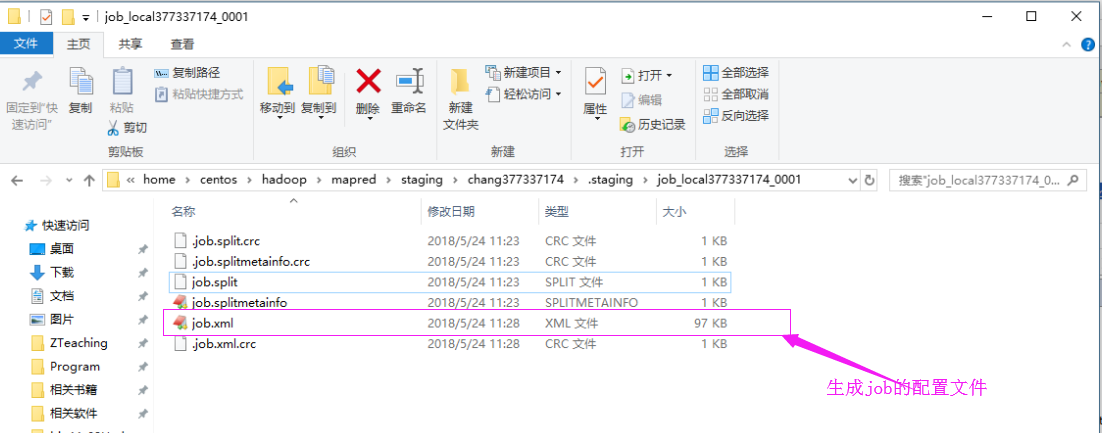
5>.提交作业

6>.创建当前job(比之前的job.xml更加详细的任务)
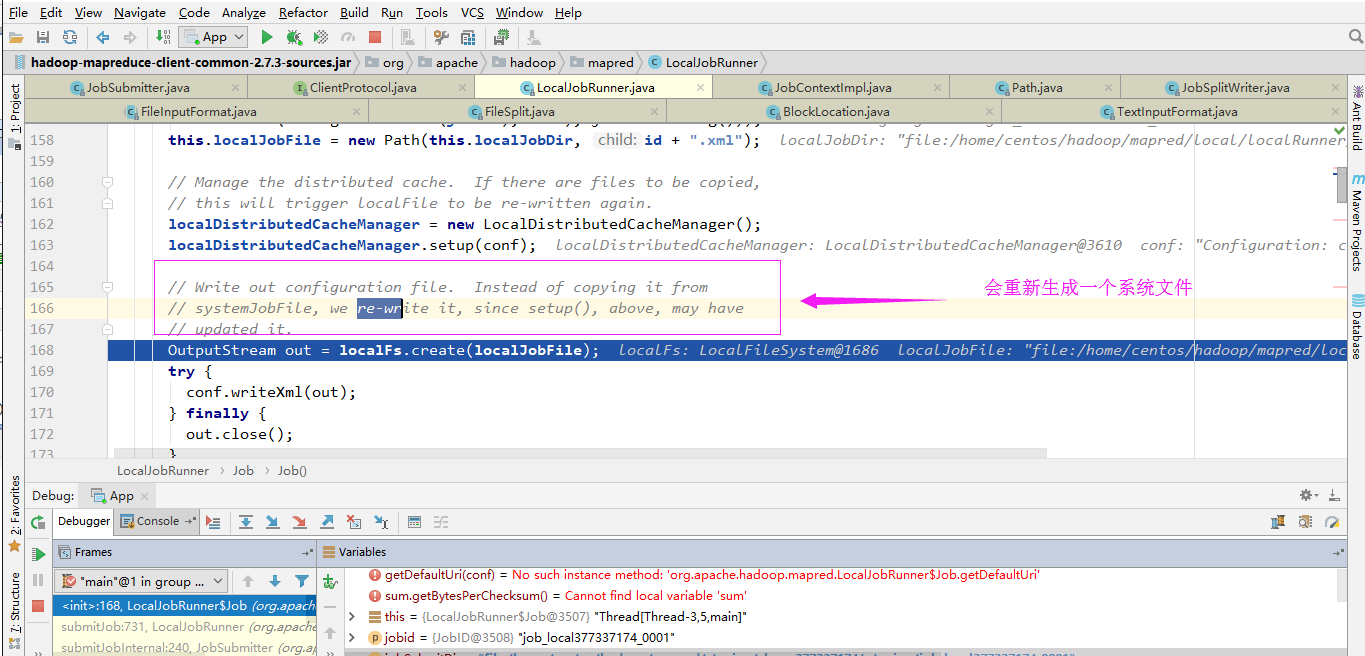
具体存放路径如下:
7>.启动线程
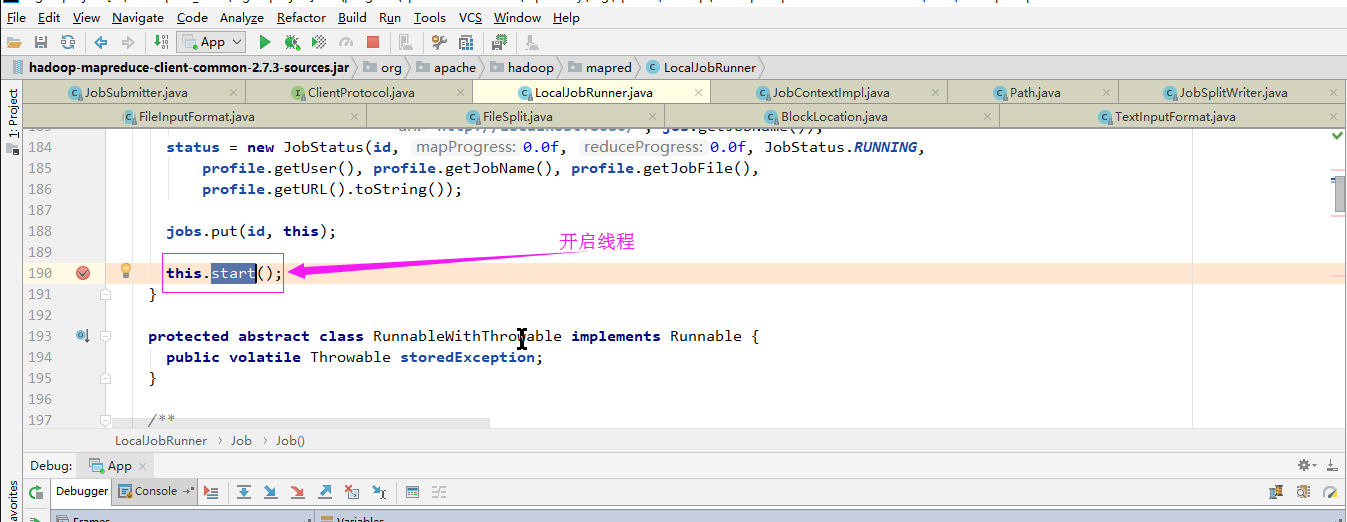
开启线程后会调用run方法:
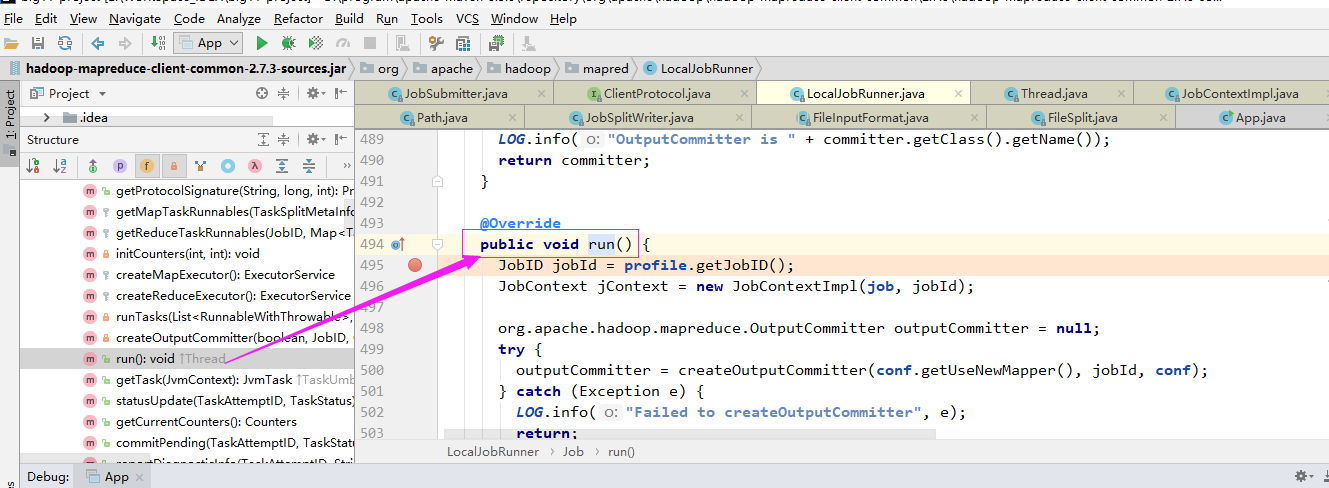
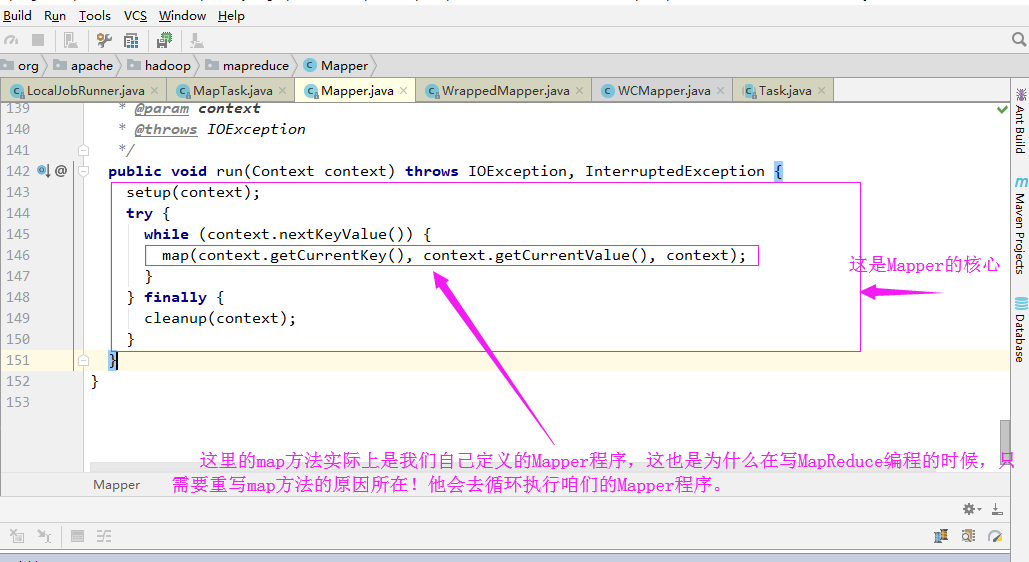
二.Mapper
1>.运行任务
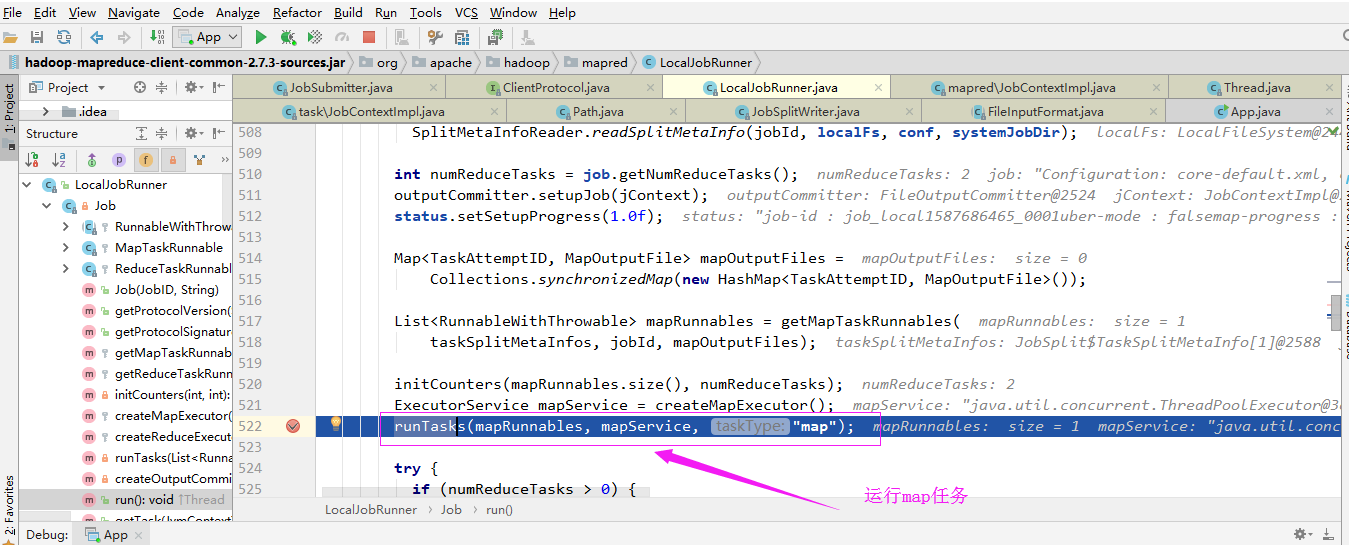
通过“LocalJobRunner$Job$MapTaskRunnable”内部类运行任务:
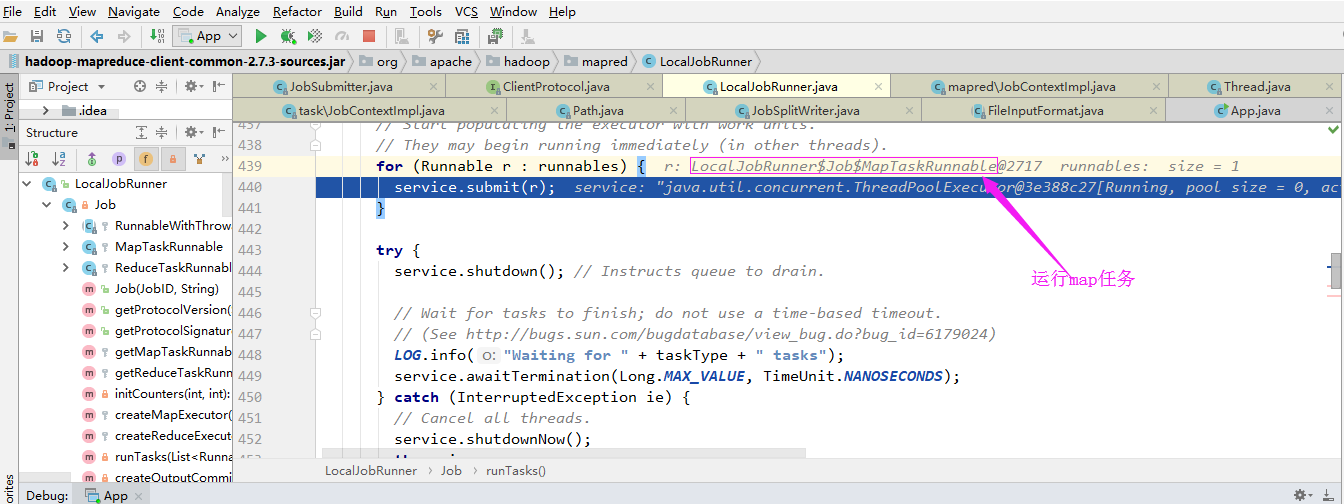
进入maper任务:
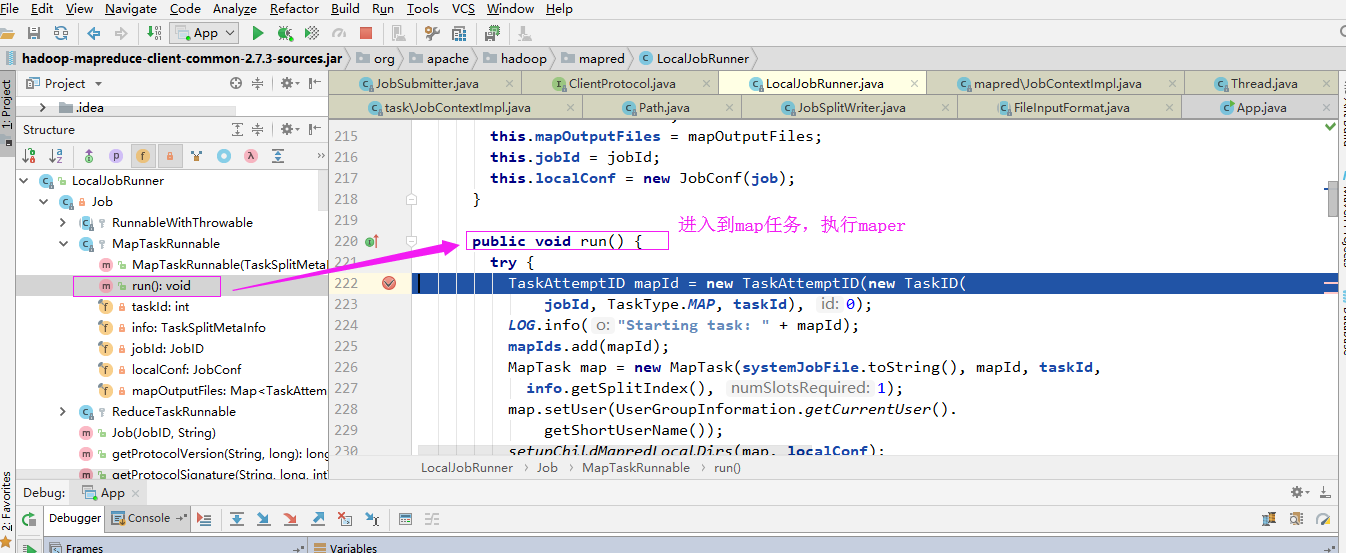
2>.通过反射得到map对象(Map程序是用户在通过“job.setMapperClass”方法设置的)
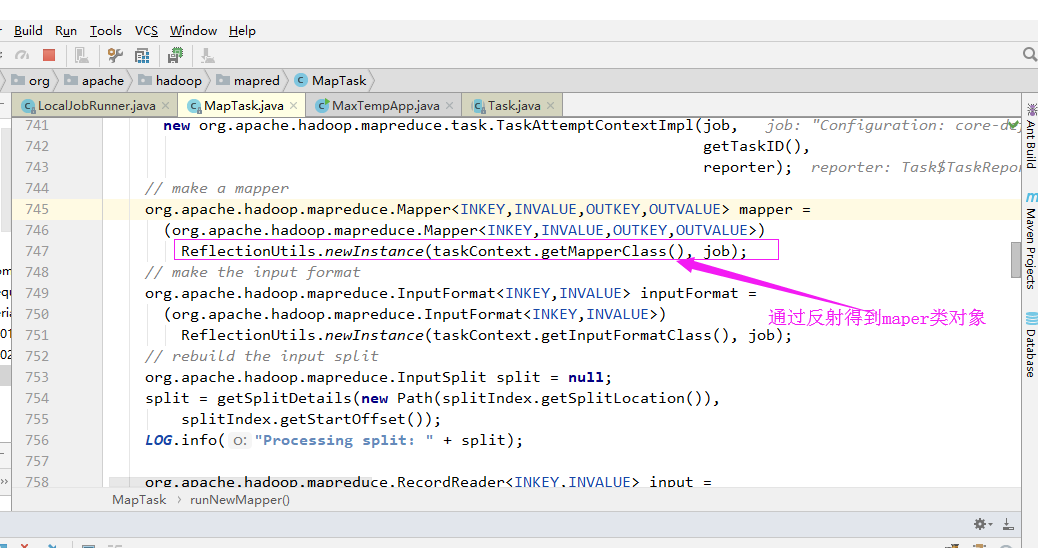
3>.记录阅读器
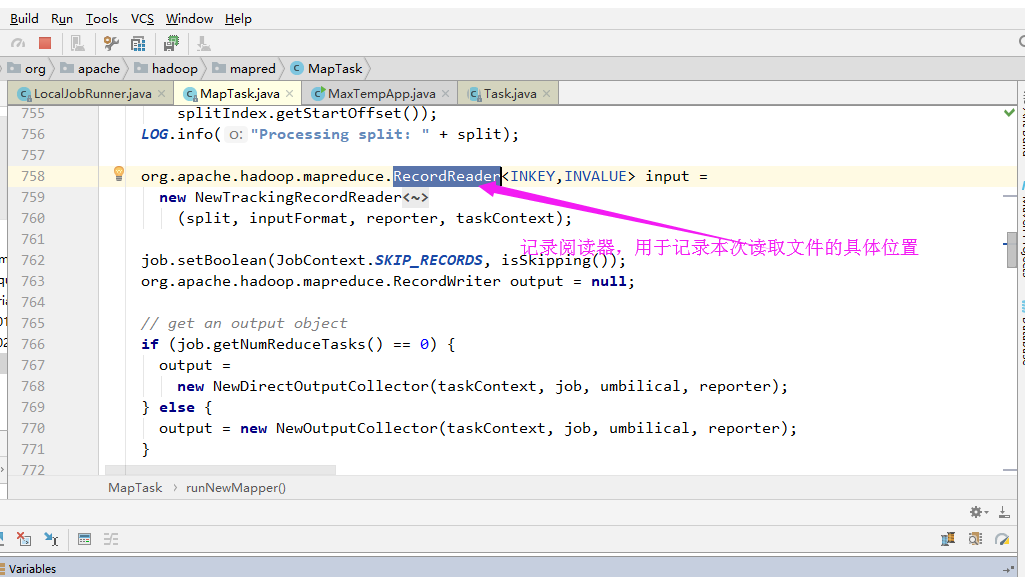
3>.设置输出格式
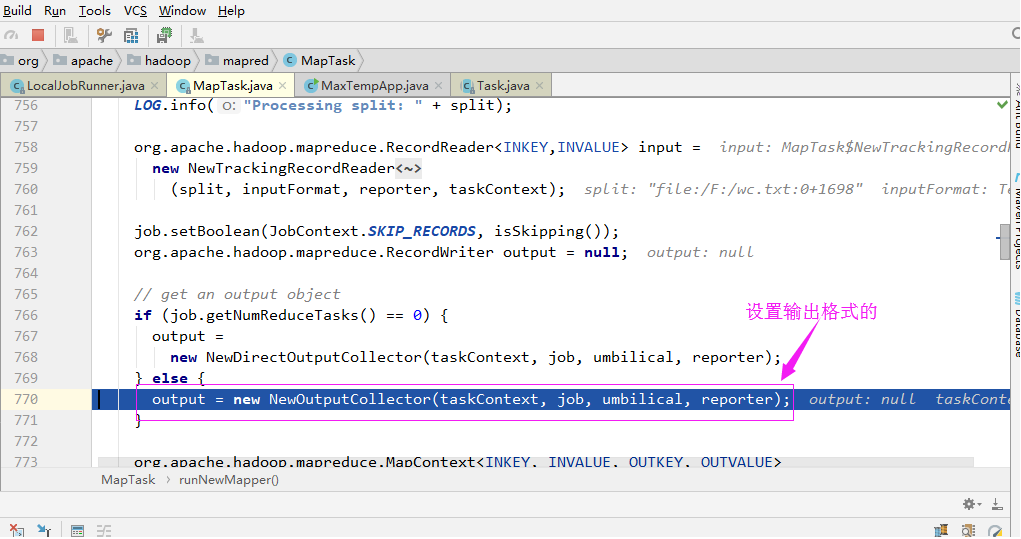
4>.Maper的回调机制
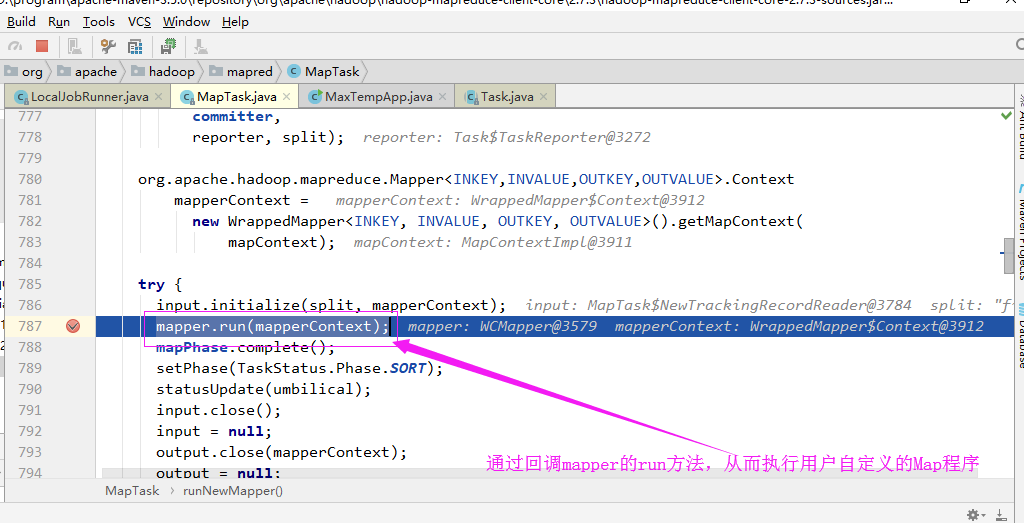
回调函数其实调用的mapper的run方法:
5>.排序阶段
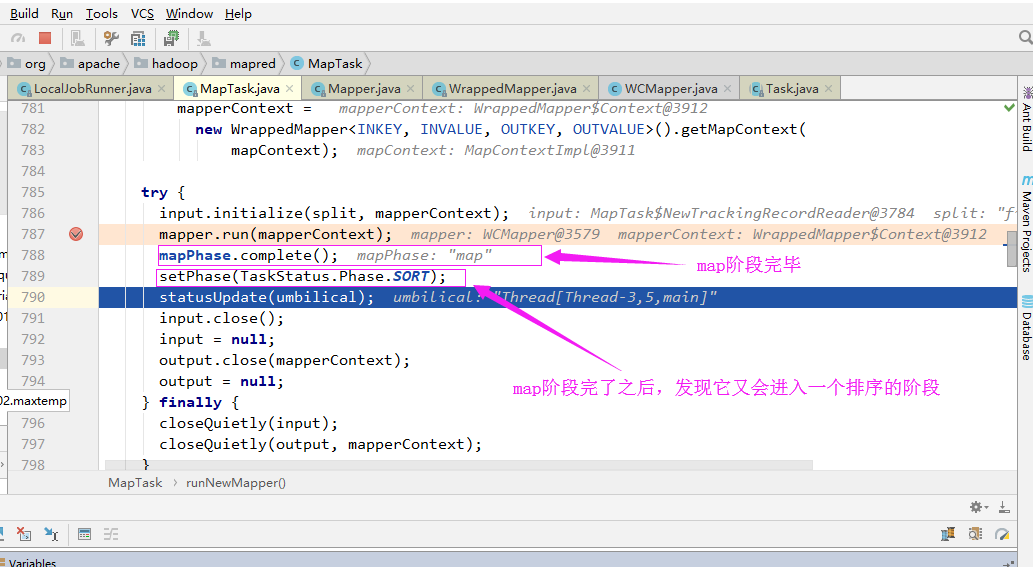
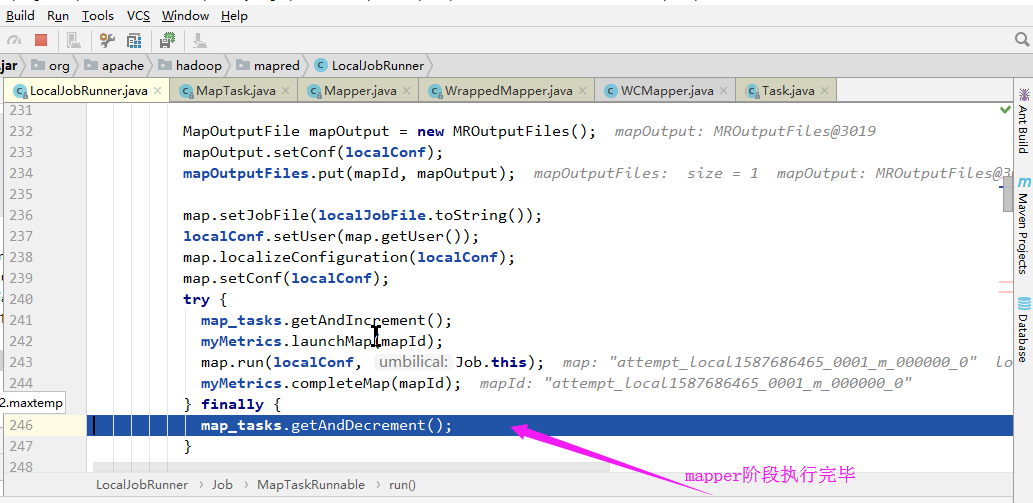
6>.Maper阶段执行结束
三.Reduce
Mapper阶段执行完毕之后,经过shuffle和sort等操作最终会进入到Reduce阶段,而Reduce阶段的实现过程和Mapper类似,它会首先启动一个”LocalJobRunner$Job$ReduceTaskRunnable“的线程,这里就不带截图了。继续打断点调试即可。此部分略过。
四.InputFormat
1>.TextInputFormat

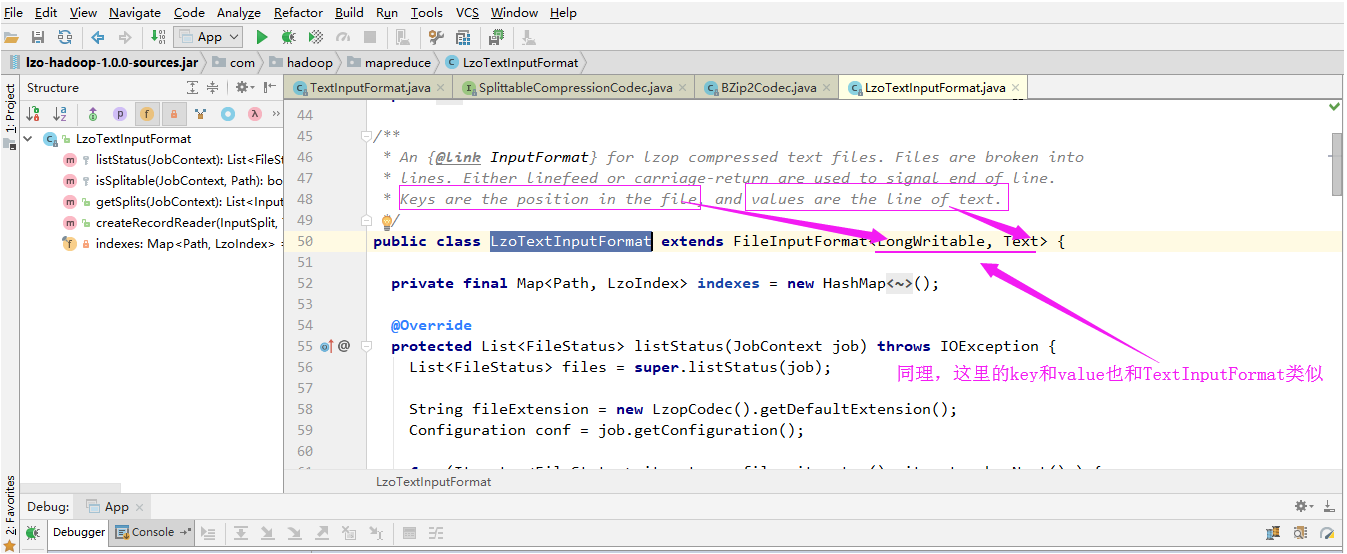
2>.LzoTextInputFormat
3>.读行的类
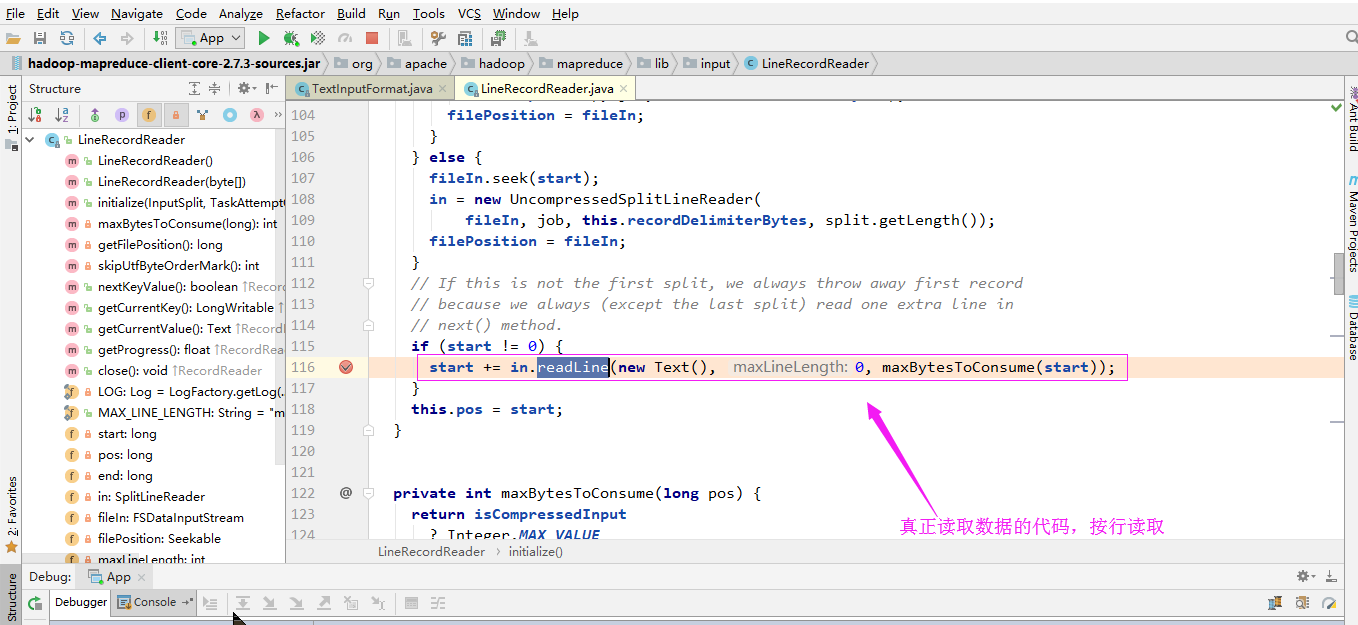
下图是部分调用过程:

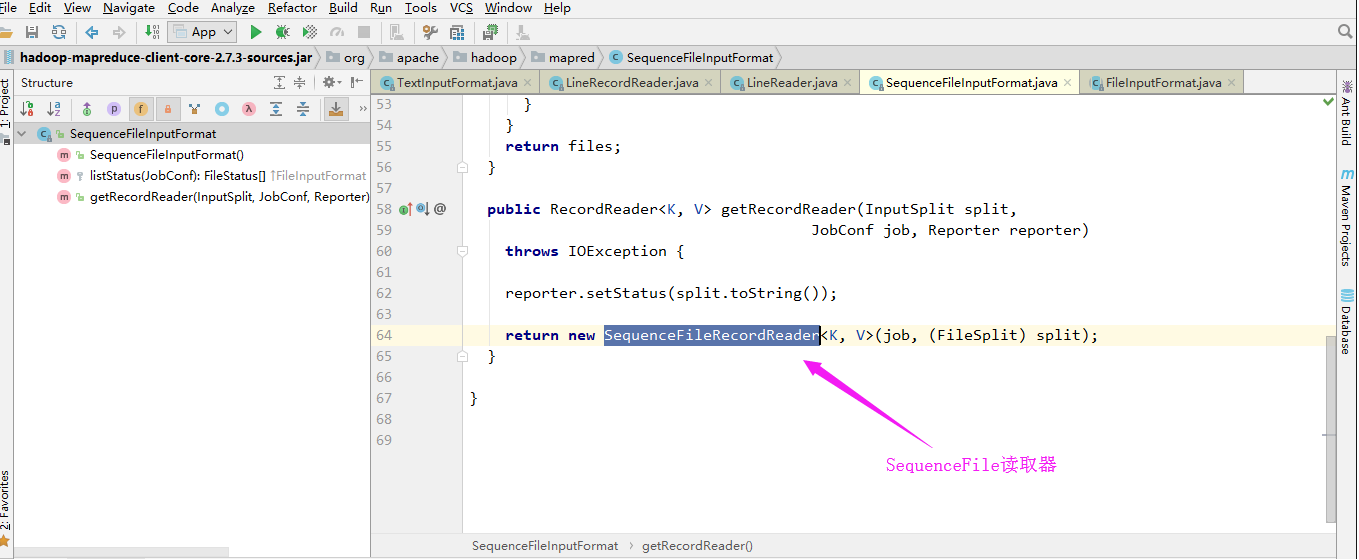
4>.SequenceFileInputFormat
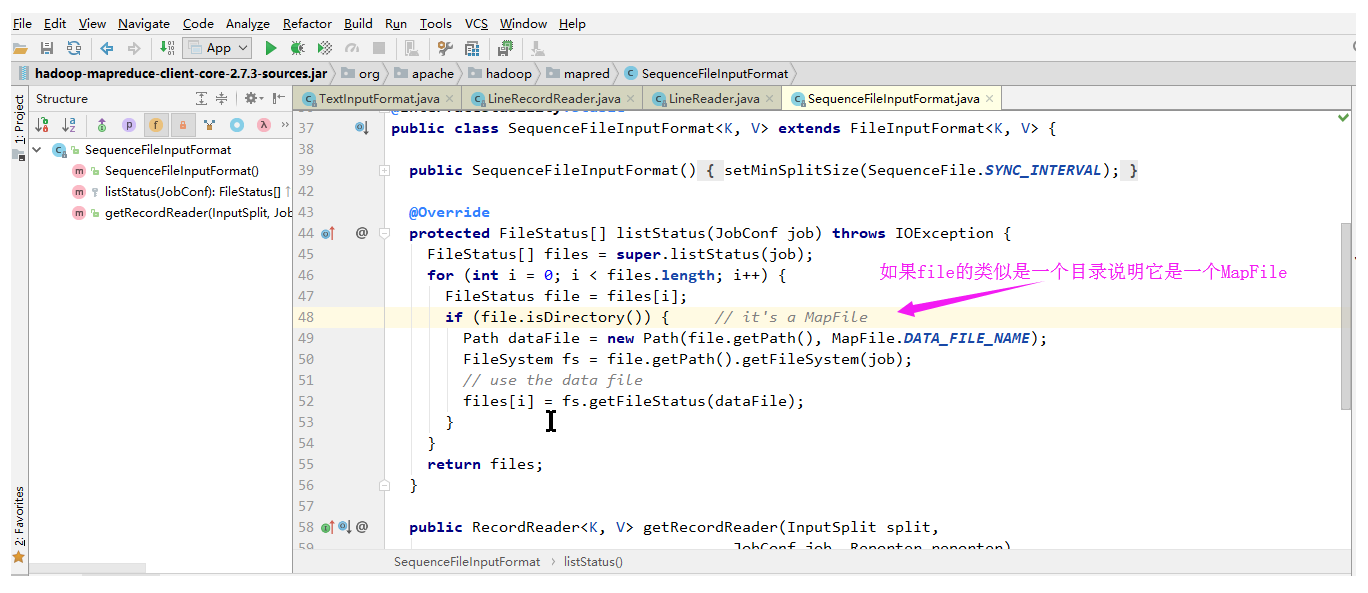
SequenceFileInputFormat是可切割的:

SequenceFile读取器: