分布式结构化存储系统-Kudu简介
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
Hadoop生态系统发展到现在,存储层主要由HDFS和HBase两个系统把持着,一直没有太大突破。在追求高吞吐的批处理场景下,我们选用HDFS;在追求低延迟,有随机读写需求的场景下,我们选用HBase。那么是否存在一种系统,能结合两个系统的优点,同时支持高吞吐率和低延迟呢?Kudu的出现正式为了解决这以难题。
一.Kudu基本特点
Kudu是Cloudera开源的列式存储引擎,专门为了对快速变化的数据进行快速分析,填补了以往Hadoop存储层的空缺。Kudu具有以下几个特点:
(1)C++语言开发;
(2)可以高效处理类OLAP负载;
(3)可以与MapReduce,Spark以及Hadoop生态系统中其他组件进行友好集成;
(4)可与Imapla集成,替代目前Impala常用的HDFS+Parquet组合;
(5)灵活的一致性模型;
(6)顺序写和随机写并存的场景下,仍能达到良好的性能;
(7)高可用,使用Raft协议保证数据高可靠存储;
(8)结构化数据模型;
Kudu的出现,有望解决目前Hadoop生态系统难以解决的一大类问题,比如:
(1)流式实时计算结果的实时更新和查询;
(2)时间序列相关应用,具体要求有:
1)查询海量历史数据;
2)查询个体数据,并要求快速返回;
(3)预测模型中,周期性更新模型,并根据历史数据快速做出决策。
二.Kudu数据模型与架构
kudu是一个强类型的纯列式存储数据库。类似于HBase,Kudu的表是由很多数据子集构成的,表被水平拆分成多个Tablet(类似于HBase的Region),这些Tablet被散布到不同机器上,以实现分布式的存储存储和读写。
Kudu有两种类型的组件:Master Server和Tablet Server。Kudu Master与HBase Master类似,主要功能包括:
(1)负责管理元数据,这些元数据包括Tablet的描述信息及位置信息;
(2)管理Tablet Server,监听Tablet Server的健康状态,一旦发生故障便触发容错;对于副本书过低的Tablet,启动复制任务来提高其副本数。
Master的所有信息都在cache中,因此速度非常快,每次查询都是毫秒级别。Kudu支持多Master,但只有一个Active Master,其余知识作为灾备,不提供服务,一旦Active Master出现故障,其他Master将采用Raft一致性协议重新选举产生新的Active Master。
Table Server用于存储实际的Tablet数据,通常每个Tablet有3个副本存放在不同的Tabale Server。同一个Table的副本分为leader和follower两种类别:每个Tablet只能有一个leader副本,这个副本为用户提供修改操作,然后将修改结果同步给follower;而follower只提供读服务,不提供修改服务;Tablet副本之间使用Raft协议来实现高可用,当leader所在的节点发生故障时,follower会重新选举leader。
三.Kudu与HBase对比
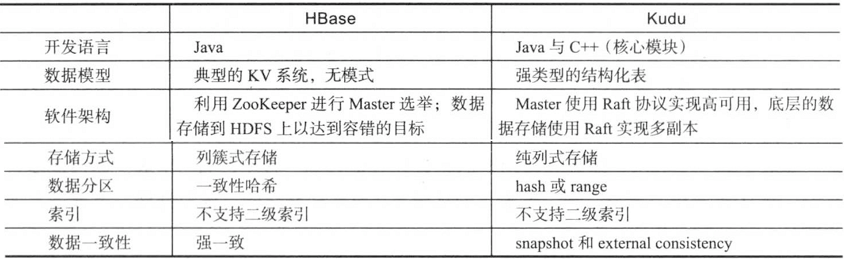
如上图所示,软件架构,存储方式等方面对比了HBase和Kudu。
总结起来,HBase是一个强一致性的KV系统,其扩展性和伸缩性是其最大的有点,通常用于海量数据更新和随机读取的场景;而kudu则是一个实现来多种一致性协议的结构化存储引擎,它通常与Impala结合使用,可用实时OLAP分析(流式导入实时分析)的场景。