为什么要引进基本类型?
java是面向对象语言,那为什么要引入基本类型呢?
主要因为使用基本类型能够在执行效率以及内存使用两方面提升软件性能。
Java 虚拟机的 boolean 类型
在 Java 语言规范中,boolean 类型的值只有两种可能,它们分别用符号“true”和“false”来表示。显然,这两个符号是不能被虚拟机直接使用的。
在 Java 虚拟机规范中,boolean 类型则被映射成 int 类型。具体来说,“true”被映射为整数 1,而“false”被映射为整数 0。这个编码规则约束了 Java 字节码的具体实现。
Java 的基本类型
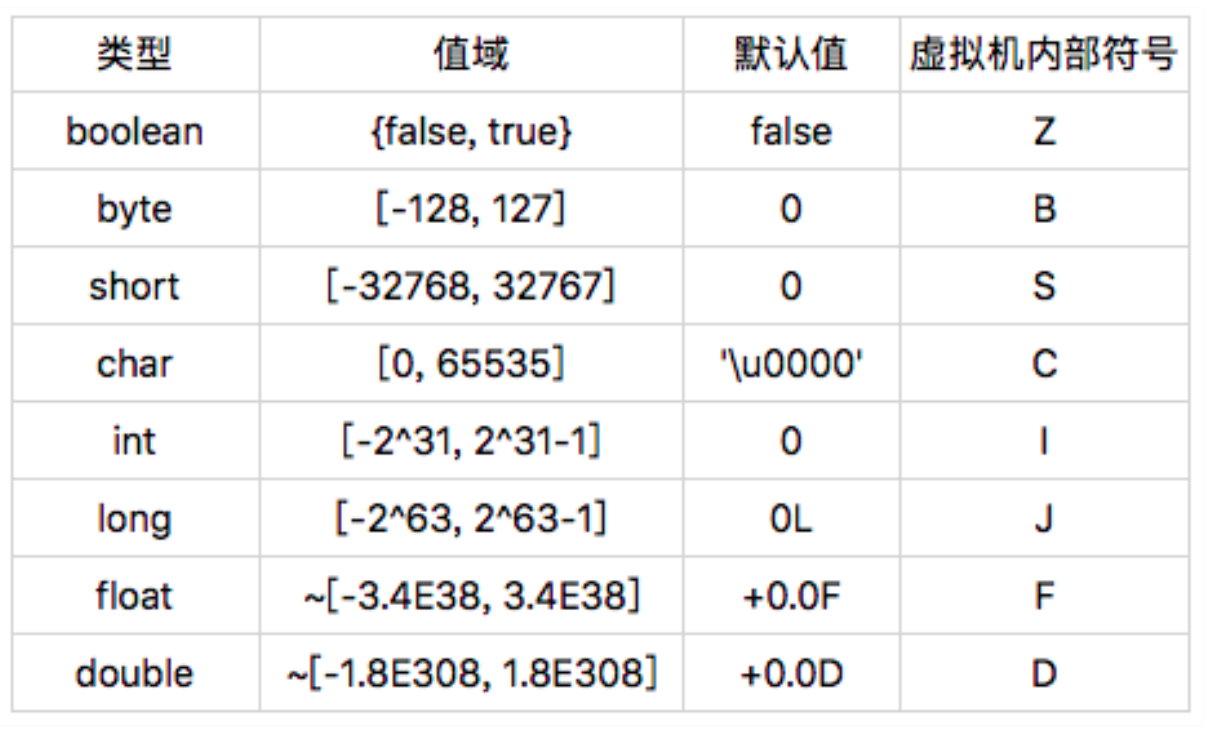
2. Java 基本类型的存储与加载
Java 虚拟机每调用一个 Java 方法,便会创建一个栈帧。为了方便理解,这里我只讨论供解释器使用的解释栈帧(interpreted frame)。
这种栈帧有两个主要的组成部分,分别是局部变量区,以及字节码的操作数栈。这里的局部变量是广义的,除了普遍意义下的局部变量之外,它还包含实例方法的“this 指针”以及方法所接收的参数。
在 Java 虚拟机规范中,局部变量区等价于一个数组,并且可以用正整数来索引。除了 long、double 值需要用两个数组单元来存储之外,其他基本类型以及引用类型的值均占用一个数组单元。
也就是说,boolean、byte、char、short 这四种类型,在栈上占用的空间和 int 是一样的,和引用类型也是一样的。因此,在 32 位的 HotSpot 中,这些类型在栈上将占用 4 个字节;而在 64 位的 HotSpot 中,他们将占 8 个字节。
当然,这种情况仅存在于局部变量,而并不会出现在存储于堆中的字段或者数组元素上。对于 byte、char 以及 short 这三种类型的字段或者数组单元,它们在堆上占用的空间分别为一字节、两字节,以及两字节,也就是说,跟这些类型的值域相吻合。
因此,当我们将一个 int 类型的值,存储到这些类型的字段或数组时,相当于做了一次隐式的掩码操作。举例来说,当我们把 0xFFFFFFFF(-1)存储到一个声明为 char 类型的字段里时,由于该字段仅占两字节,所以高两位的字节便会被截取掉,最终存入“uFFFF”。
boolean 字段和 boolean 数组则比较特殊。在 HotSpot 中,boolean 字段占用一字节,而 boolean 数组则直接用 byte 数组来实现。为了保证堆中的 boolean 值是合法的,HotSpot 在存储时显式地进行掩码操作,也就是说,只取最后一位的值存入 boolean 字段或数组中。
讲完了存储,现在我来讲讲加载。Java 虚拟机的算数运算几乎全部依赖于操作数栈。也就是说,我们需要将堆中的 boolean、byte、char 以及 short 加载到操作数栈上,而后将栈上的值当成 int 类型来运算。
对于 boolean、char 这两个无符号类型来说,加载伴随着零扩展。举个例子,char 的大小为两个字节。在加载时 char 的值会被复制到 int 类型的低二字节,而高二字节则会用 0 来填充。
对于 byte、short 这两个类型来说,加载伴随着符号扩展。举个例子,short 的大小为两个字节。在加载时 short 的值同样会被复制到 int 类型的低二字节。如果该 short 值为非负数,即最高位为 0,那么该 int 类型的值的高二字节会用 0 来填充,否则用 1 来填充。
public class Foo { static boolean boolValue; public static void main(String[] args) { boolValue = true; // 将这个 true 替换为 2 或者 3,再看看打印结果 if (boolValue) System.out.println("Hello, Java!"); if (boolValue == true) System.out.println("Hello, JVM!"); } }
当替换为2的时候无输出
当替换为3的时候打印HelloJava及HelloJVM
猜测是因为将boolean 保存在静态域中,指定了其类型为'Z',当修改为2时取低位最后一位为0,当修改为3时取低位最后一位为1
则说明boolean的掩码处理是取低位的最后一位